







 ID3算法算法流程描述算法流程python实现代码各方法的解释代码数据集介绍训练数据和测试数据划分结果分析分类准确率及决策树优点和缺点改进的算法:C4.5算法CART算法算法流程描述 ID3算法是一种贪心算法,用来构造决策树。它以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。算法流程输入需要分类的数据集和类别标签和靶标签。检验数据集是否只有一列,或者是否最后一列(靶标签数据默认放
ID3算法算法流程描述算法流程python实现代码各方法的解释代码数据集介绍训练数据和测试数据划分结果分析分类准确率及决策树优点和缺点改进的算法:C4.5算法CART算法算法流程描述 ID3算法是一种贪心算法,用来构造决策树。它以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。算法流程输入需要分类的数据集和类别标签和靶标签。检验数据集是否只有一列,或者是否最后一列(靶标签数据默认放
算法流程描述
ID3算法是一种贪心算法,用来构造决策树。它以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
算法流程
- 输入需要分类的数据集和类别标签和靶标签。
- 检验数据集是否只有一列,或者是否最后一列(靶标签数据默认放到最后一列)只有一个水平(唯一值)。是则返回唯一值水平或者占比最大的那个水平。
- 调用信息增益公式,计算所有节点的信息增益,得到最大信息增益所对应的类别标签。
信息熵公式: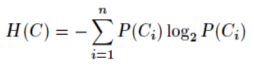
信息增益公式: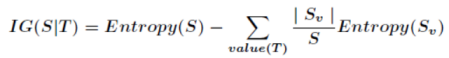
- 建立决策树字典用以保存该次叶节点数据信息。
- 进入循环:按照该类别标签的不同水平,依次计算子数据集;对子数据集重复(1),(2),(3),(4),(5)步。
- 返回决策树字典。
该算法使用python语言实现,最终生成的决策树实际上是一个大的递归函数,其结果是一个多层次的字典。
python实现代码
各方法的解释
LoadDataSet函数用来载入数据。
ID3Tree类中,_best_split用来遍历标签并计算最大信息增益对应的标签;_entropy就是计算熵;_split_dataSet用于切割数据集;_top_amount_level是递归终止条件触发时的返回值。即只有一个特征列的一个level的子集时,如果对应的purchase还有买和不买(level),就返回最大占比的level;mktree主程序,递归生成决策树,并将其保存在tree字典中;predict主程序,用于预测分类;_unit_test,单元测试程序,用于测试上面一些函数。
代码
import numpy as np
import pandas as pd
import json
from divideData import divide_data
# 用于载入数据
class LoadDataSet(object):
def load_dataSet(self):
data = pd.read_csv("./train_ID3data.txt", sep="\t", header=None) # 返回DataFrame类型:二维标记数据结构
data.rename(columns={
0: "age", 1: "income", 2: "student", 3: "reputation", 4: "purchase"}, inplace=True) # 修改列名
return data
class ID3Tree(LoadDataSet):
"""主要的数据结构是pandas对象"""
__count = 0
def __init__(self):
super().__init__()
"""认定最后一列是标签列"""
self.dataSet = self.load_dataSet()
self.gain = {
}
def _entropy(self, dataSet):
"""计算给定数据集的熵"""
labels = list(dataSet.columns) # 获取列名,即属性标签
level_count = dataSet[labels[-1]].value_counts().to_dict() # 统计分类属性标签的各类水平
entropy = 0.0
for key, value in level_count.items(): # 对每一种分类都计算
prob = float(value) / dataSet.shape[0] # 使用某类数量除dataSet.shape[0](行数),即某分类个数/总数
entropy += -prob * np.log2(prob) # 计算信息熵
return entropy # 返回信息熵
def _split_dataSet( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3485
3485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









