






首先,链表是物理储存单元上非连续,非顺序的储存结构,数据元素是通过链表中的指针(在java中为应用,即Reference)链接次序实现的。链表有一系列结点(链表中每个元素称为结点)组成,每个结点包括储存数据的数据域和只想下一个结点的指针域。
那么为什么教授推荐我们使用链表表示呢,主要在于一下几个原因:
链表可以克服需要预先知道数据大小的缺点。(当然,我所设计的stack和queue的array实现都应用了扩展方法,但是这里的问题便是初始化或者扩展大小之后,会存在array内部分域为空值,而浪费内存的情况),链表结构可以充分利用计算机空间,实现相当灵活的内存管理。
其实这一切问题都可以用特殊的结构或者方法来解决,例如循环队列就解决了array对内存处理的部分问题。但是当我们遇到部分问题的时候,这会消耗掉我们大量的时间,并且占用大量的代码行。所以,在必要的时候,使用链表对数据结构进行实现是非常重要的。
这里,给出数组,链表,双向链表的复杂度对比:
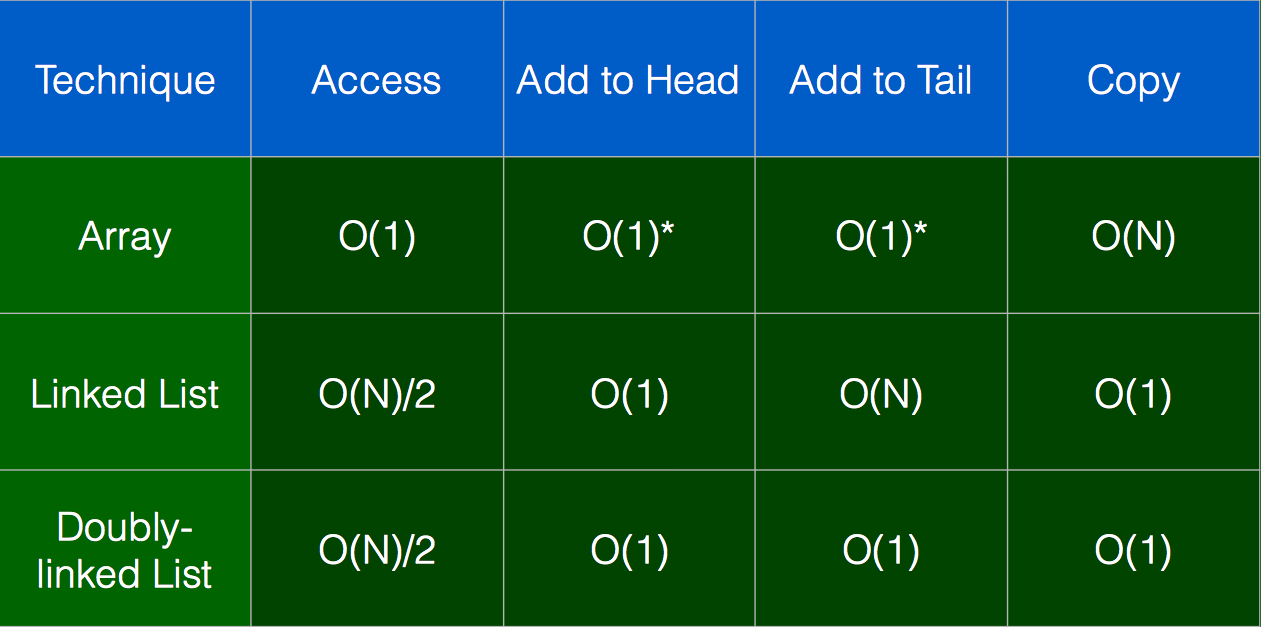
其实在一开始,教授给出的这个图很不能理解的就是链表的Add to Tail复杂度为什么是O(N)???
后来仔细想了一下,这个图单纯的指的LinkedList的Add to Tail,而不是指运用到Stack或者Queue这样有top或者rear标示的数据结构里面。
如果linklist包含了index的话,Add to Tail也不会是O(N)。所以,在仅仅使用链表的时候,我们需要从头遍历一边,判断尾端在哪里,这样才能进行尾插入操纵。
注意!!我们要从头遍历是因为链表的基础结构只有头地址是暴露出来的!而不是尾地址!所以链表的add和remove操作都是对头进行操作的!
当然,如果你喜欢,双向链表绝对是复杂度最低的选择,但是双向链表带来的数据量的增加也是不可避免的。(每一个数据要多两个指针/引用)。
下面对链表类进行实现
package LinkList; public class LinkList<Item>{ public void add(Item item){ Element tail=head; head=new Element(item,tail); } public Item remove(){ Item result=head.item; head=head.next; return result; } public Item getHead(){ return head.item; } public boolean isEmpty(){ return head==null; } private class Element{ Element(Item x,Element n){ item=x; next=n; } final Item item; final Element next; } private Element head=null; }
说实话,教授给的代码很多时候我不太能接受。add函数里面包含了一个tail并不是指的链表尾部,而是加入头后面所跟随的原链表。
这一串代码设计了一个基础的链表,但是这个代码也是让我对链表表示不感冒的地方。每一个链表包含的数据结构和array比起来是扩大了不少。作为一个将内存占用看的比复杂度更重要的人,我个人是不太喜欢使用链表的。当然我也知道,这样会占用程序储存器的更多空间。所以,还是要去习惯这个链表结构啊,因为链表相较于array会大大大大的降低复杂度
这段代码还有一点需要注意。这个LinkList类没有构造器,它没有构造器!!!
当然这不是什么大问题,没有构造器的类如何运行我将会用随笔或者重新开一片文章来具体讲解。(好像之前也有一个坑说要讲Iterator类和接口- -!。我争取这个本周内写完。)
简单来说便是这个类的构造器使用的是super()。即他的超类的构造器。这里不再细讲。
1)实现stack
当然,实现stack也要使用stack接口,具体的接口实现在上一篇已经说出来了。这里还是给出来stack的接口。


public interface Stack<Item> { /** * Update this stack by adding item on the top; * @param Item the item to add; */ void push(Item Item); /** * Update this stack by taking the top item of this stack; * @return this item; * @throws Exception */ Item pop() throws Exception; /** * take the peek at the item on the top of this stack; * @return */ Item peek(); /** * @return true if this stack is empty */ boolean isEmpty(); }
下面来实现这个链表栈:
public class Stack_LinkList<Item> implements Stack<Item> { public Stack_LinkList(){ list=new LinkList<>(); } public void push(Item item){ list.add(item); } public Item pop() throws RuntimeException{ return list.remove(); } public Item peek(){ return list.getHead(); } public boolean isEmpty(){ return list.isEmpty(); } private final LinkList<Item> list; }
这里将pop()抛出的异常定义为RuntimeException。
2)queue实现
对于queue,应为要在队尾插入,队首删除,由上面的复杂度分析表可知,如果使用单链表在队尾插入会导致复杂度为O(N);
在实现队列的时候,并没有将链表作为一个单独的类进行实现,而是将链表的结构直接用queue标示出来。代码如下:
package Queue_Elements; public class Queue_Elements<Item> implements Queue<Item> { public Queue_Elements(){ first=null; last=null; } public void enqueue(Item item){ Element old=last; last=new Element(item,old); if(isEmpty()){ first=last; } else old.next=last; } public Item dequeue(){ Item result=first.item; first=first.next; if(isEmpty()){ last=null; } return result; } public boolean isEmpty(){ return first==null; } private class Element<Item>{ Element(Item item,Element next){ this.item=item; this.next=next; } Item item; Element next; } private Element<Item> first; private Element<Item> last; }
这里,因为对头和尾的地址都有了应用,所以实际上在队列的链表实现中,尾插入和头插入的复杂度都为N(1);但是队列是不能头插入的。所以并没有实现这个方法















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









