







简介:该简介介绍了基于Python的【imdb-movie-scraper】项目,该项目功能是批量抓取IMDb网站上的电影数据,包括标题、导演、演员、评分、简介等信息。文章深入探讨了实现该项目所需的知识点,如网络爬虫原理、HTML和CSS选择器使用、数据存储、异常处理、多线程与异步编程、命令行接口的设计、数据清洗和版本控制。 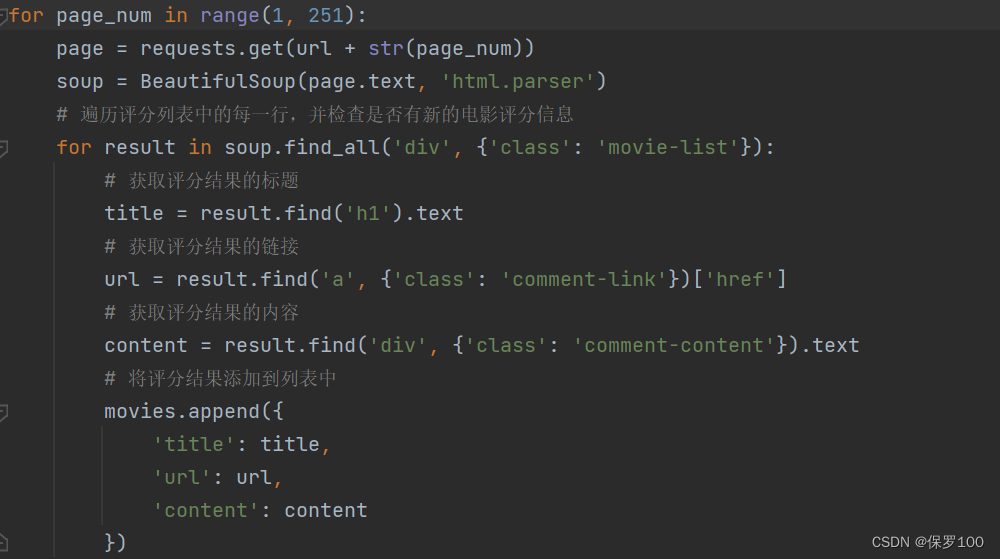
1. 网络爬虫技术的概述与应用
网络爬虫(Web Crawler),又称网络蜘蛛(Spider)或网络机器人(Robot),是一种自动获取网页内容的程序,它按照一定的规则,自动地抓取互联网信息。网络爬虫技术是数据采集技术中的重要组成部分,它在搜索引擎、大数据分析、舆情监控等场景中扮演着至关重要的角色。
1.1 网络爬虫的分类与功能
网络爬虫按照不同的标准可以被划分为不同的类型:
- 按深度划分 :广度优先爬虫和深度优先爬虫。前者从起始URL开始,尽可能先抓取水平链接,再继续抓取垂直链接;后者则一直沿单路径深入直到无法继续为止。
- 按功能划分 :通用爬虫、聚焦爬虫和增量式爬虫。通用爬虫针对整个网站的数据进行抓取;聚焦爬虫主要抓取与预设目标相关的页面;增量式爬虫仅爬取上次爬取后更新或新增的页面内容。
1.2 网络爬虫的应用场景
网络爬虫广泛应用于多个IT相关领域:
- 搜索引擎 :Google、百度等搜索引擎会使用爬虫抓取网页内容,建立索引以提供搜索服务。
- 数据挖掘 :爬虫可以用于获取特定领域的数据,比如社交媒体分析、市场研究等。
- 监控与分析 :公司可利用爬虫监控自身品牌的在线形象,以及分析竞争对手的动态。
在使用网络爬虫时,必须遵守网站的robots.txt协议,尊重数据抓取的合法性、道德性和网站的版权规定。接下来的章节将会详细介绍爬虫技术的深入应用,以及如何使用和优化爬虫技术。
2. 深入掌握BeautifulSoup库
2.1 BeautifulSoup的安装与基本使用
2.1.1 安装BeautifulSoup库
BeautifulSoup库是Python中一个非常流行的网页内容解析库,它允许开发者从HTML或XML文件中提取所需数据。安装BeautifulSoup库是非常简单的,推荐使用pip进行安装。
pip install beautifulsoup4
在安装完成后,可以通过以下Python代码示例来验证安装是否成功,并进行简单的使用:
from bs4 import BeautifulSoup
# 示例HTML内容
html_content = """
<html>
<head>
<title>示例页面</title>
</head>
<body>
<p class="title"><b>标题</b></p>
<p class="content">内容介绍。</p>
</body>
</html>
# 创建BeautifulSoup对象
soup = BeautifulSoup(html_content, 'html.parser')
# 输出页面的title标签内容
print(soup.title.text)
# 输出: 示例页面
2.1.2 解析HTML/XML的基本方法
一旦我们有了BeautifulSoup对象,我们就可以利用这个对象提供的各种方法来遍历、搜索和修改解析树。以下是一些基本方法:
# 查找标签
title_tag = soup.title
print(title_tag.name)
# 输出: title
# 获取标签内的文本
print(title_tag.text)
# 输出: 示例页面
# 查找具有特定类名的元素
content_tag = soup.find(class_='content')
print(content_tag.text)
# 输出: 内容介绍。
# 遍历所有的<b>标签
for b_tag in soup.find_all('b'):
print(b_tag.text)
# 输出: 标题
BeautifulSoup库不仅支持通过标签名、属性名等查找元素,还支持通过CSS选择器进行查找。
2.2 BeautifulSoup进阶解析技巧
2.2.1 高级选择器的应用
BeautifulSoup提供了多种高级选择器,如使用CSS选择器、正则表达式匹配、lambda表达式等。
# 使用CSS选择器
content_tags = soup.select('.content')
for tag in content_tags:
print(tag.text)
# 输出: 内容介绍。
# 使用lambda表达式查找包含特定文本的标签
tags_with_text = soup.find_all(lambda tag: '标题' in tag.text)
for tag in tags_with_text:
print(tag.name)
# 输出: title
2.2.2 数据解析与重构
BeautifulSoup不仅可以解析HTML/XML数据,还可以根据需要对解析的数据进行重构,创建新的标签或修改现有的标签属性和内容。
# 创建新的<b>标签并添加到解析树中
new_b_tag = soup.new_tag('b')
new_b_tag.string = '新标题'
soup.title.append(new_b_tag)
# 输出修改后的title标签内容
print(soup.title)
# 输出: <title>示例页面<b>新标题</b></title>
2.3 BeautifulSoup与其他库的配合
2.3.1 Requests库的协同工作
BeautifulSoup通常与Requests库配合使用,Requests库可以帮助我们发送HTTP请求,并获取网页内容。以下是如何将两者结合的示例:
import requests
from bs4 import BeautifulSoup
# 发送GET请求获取网页内容
response = requests.get('http://example.com')
response.encoding = response.apparent_encoding
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找页面中所有的链接
for link in soup.find_all('a'):
print(link.get('href'))
2.3.2 lxml解析器的性能对比
lxml是一个高性能的XML和HTML解析库,它比BeautifulSoup自带的解析器更加高效。对于处理大型文档或需要高性能的应用,使用lxml会更加合适。
from bs4 import BeautifulSoup
# 使用lxml作为解析器
soup = BeautifulSoup(html_content, 'lxml')
# 同样的查找操作
title_tag = soup.title
print(title_tag.text)
在性能测试中,lxml通常比默认的html.parser快得多。因此,在项目中选择合适的解析器对性能有显著的影响。
接下来的章节会继续深入探讨数据存储与预处理技术,以及爬虫的异常处理和优化。
3. 数据存储与预处理技术
3.1 数据存储技术
3.1.1 数据存储格式的选择:CSV,Excel,SQL数据库
在爬虫项目中,选择合适的数据存储格式对于数据的后期处理和分析至关重要。常见的存储格式包括CSV,Excel和SQL数据库。每种存储方式都有其特定的应用场景和优势。
-
CSV(逗号分隔值) : 这是最简单的文本格式,适用于轻量级的数据存储。CSV文件易于生成和编辑,可以被大多数文本编辑器打开,并且几乎所有的编程语言都能够轻松地读取和写入CSV文件。但是,它缺乏数据类型信息和结构化查询能力。
-
Excel : Excel是广泛使用的电子表格程序,支持各种数据类型,并提供丰富的数据分析和可视化工具。它适合于小型到中型数据集,尤其是当需要进行复杂的计算或图表展示时。不过,Excel在处理大量数据时可能会变得效率低下。
-
SQL数据库 : 对于需要进行复杂查询、多表关联或大量数据存储的场景,SQL数据库(如MySQL, PostgreSQL等)是更好的选择。它提供了强大的数据存储、查询、事务处理和备份恢复等能力。但是,对于简单的数据抓取任务,使用SQL数据库可能会显得过于复杂。
根据项目的具体需求和预期的数据量,选择最合适的存储格式是数据预处理的第一步。
代码块展示:使用Python存储数据到CSV文件
import csv
# 数据列表,每个元素是一个字典,对应于CSV文件的一行
data = [
{'name': 'Tom', 'age': 25, 'city': 'New York'},
{'name': 'Alice', 'age': 22, 'city': 'Los Angeles'},
# ... 更多数据
]
# 写入CSV文件
with open('data.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
writer.writeheader()
for entry in data:
writer.writerow(entry)
在上述代码中,我们创建了一个CSV文件,并写入了一些示例数据。 csv.DictWriter 用于方便地将字典写入到CSV文件中。这段代码展示了如何在Python中实现数据的CSV格式化和存储。
3.1.2 数据持久化策略
数据持久化是指将数据以某种格式存储在非易失性存储介质中,以便长期保存。在爬虫项目中,数据持久化的策略包括:
- 定期备份 : 在爬取大量数据时,定期备份数据可以防止数据丢失。
- 数据分批存储 : 将数据分批存储可以减少单次操作的复杂度,并提高系统的稳定性。
- 使用数据库事务 : 在使用数据库存储数据时,利用事务来保证数据的一致性和完整性。
- 冗余存储 : 在不同的物理位置存储相同的数据,可以在发生故障时保证数据的可靠性。
选择合适的持久化策略可以确保数据的安全性和可用性,并为数据的长期维护和管理提供保障。
3.2 数据清洗与预处理方法
3.2.1 数据清洗的基本原则
数据清洗是数据预处理中的关键步骤,目的是提高数据质量,确保后续分析的准确性。数据清洗的基本原则包括:
- 去除重复项 : 重复数据可能会干扰数据分析的结果。
- 处理缺失值 : 缺失值可以被删除、填充或用特定值代替。
- 纠正错误 : 数据中的错误可能是由于输入错误、爬虫问题或数据源的问题造成的,需要纠正这些错误。
- 格式标准化 : 不一致的数据格式应该统一,如日期、数字和文本格式等。
3.2.2 预处理步骤的实施
数据预处理步骤包括:
- 数据识别 : 确定哪些数据需要清洗。
- 数据清洗工具选择 : 根据数据的特点和需求选择合适的工具或脚本。
- 执行数据清洗 : 对数据进行实际的清洗操作。
- 验证清洗结果 : 清洗完成后,需要验证数据是否已经满足预处理的目标。
例如,使用Python进行数据预处理的代码示例如下:
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 去除重复项
df.drop_duplicates(inplace=True)
# 处理缺失值
df.fillna('Unknown', inplace=True)
# 格式标准化
df['date'] = pd.to_datetime(df['date'], errors='coerce')
# 验证清洗结果
print(df.head())
上述代码展示了使用Pandas库对CSV文件中的数据进行清洗的基本过程。Pandas提供了强大的数据处理功能,能够有效地进行数据清洗和预处理。
4. 爬虫的异常处理与优化
4.1 异常处理机制的构建
在编写网络爬虫时,网络请求可能会因为多种原因失败,例如网络波动、目标网站的反爬虫策略、代码中的逻辑错误等。因此,构建一个健壮的异常处理机制是至关重要的。
4.1.1 爬虫中常见异常的识别与捕获
爬虫中常见的异常可以分为以下几类:
- 网络请求异常 :网络连接失败、超时等。
- 解析异常 :解析库无法识别的HTML结构,或者数据提取规则不匹配。
- 数据处理异常 :数据存储过程中出现的问题,如数据库连接失败等。
- 反爬虫机制异常 :目标网站采取的反爬虫措施,如验证码、动态令牌等。
代码块示例:
import requests
from bs4 import BeautifulSoup
try:
response = requests.get(url)
response.raise_for_status() # 如果响应状态码表示出错,则抛出HTTPError异常
soup = BeautifulSoup(response.text, 'html.parser')
except requests.exceptions.HTTPError as errh:
print(f"Http Error: {errh}")
except requests.exceptions.ConnectionError as errc:
print(f"Error Connecting: {errc}")
except requests.exceptions.Timeout as errt:
print(f"Timeout Error: {errt}")
except requests.exceptions.RequestException as err:
print(f"OOps: Something Else: {err}")
在上述代码中, requests.get() 方法用于发起一个GET请求, response.raise_for_status() 会检查HTTP响应的状态码,如果响应成功,则返回响应内容;如果响应状态码表示出错,则抛出一个HTTPError异常。随后,使用不同的except子句捕获不同类型的异常。
4.1.2 异常处理的最佳实践
在处理异常时,应遵循以下最佳实践:
- 不要捕获你不处理的异常 :确保只捕获那些你能够妥善处理的异常。
- 记录异常信息 :将异常信息写入日志文件,以便事后分析和调试。
- 避免异常覆盖 :避免使用一个通用的except块来捕获所有异常,这会导致在调试时失去异常的具体信息。
- 重试机制 :对于临时的网络问题或目标服务器的暂时性故障,可以通过实现重试机制来增加爬虫的稳定性。
代码块示例:
import logging
from time import sleep
logger = logging.getLogger(__name__)
def fetch_data(url):
max_retries = 3
for i in range(max_retries):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logger.exception(f"Retrying for error: {e}")
sleep(2 ** i) # 简单的指数退避策略
# 调用函数时
try:
data = fetch_data("http://example.com")
except Exception as e:
logger.error(f"Failed to fetch data: {e}")
在该代码块中, fetch_data 函数会尝试最多 max_retries 次来获取给定URL的页面内容。如果在尝试过程中遇到请求异常,异常将被记录,并且会根据指数退避策略进行等待后重试。如果多次重试失败,异常将通过调用函数时的外部异常处理器报告出来。
4.2 多线程与异步IO技术
为了提高爬虫的效率,常常会用到多线程或多进程技术,以及异步IO技术(asyncio)。
4.2.1 多线程在爬虫中的应用
多线程可以让爬虫同时进行多个网络请求,提高程序的执行效率。Python中的 threading 模块可以用于实现多线程爬虫。
代码块示例:
import threading
import requests
def fetch_page(url):
try:
response = requests.get(url)
response.raise_for_status()
print(f"Page content of {url} successfully fetched")
except requests.exceptions.RequestException as e:
print(f"Failed to fetch {url}: {e}")
urls = ["http://example.com/page1", "http://example.com/page2", ...]
threads = []
for url in urls:
thread = threading.Thread(target=fetch_page, args=(url,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
上述代码展示了如何创建多个线程,每个线程都负责对不同的URL发起请求。
4.2.2 异步IO技术(asyncio)的原理与应用
asyncio 是Python 3.4版本引入的标准库,它提供了对异步IO的支持。与多线程相比,异步IO不会创建额外的线程,从而减少了线程切换的开销,尤其适合I/O密集型程序。
代码块示例:
import asyncio
import aiohttp
async def fetch_data(session, url):
async with session.get(url) as response:
return await response.text()
async def main(urls):
async with aiohttp.ClientSession() as session:
tasks = []
for url in urls:
task = asyncio.ensure_future(fetch_data(session, url))
tasks.append(task)
return await asyncio.gather(*tasks)
urls = ["http://example.com/page1", "http://example.com/page2", ...]
results = asyncio.run(main(urls))
在这个异步爬虫的示例中,我们首先定义了一个异步函数 fetch_data ,它接受一个 aiohttp 的会话对象和一个URL,然后发起异步的GET请求,并返回页面内容。然后在 main 函数中,我们创建了一个 ClientSession ,并为每个URL创建了一个异步任务,最后使用 asyncio.gather 来并行处理所有的任务。
通过结合使用 asyncio 和 aiohttp ,可以实现高效的异步网络请求,从而提升爬虫的性能。
请注意,上述代码仅作为示例,实际编写时应添加必要的异常处理逻辑。
5. 爬虫的高级功能实现
5.1 命令行接口的设计与实现
5.1.1 命令行接口的意义与设计原则
命令行接口(CLI)为用户提供了一个通过命令行输入来控制程序执行的界面。对于网络爬虫项目,CLI的存在意义重大,因为它使得用户能够方便地通过命令行参数定制爬虫行为,如设定目标URL、请求头、请求间隔、处理方式等。此外,CLI也使得爬虫的自动化运行和集成到其他系统变得更加容易。
设计CLI时需要考虑几个关键点:
- 用户友好性: 无论CLI多么强大,它都应该易于理解,避免复杂的命令结构。
- 灵活性: CLI应该允许用户可以灵活地提供参数,同时对于非必需参数能够有合理的默认值。
- 可扩展性: 在设计时就应该考虑未来可能的功能扩展,避免后期重构的需要。
- 错误处理: 程序应该能够友好地处理用户输入的错误,并给出明确的提示信息。
5.1.2 使用argparse库构建强大的命令行接口
Python的argparse库是构建命令行接口的常用工具,它可以帮助我们轻松创建用户友好的命令行界面。以下是一个简单的例子,说明如何使用argparse来构建一个爬虫项目的CLI。
首先,我们需要导入argparse库,并创建一个ArgumentParser对象:
import argparse
def main():
parser = argparse.ArgumentParser(description='My Web Crawler')
parser.add_argument('url', type=str, help='The URL to start crawling.')
parser.add_argument('-p', '--proxy', type=str, help='The proxy to be used for the requests.')
parser.add_argument('-o', '--output', type=str, default='output.csv', help='The file to save the results.')
parser.add_argument('--depth', type=int, default=1, help='The maximum depth for crawling.')
args = parser.parse_args()
# The rest of the crawler code goes here...
# ...
在这个例子中,我们定义了四个参数:
-
url是一个必需的参数,用于设定爬虫开始爬取的URL。 -
--proxy是一个可选参数,允许用户指定用于请求的代理。 -
--output是一个可选参数,有默认值output.csv,用于指定爬取结果的保存路径。 -
--depth用于设定爬虫可以爬取的最大深度。
使用argparse时,每个参数都需要一个帮助信息,这样用户在使用 --help 参数时能够获得清晰的指导。
最终,这个简单的设计允许用户通过命令行以如下方式运行爬虫:
python crawler.py http://example.com --depth 3 -p 127.0.0.1:8080 --output results.txt
这段命令指定了爬虫的起始URL,最大爬取深度为3,使用了代理 127.0.0.1:8080 ,并将结果保存在 results.txt 文件中。
CLI的加入使得爬虫的使用更加灵活和强大,同时保持了操作的简洁性。开发者还可以根据需要添加更多的参数,以提供更丰富的功能。
5.2 版本控制系统运用
5.2.1 版本控制系统(Git)的基本使用
版本控制系统是软件开发中不可或缺的工具,它帮助开发者管理源代码的变更历史,并允许团队协作开发。Git是一个广泛使用的分布式版本控制系统,其强大的功能和灵活性使其成为IT行业标准。
Git基础概念
- 提交(Commit) :Git中的基本单位,是你的更改被保存的一个快照。
- 仓库(Repository) :存储所有版本信息的数据库,通常位于项目的根目录下,名
.git。 - 分支(Branch) :允许你从主线上分离出来,并且可以独立工作。
- 合并(Merge) :将分支的更改集成到主线或其他分支上。
- 克隆(Clone) :复制远程仓库到本地的过程。
常用Git命令
-
初始化仓库 :
bash git init这个命令将创建一个空的Git仓库或重新初始化一个已经存在的仓库。 -
添加文件到暂存区 :
bash git add .这个命令会将所有更改过的文件添加到暂存区。 -
提交更改 :
bash git commit -m "Initial commit"使用commit命令将暂存区的更改提交到仓库,并添加一条提交信息。 -
查看状态 :
bash git status这个命令用于查看工作目录和暂存区的状态。 -
查看提交历史 :
bash git log这个命令用于查看提交历史。 -
分支操作 :
bash git branch git checkout -b new-branchbranch命令用于列出所有分支,checkout命令用于切换分支或创建新分支。
基本的Git工作流
在实际的开发过程中,一个基本的Git工作流包括以下步骤:
-
更新本地仓库与远程仓库:
bash git pull origin master这个命令会拉取远程仓库的最新更改。 -
创建新分支进行开发:
bash git checkout -b new-feature开发新的功能或修复bug。 -
将更改添加到暂存区并提交:
bash git add . git commit -m "Implement new feature" -
将更改推送到远程仓库:
bash git push origin new-feature你的更改现在在远程的new-feature分支上了。 -
创建合并请求(Merge Request)或拉取请求(Pull Request)以请求合并: 在大多数远程Git仓库托管服务(如GitHub或GitLab)中,这个过程通过图形界面完成。
5.2.2 Git在爬虫项目管理中的应用
在爬虫项目中使用Git不仅可以帮助你管理代码,还可以跟踪更改、处理冲突和与他人协作。为了有效地使用Git进行项目管理,你可以遵循如下实践:
- 经常提交 :定期提交你的更改,这样可以在出错时轻松回滚。
- 有意义的提交信息 :编写简洁明了的提交信息,这有助于其他开发者理解每次提交的目的。
- 分支管理 :为每个功能、修复或实验创建分支,这样可以保持主分支的稳定性。
- Pull Requests :在合并到主分支之前,通过Pull Requests进行代码审查。
- 使用标签(Tagging) :为重要的版本打标签,如v1.0、v2.0等。
在爬虫项目中,由于爬取的数据可能不断变化,因此可以使用Git的子模块(Submodules)特性,将特定版本的数据存储在仓库中,从而固定数据版本。
此外,对于依赖特定数据集或配置的复杂爬虫,可以考虑使用Git Large File Storage(LFS)来管理较大的数据文件。
在团队协作时,建议采用明确的分支策略,例如Git Flow或GitHub Flow,以确保项目能够顺畅发展。
通过上述Git实践,不仅可以提升爬虫项目的代码质量,还可以提高团队协作的效率,使项目更加可持续地发展。
6. 实践项目:imdb-movie-scraper
6.1 项目规划与需求分析
6.1.1 确定项目目标与功能范围
在开始编码之前,明确项目的目标至关重要。对于本项目 imdb-movie-scraper ,我们的目标是创建一个能够从IMDb网站抓取电影数据的网络爬虫。这一项目旨在帮助用户获取IMDb上关于电影的详细信息,如电影名称、导演、演员、评分、剧情简介和评论等。
功能范围的设定应考虑以下几点:
- 信息抓取 :确定需要爬取的电影数据字段。
- 数据组织 :数据如何组织和存储,例如是否需要保存为数据库或某种文件格式。
- 接口设计 :是否需要提供接口供其他应用程序使用爬取的数据。
- 异常处理 :如何处理网站结构变化、网络请求错误等异常情况。
6.1.2 数据需求与目标网站分析
在了解了项目目标后,我们需要分析目标网站IMDb的结构,以便确定如何抓取所需的数据。IMDb网站对自动化访问有限制,因此我们需要特别注意爬虫的访问频率和IP变化。
- 页面结构分析 :通过浏览器的开发者工具,我们可以查看网页源代码和元素结构,理解数据是如何在页面中展示的。
- 数据定位 :识别出电影信息在HTML中的位置,如电影名通常位于
<td class="titleColumn">标签内。 - API使用 :鉴于直接爬取可能面临的技术挑战,可以考虑使用IMDb提供的API进行数据获取,尽管这可能需要API密钥和更复杂的认证流程。
6.2 爬虫的开发与实施
6.2.1 爬虫代码的编写与测试
在确定了项目目标和需求后,可以开始编写爬虫代码。我们将使用 requests 库来处理HTTP请求, BeautifulSoup 进行HTML内容解析,以及 pandas 库来管理数据。
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 伪代码示例
def scrape_movie_info(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 伪代码:从页面中提取电影信息
movie_info = {}
movie_info['title'] = soup.find(...).get_text()
# 更多数据抓取逻辑...
return movie_info
return None
# 测试爬虫函数
url = 'https://www.imdb.com/title/tt0111161/'
movie_info = scrape_movie_info(url)
if movie_info:
print(movie_info)
6.2.2 功能实现与效果评估
编写爬虫代码的同时,我们需要考虑数据提取的准确性和代码的健壮性。功能实现后,应该进行以下评估:
- 功能完整性 :验证爬虫是否能够抓取到所有预定的数据项。
- 性能表现 :测试爬虫在不同网络条件和负载情况下的表现。
- 错误处理 :确保爬虫能够妥善处理目标网站的异常响应,如404错误或5XX服务器错误。
评估可以通过编写单元测试和集成测试来实现。使用 unittest 或 pytest 库可以方便地对爬虫功能进行测试。
6.3 项目总结与展望
6.3.1 成果回顾与经验分享
项目完成后,应回顾整个开发过程中的亮点和问题,以及如何解决这些问题。例如,我们可能发现IMDb网站的某些页面结构难以通过传统方法解析,因此采用了XPath或CSS选择器。成功应对这些挑战的经验,可以为未来类似的爬虫项目提供宝贵的参考。
6.3.2 项目改进与未来方向
尽管 imdb-movie-scraper 项目在功能上可能已经满足基本需求,但仍有改进空间。例如,可以引入自动化测试和持续集成来提高代码质量,或者使用更高级的数据存储和分析技术,如NoSQL数据库和数据可视化工具。
此外,考虑到法律和道德因素,未来的方向可能包括:
- 遵守法律 :确保爬虫行为遵守相关法律法规,尊重目标网站的版权和使用条款。
- 用户贡献 :建立平台让用户提交他们想要爬取的电影信息,让爬虫更加人性化。
- 数据共享 :在保证隐私的前提下,提供数据共享机制,促进数据资源的开放和共享。
简介:该简介介绍了基于Python的【imdb-movie-scraper】项目,该项目功能是批量抓取IMDb网站上的电影数据,包括标题、导演、演员、评分、简介等信息。文章深入探讨了实现该项目所需的知识点,如网络爬虫原理、HTML和CSS选择器使用、数据存储、异常处理、多线程与异步编程、命令行接口的设计、数据清洗和版本控制。

















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









