



 本文详细介绍了如何将WPS Office的ET文件转换为PDF格式,包括使用PDF转换器的具体步骤,适合需要处理ET文件但更偏好PDF格式的用户。
本文详细介绍了如何将WPS Office的ET文件转换为PDF格式,包括使用PDF转换器的具体步骤,适合需要处理ET文件但更偏好PDF格式的用户。
et文件什么格式呢?可能对于大部分工作的人来说,都遇见过它,但是很少人注意到这一点。在处理到et文件的时候,介于某种原因需要你将et格式的文件转成PDF格式,那我们该如何解决呢?不会的伙伴可以看看下面小编是如何操作的!
一:什么是et文件
1:et文件是属于办公软件WPS office中的电子表格文件。et文件就相当于微软办公软件office的excel表格一样。可以用excel打开它,也可以下载安装WPS Office就能打开它。
二:et格式转成PDF操作方法
1:在转换文件格式之前,我们可以将转换格式的et文件保存在一个文件夹里面,这一步大家可以选择跳过,小编纯粹是为了方便后面的操作。
2:如果大家电脑中有PDF转换器就很容易操作了,可以直接打开软件进入到操作页面。电脑中没有的可以进入到百度浏览器搜索相关软件进行安装。
3:从上面也知道et是WPS文件一种后缀,在这里就可以选择到【WPS文件转换】这个栏目,然后点击打开这个栏目可以选择到【文件转PDF】其中就包括了WPS、et、dps、三种格式。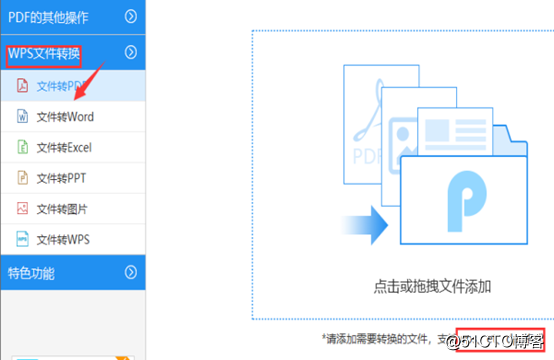
4:下一步就可以将刚开始保存在文件夹中的et文件添加到右侧的转换框中,当然也可以直接拖拽这个文件到转换框中。

5:et文件添加成功后,在软件上方可以看到【输出目录】的字样,在这里可以设置文件的保存路径,有自定义和原文件夹两个选项。可以根据自己的需求进行设置。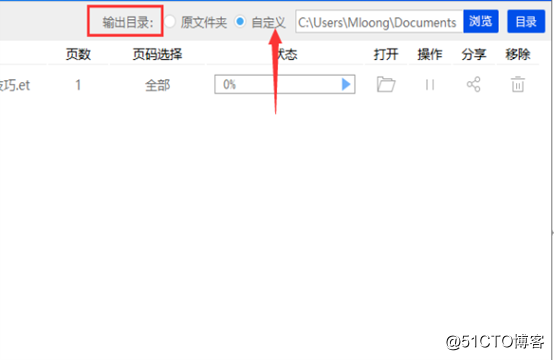
6:最后点击【确定转换】按钮就可以进入到转换的过程。转换成功需要大家稍等几秒中,看到状态栏完成100%就表示转换成功了。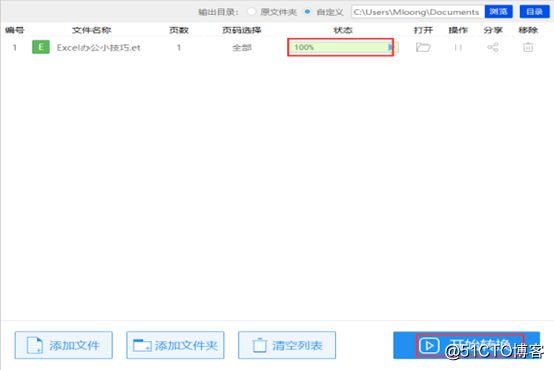
7:想要查看转换格式的文件点击状态栏后的【打开】就可以进行查看了。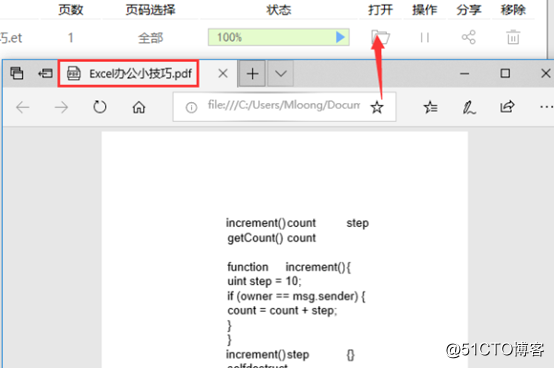
看完小编的介绍后,不知道大家对于et文件转换成PDF格式的操作弄清楚了没有,如果还有什么疑问的欢迎大家提出来!喜欢的伙伴可以点个关注!
转载于:https://blog.51cto.com/14035602/2310873

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









