






决策树是以实例为基础的归纳学习算法。 它从一组无次序、无规则的元组中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部结点进行属性值的比较,并根据不同的属性值从该结点向下分支,叶结点是要学习划分的类。从根到叶结点的一条路径就对应着一条合取规则,整个决策树就对应着一组析取表达式规则。
一棵决策树由以下3类结点构成:
- 根结点
- 内部结点(决策结点)
- 叶结点
其中,根结点和内部结点都对应着我们要进行分类的属性集中的一个属性,而叶结点是分类中的类标签的集合。如果一棵决策树构建起来,其分类精度满足我们的实际需要,我们就可以使用它来进行分类新的数据集。
这棵决策树就是我们根据已有的训练数据集训练出来的分类模型,可以通过使用测试数据集来对分类模型进行验证,经过调整模型直到达到我们所期望的分类精度,然后就可以使用该模型来预测实际应用中的新数据,对新的数据进行分类。
通过上面描述,我们已经能够感觉出,在构建决策树的过程中,如果选择其中的内部结点(决策结点),才能够使我们的决策树得到较高的分类精度,这是难点。其中,ID3算法主要是给出了通过信息增益的方式来进行决策结点的选择。
首先,看一下如何计算信息熵。熵是不确定性的度量指标,假如事件A的全概率划分是(A1,A2,…,An),每部分发生的概率是(p1,p2,…,pn),那么信息熵通过如下公式计算:
1 | Info(A) = Entropy(p1,p2,...,pn) = -p1 * log2(p1) -p2 * log2(p2) - ... -pn * log2(pn) |
我们以一个很典型被引用过多次的训练数据集D为例,来说明ID3算法如何计算信息增益并选择决策结点,训练集如图所示:
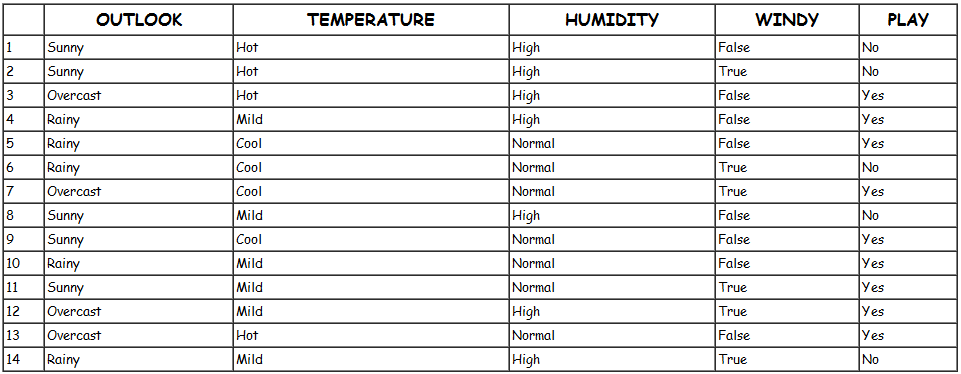
上面的训练集有4个属性,即属性集合A={OUTLOOK, TEMPERATURE, HUMIDITY, WINDY};而类标签有2个,即类标签集合C={Yes, No},分别表示适合户外运动和不适合户外运动,其实是一个二分类问题。
数据集D包含14个训练样本,其中属于类别“Yes”的有9个,属于类别“No”的有5个,则计算其信息熵:
1 | Info(D) = -9/14 * log2(9/14) - 5/14 * log2(5/14) = 0.940 |
下面对属性集中每个属性分别计算信息熵,如下所示:
- OUTLOOK属性
OUTLOOK属性中,有3个取值:Sunny、Overcast和Rainy,样本分布情况如下:
类别为Yes时,Sunny有2个样本;类别为No时,Sunny有3个样本。
类别为Yes时,Overcast有4个样本;类别为No时,Overcast有0个样本。
类别为Yes时,Rainy有3个样本;类别为No时,Rainy有2个样本。
从而可以计算OUTLOOK属性的信息熵:
1 | Info(OUTLOOK) = 5/14 * [- 2/5 * log2(2/5) – 3/5 * log2(3/5)] + 4/14 * [ - 4/4 * log2(4/4) - 0/4 * log2(0/4)] + 5/14 * [ - 3/5 * log2(3/5) – 2/5 * log2(2/5)] = 0.694 |
- TEMPERATURE属性
TEMPERATURE属性中,有3个取值:Hot、Mild和Cool,样本分布情况如下:
类别为Yes时,Hot有2个样本;类别为No时,Hot有2个样本。
类别为Yes时,Mild有4个样本;类别为No时,Mild有2个样本。
类别为Yes时,Cool有3个样本;类别为No时,Cool有1个样本。
1 | Info(TEMPERATURE) = 4/14 * [- 2/4 * log2(2/4) – 2/4 * log2(2/4)] + 6/14 * [ - 4/6 * log2(4/6) - 2/6 * log2(2/6)] + 4/14 * [ - 3/4 * log2(3/4) – 1/4 * log2(1/4)] = 0.911 |
- HUMIDITY属性
TEMPERATURE属性中,有2个取值:High和Normal,样本分布情况如下:
类别为Yes时,High有3个样本;类别为No时,High有4个样本。
类别为Yes时,Normal有6个样本;类别为No时,Normal有1个样本。
1 | Info(HUMIDITY) = 7/14 * [- 3/7 * log2(3/7) – 4/7 * log2(4/7)] + 7/14 * [ - 6/7 * log2(6/7) - 1/7 * log2(1/7)] = 0.789 |
- WINDY属性
WINDY属性中,有2个取值:True和False,样本分布情况如下:
类别为Yes时,True有3个样本;类别为No时,True有3个样本。
类别为Yes时,False有6个样本;类别为No时,False有2个样本。
1 | Info(WINDY) = 6/14 * [- 3/6 * log2(3/6) – 3/6 * log2(3/6)] + 8/14 * [ - 6/8 * log2(6/8) - 2/8 * log2(2/8)] = 0.892 |
根据上面的数据,我们可以计算选择第一个根结点所依赖的信息增益值,计算如下所示:
1 | Gain(OUTLOOK) = Info(D) - Info(OUTLOOK) = 0.940 - 0.694 = 0.246 |
2 | Gain(TEMPERATURE) = Info(D) - Info(TEMPERATURE) = 0.940 - 0.911 = 0.029 |
3 | Gain(HUMIDITY) = Info(D) - Info(HUMIDITY) = 0.940 - 0.789 = 0.151 |
4 | Gain(WINDY) = Info(D) - Info(WINDY) = 0.940 - 0.892 = 0.048 |
根据上面对各个属性的信息增益值进行比较,选出信息增益值最大的属性:
1 | Max(Gain(OUTLOOK), Gain(TEMPERATURE), Gain(HUMIDITY), Gain(WINDY)) = Gain(OUTLOOK) |
所以,第一个根结点我们选择属性OUTLOOK。
继续执行上述信息熵和信息增益的计算,最终能够选出其他的决策结点,从而建立一棵决策树,这就是我们训练出来的分类模型。基于此模型,可以使用一组测试数据及进行模型的验证,最后能够对新数据进行预测。
ID3算法的优点是:算法的理论清晰,方法简单,学习能力较强。
ID3算法的缺点是:只对比较小的数据集有效,且对噪声比较敏感,当训练数据集加大时,决策树可能会随之改变。















 2457
2457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









