






为了更详细地探讨mapper和reducer之间的关系,并揭示Hadoop的一些内部工作机理,现在我们将全景呈现WordCount是如
何执行的,序号并非完全按照上图。
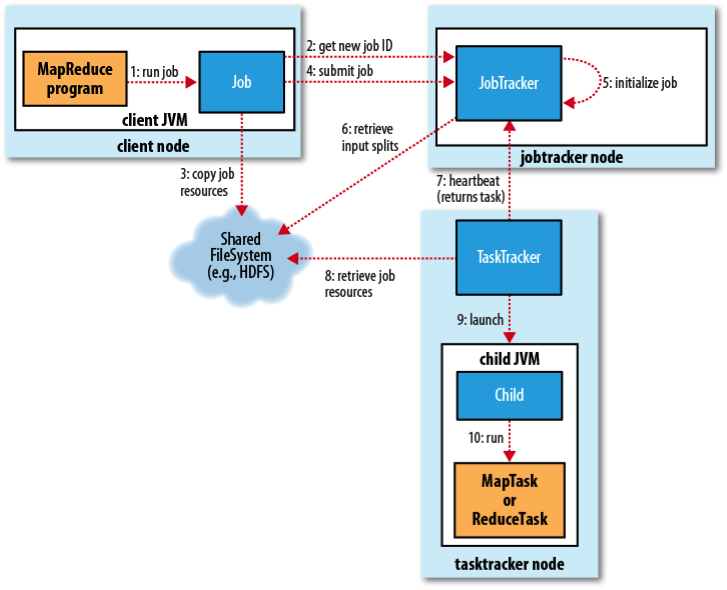
1 . 启动
调用驱动中的Job.waitForCompletion()是所有行动的开始。该驱动程序是唯一一段运行在本地机器上的代码,上述调用开
启了本地主机与JobTracker的通信。请记住,JobTracker负责作业调度和执行的各个方面,所以当执行任何与作业管理相关的
任务时,它成为了我们的主要接口,JobTracker代表我们与NameNode通信,并对储存在HDFS上的数据相关的所有交互进行
管理。
2 . 将输入分块
这些交互首先发生在JobTracker接受输入数据,并确定如何将其分配给map任务的时候。回想一下,HDFS文件通常被分
成至少64MB的数据块,JobTracker会将每个数据块分配给一个map任务。
当然,WordCount示例涉及的数量是微不足道的,它刚好适合放在一个数据块中。设想一个更大的以TB为单位的输入文
件,切分模型变得更有意义。每段文件(或用MapReduce术语来讲,每个split)由一个map作业处理。
一旦对各分块完成了运算,JobTracker就会将它们和包含Mapper与Reducer类的JAR文件放置在HDFS上作业专用的目
录,而该路径在任务开始时将被传递给每个任务。
3 . 任务分配
一旦JobTracker确定了所需的map任务数,它就会检查集群中的主机数,正在运行的TaskTracker数以及可并发执行的
map任务数(用户自定义的配置变量)。JobTracker也会查看各个输入数据块在集群中的分布位置,并尝试定义一个执行计
划,使TaskTracker尽可能处理位于相同物理主机上的数据块。或者即使做不到这一点,TaskTracker至少处理一个位于相同
硬件机架中的数据块。
数据局部优化是Hadoop能高效处理巨大数据集的一个关键原因。默认情况下,每个数据块会被复制到三台不同主机。
所以,在本地处理大部分数据块的任务/主机计划比起初预想的可能性更高。
4 . 任务启动
然后,每个TaskTracker开启一个独立的Java虚拟机来执行任务。这确实增加了启动时间损失,但它将因错误运行map
或reduce任务所引发的问题与TaskTracker隔离开来,而且可以将它配置成在随后执行的任务之间共享。
如果集群有足够的能力一次性执行所有的map任务,它们将会被全部启动,并获得它们将要处理的分块数据和作业JAR文
件。每个TaskTracker随后将分块复制到本地文件系统。
如果任务数超出了集群处理能力,JobTracker将维护一个挂起队列,并在节点完成最初分配的map任务后,将挂起任务分
配给节点。
现在,我们准备查看map任务执行完毕的数据。听起来工作量似乎很大,事实却是如此。这也解释了在运行任意
MapReduce作业时,为什么系统启动及执行上述步骤会花费大量时间。
5 . 不断监视JobTracker
现在,JobTracker执行所有的mapper和reducer。它不断地与TaskTracker交换心跳和状态消息,查找进度或问题的证
据。它还从整个作业执行过程的所有任务中收集指标,其中一些指标是Hadoop提供的,还有一些是map和reduce任务的开发
人员指定的,不过本例中我们没有使用任何指标。
6 . mapper的输入
假设输入文件是一个极为普通的两行文本文件。
This is a test.
Yes this is
驱动类使用TextInputFormat指定了输入文件的格式和结构,因此,Hadoop会把输入文件看做以偏移量为键并以该行内容
为值的文本。因此mapper的两次调用将被赋予以下输入。
0 This is a test.
15 Yes this is
7 . mapper的执行
根据作业配置的方式,mapper接收到的键/值对分别是相应行在文件中多我们不关心每行文本在文件中的位置,所以
WordCountMapper类的map方法舍弃了键,并使用标准的Java String类的split方法将每行文本内容拆分成词。需要注意的是,
使用正则表达式或StringTokenizer类可以更好地断词,但对于我们的需求,这种简单的方法就足够了。
然后,针对每个单独的词,mapper输出由单词本身组成的键和值1。
注意:
以静态变量的形式创建IntWritable对象,并在每次调用时复用该对象。这样做的原因是,尽管它对我们小型的输入文件帮助不大,但处理巨大数
据集时,可能会对mapper进行成千上万次调用。如果每次调用都为输出的键和值创建一个新对象,这将消耗大量的资源,同时垃圾回收会引发更频繁
的停滞。我们使用这个值,知道Context .write方法不会对其进行改动。
8 . mapper的输出和reducer的输入
mapper的输出是一系列形式为(word,1)的键值对。本例中,mapper的输出为:
( This , 1 ) , ( is , 1 ) , ( a , 1 ) , ( test. , 1 ) , ( Yes , 1 ) , ( this , 1 ) , ( is , 1 )
这些从mapper输出的键值对并不会直接传给reducer。在map和reduce之间,还有一个shuffle阶段,这也是许多
MapReduce奇迹发生的地方。
9 . 分块
Reduce接口的隐性保证之一是与给定键相关的所有值都会被提交到同一个reducer。由于一个集群中运行着多个reduce
任务,因此,每个mapper的输出必须被分块,使其分别传入相应的各个reducer。这些分块文件保存在本地节点的文件系统。
集群中的Reduce任务数并不像mapper数量一样是动态,事实上,我们可以在作业提交阶段指定reduce任务数。因此,每
个TaskTracker就知道集群中有多少个reducer,并据此得知mapper输出应切为多少块。
假如reducer失败了,会给本次计算带来什么影响呢?
JobTracker会保证重新执行发生故障的reduce任务,可能是在不同的节点重新执行,因此临时故障不是问题。更为严重的
问题是,数据块中的数据敏感性缺陷或错误数据可能导致整个作业失败,除非采取一些手段。
10 . 可选分块函数
Partitioner类在org.apache.hadoop.mapreduce包中,该抽象类具有如下特征:
public abstract class Partitioner<Key, Value>{ public abstract int getPartition( Key key, Value value,int numPartitions); }默认情况下,Hadoop将对输出的键进行哈希运算,从而实现分块。此功能由org.apache.hadoop.mapreduce.lib.
partition包里的HashPartitioner类实现,但某些情况下,用户有必要提供一个自定义的partitioner子类,在该子类中实现针对具
体应用的分块逻辑。特别是当应用标准哈希函数导致数据分布极不均匀时,自定义partitioner子类尤为必要。
11 . reducer类的输入
reducer的TaskTracker从JobTracker接收更新,这些更新指明了集群中哪些节点承载着map的输出分块,这些分块将由本
地reduce任务处理。之后,TaskTracker从各个节点获取分块,并将它们合并为一个文件反馈给reduce任务。
12 . reducer类的执行
我们实现的WordCountReducer类很简单。针对每个词,该类仅对数组中的元素数目进行统计并为每个词输出最终的
(Word,count)键值对。
reducer的调用次数通常小于mapper的调用次数,因此调用reducer带来的开销无需特别在意。
13 . reducer类的输出
因此,本例中的 reducer的最终输出集合为:
( This , 1 ),( is , 2 ) , ( a , 1 ) , ( test. , 1 ) , ( Yes , 1 ) , ( this , 1 )
这些数据将被输出到驱动程序指定的输出路径下的分块文件中,并将使用指定的OutputFormat对其进行格式化。每个
reduce任务写入一个以part -r-nnnnn为文件名的文件,其中nnnnn从00000开始并逐步递增。
14 . 关机
一旦成功完成所有任务,JobTracker向客户端输出作业的最终状态,以及作业运行过程中一些比较重要的计数器集合。
完整的作业和任务历史记录存储在每个节点的日志路径中,通过JobTracker的网络用户接口更易于访问,只需将浏览器指向
JobTracker节点的50030端口即可。
15 . 这就是MapReduce的全部
如你所见,Hadoop为每个MapReduce程序提供了大量机制,同时,Hadoop提供的框架在许多方面都进行了简化。如前
所述,对于WordCount这样的小程序来说,MapReduce的大部分机制并没有多大价值,但是不要忘了,无论在本地Hadoop或
是集群上,我们可以使用相同的软件和mapper/reducer在巨大的集群上对更大的数据集进行字数统计。那时,Hadoop所做的
大量工作使用户能够在如此大的数据集上进行数据分析。否则,手工实现代码分发、代码同步以及并行运算将付出超乎想象的
努力。
16 . 也许缺了combiner
前面讲述了MapReduce程序运行的各个步骤,却漏掉了另外一个可选步骤。在reducer获取map方法的输出之前,
Hadoop允许使用combiner类对map方法的输出执行一些前期的排序操作。
为什么要有combiner?
Hadoop设计的前提是,减少作业中成本较高的部分,通常指磁盘和网络输入输出。mapper的输出往往是巨大的---它的大
小通常是原始输入数据的许多倍。Hadoop的一些配置选项可以帮助减少reducer在网络上传输如此大的数据带来的性能影响。
combiner则采取了不同的方法,它对数据进行早期聚合以减少所需传输的数据量。
combiner没有自己的接口,它必须具有与reducer相同的特征,因此也要继承org.apache.hadoop.mapreduce包里的
Reduce类。这样做的效果主要是,在map节点上对发往各个reducer的输出执行mini-reduce操作。
Hadoop不保证combiner是否被执行。有时候,它可能根本不执行,而某些时候,它可能被执行一次、两次甚至多次,这
取决与mapper为每个reducer生成的输出文件的大小和数量。
学之,以记之。
转载于:https://www.cnblogs.com/baalhuo/p/5762088.html















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









