







简介:车牌检测系统是一个利用高级计算机视觉技术自动识别和定位图像中车牌的程序,广泛应用于智能交通管理等场景。该系统使用Visual C++语言开发,并融合图像预处理、车牌定位、分割与校正、字符识别以及结果输出等关键技术环节。开发者可以通过研究系统代码来学习C++编程在图像处理和机器学习算法中的应用。 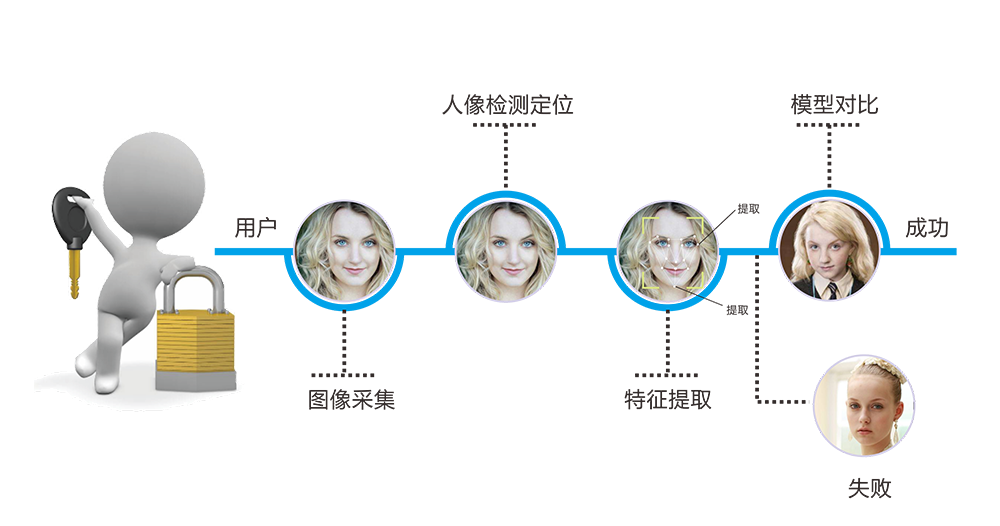
1. 计算机视觉技术在车牌检测中的应用
1.1 车牌检测的重要性
计算机视觉技术在车牌检测的应用正变得越来越重要,尤其是在交通监控、安全管理和城市智能化等领域。这项技术能够准确地从复杂的交通场景中识别出车辆的牌照,为车辆管理和法律法规执行提供了技术支持。
1.2 技术实现概述
车牌检测系统通常包含车牌定位、车牌字符分割和字符识别三个主要步骤。这个过程依赖于图像处理和模式识别技术,通过算法对车辆图像进行分析,最终提取出车牌信息。
1.3 技术难点与解决策略
车牌检测面临的难点包括不同光照条件下的车牌定位、各种车牌的尺寸与角度变化以及车牌字符的清晰度问题。通过引入机器学习和深度学习技术,可以有效地解决这些难题,并提高车牌检测系统的准确性和可靠性。
在实际应用中,通常需要结合多种算法和模型,以实现高效率和高准确度的车牌检测。例如,可以先使用边缘检测算法定位车牌的大致区域,然后通过深度学习模型对车牌进行精确识别。在此过程中,计算机视觉库如OpenCV提供了大量的图像处理工具,极大的方便了开发者的开发工作。
紧接着,我们将详细介绍如何使用Visual C++编程语言和相关的库来实现一个车牌识别系统。
2. Visual C++编程在车牌识别系统中的使用
Visual C++作为Microsoft推出的一个集成开发环境(IDE),在软件开发尤其是图像处理和机器视觉领域具有广泛的应用。本章节将详细介绍Visual C++在车牌识别系统中的使用,包括开发环境的搭建、配置,以及如何利用Visual C++集成的OpenCV图像处理库来实现高效的车牌识别处理。
2.1 Visual C++环境搭建与配置
2.1.1 安装Visual C++开发环境
Visual C++通常作为Visual Studio的一部分进行安装。首先,需要从Microsoft官方网站下载Visual Studio安装包。安装Visual Studio时,需要选择“安装”选项中的“自定义”或“详细信息”,确保安装了C++开发组件。
选择“Visual C++桌面开发”工作负载,并在安装过程中确保安装了最新版本的MSVC编译器和链接器、C++标准库、调试器、性能分析工具等。
安装完成之后,需要运行Visual Studio进行初始配置,包括选择主题、字体大小等,以适应开发者的个人喜好。
2.1.2 开发环境的基本配置
在安装好Visual Studio之后,开发者需要进行一系列基本配置,以满足项目开发的需求。首先是工具选项的配置,这包括代码样式、自动完成设置、调试器选项等。
- 打开Visual Studio,选择“工具”->“选项”菜单,在弹出的对话框中可以进行详细的设置。
- 对于C++项目,特别需要检查“文本编辑器”->“C++”->“高级”中的代码样式,确保它们符合项目的编码标准。
- 在“调试”选项中,可以设置调试选项,比如在异常发生时是否自动中断。
此外,还需要配置项目属性,包括编译选项、链接器选项等,以确保代码能够按照预期编译和运行。
2.2 Visual C++中的图像处理库
2.2.1 OpenCV库的安装与配置
OpenCV是一个开源的计算机视觉和机器学习软件库,它提供了大量的图像处理和识别功能。在Visual C++中使用OpenCV,需要先安装OpenCV库,并配置环境。
1. 下载OpenCV的Windows版本,解压到本地磁盘。
2. 设置环境变量,在系统变量中添加OpenCV的bin路径,以便系统能够找到OpenCV的DLL文件。
3. 在Visual Studio中配置项目属性,将OpenCV的lib和include路径添加到项目的链接器和C/C++包含目录中。
安装OpenCV后,可以使用OpenCV提供的接口进行图像的读取、显示、处理等操作。
2.2.2 利用OpenCV进行图像读取和显示
OpenCV提供了简洁的API来处理图像。下面是一个使用OpenCV进行图像读取和显示的示例代码:
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 读取图像文件
cv::Mat image = cv::imread("path_to_image.jpg");
// 检查图像是否成功加载
if(image.empty()) {
std::cout << "图像加载失败!" << std::endl;
return -1;
}
// 显示图像
cv::namedWindow("显示图像", cv::WINDOW_AUTOSIZE);
cv::imshow("显示图像", image);
// 等待按键,否则窗口会立即关闭
cv::waitKey(0);
return 0;
}
该代码段首先包含了OpenCV库,然后在 main 函数中读取了一个图像文件,并显示在窗口中。这里使用的 cv::imread 函数用于读取图像, cv::namedWindow 和 cv::imshow 用于创建窗口和显示图像。 cv::waitKey(0) 函数用于等待用户按键,这样窗口不会立即关闭。
2.3 Visual C++中的文件操作和数据管理
2.3.1 文件读写操作实践
在车牌识别系统中,经常需要读取和写入数据,例如从配置文件读取参数、保存识别结果等。Visual C++提供了标准的文件I/O操作,可以满足这些需求。
#include <fstream>
#include <iostream>
int main() {
// 打开文件进行读取
std::ifstream file("input.txt");
if (!file.is_open()) {
std::cerr << "无法打开文件" << std::endl;
return -1;
}
std::string line;
// 逐行读取文件内容
while (getline(file, line)) {
std::cout << line << std::endl;
}
// 关闭文件
file.close();
// 打开文件进行写入
std::ofstream outfile("output.txt");
if (!outfile.is_open()) {
std::cerr << "无法打开文件" << std::endl;
return -1;
}
// 向文件写入数据
outfile << "Hello, World!" << std::endl;
// 关闭文件
outfile.close();
return 0;
}
2.3.2 数据存储和管理技巧
在车牌识别系统中,除了文件I/O之外,还可能需要数据库来管理大量的识别数据。可以利用Visual C++连接到数据库,并执行SQL查询。
#include <iostream>
#include <sql.h>
#include <sqlext.h>
int main() {
SQLHENV hEnv = NULL;
SQLHDBC hDbc = NULL;
SQLHSTMT hStmt = NULL;
SQLRETURN retcode;
// 分配环境句柄
retcode = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &hEnv);
// 设置环境属性
SQLSetEnvAttr(hEnv, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);
// 分配连接句柄
retcode = SQLAllocHandle(SQL_HANDLE_DBC, hEnv, &hDbc);
// 连接到数据源
retcode = SQLConnect(hDbc, (SQLCHAR*)"Data Source Name", SQL_NTS, (SQLCHAR*)"Username", SQL_NTS, (SQLCHAR*)"Password", SQL_NTS);
// 检查是否成功连接
if (retcode != SQL_SUCCESS && retcode != SQL_SUCCESS_WITH_INFO) {
std::cerr << "数据库连接失败" << std::endl;
// 释放句柄,清理
// ...
}
// 分配语句句柄
retcode = SQLAllocHandle(SQL_HANDLE_STMT, hDbc, &hStmt);
// 执行SQL查询
retcode = SQLExecDirect(hStmt, (SQLCHAR*)"SELECT * FROM table_name", SQL_NTS);
// 处理查询结果
// ...
// 释放句柄,清理
// ...
return 0;
}
该代码段展示了如何连接到数据库并执行一个简单的查询。需要注意的是,实际使用时需要根据实际数据库类型和数据源名称进行相应的调整,并在结束使用后释放所有分配的句柄以避免内存泄漏。
3. 图像预处理技术实现
图像预处理作为计算机视觉领域中的核心技术之一,其目的是为了改善图像数据的质量,以便后续处理能更准确高效。在车牌检测和识别系统中,图像预处理尤为关键,因为车牌图像的多样性、环境因素的干扰以及车牌本身的不同都会对车牌的准确识别造成影响。本章将详细介绍图像预处理的理论基础、方法、以及如何在实际项目中应用这些技术。
3.1 图像预处理的理论基础
3.1.1 图像预处理的重要性
在车牌识别系统中,图像预处理起到决定性的作用。未经处理的原始图像可能含有噪声、不一致性或者不清晰,这些因素均会影响到车牌的定位、字符分割和字符识别等后续步骤。图像预处理的目的是提高图像质量,从而降低后续处理步骤的难度和错误率。
3.1.2 常见的图像预处理方法
常见的图像预处理方法包括:灰度转换、二值化处理、噪声去除、图像平滑、图像增强和边缘检测。这些方法在不同的应用场景中可以根据需要进行选择和组合,以达到最佳预处理效果。
3.2 图像预处理的实战演练
3.2.1 灰度转换和二值化处理
灰度转换是指将彩色图像转换为灰度图像,这是因为在车牌识别中,颜色信息往往不是必要的,而灰度图像的数据量更小,处理起来也更快。下面的代码演示了使用OpenCV库在C++中如何将彩色图像转换为灰度图像:
#include <opencv2/opencv.hpp>
using namespace cv;
int main() {
// 加载彩色图像
Mat colorImage = imread("path_to_image");
if (colorImage.empty()) {
printf("图像加载失败");
return -1;
}
// 转换为灰度图像
Mat grayImage;
cvtColor(colorImage, grayImage, COLOR_BGR2GRAY);
// 显示原始彩色图像和灰度图像
namedWindow("Original Image", WINDOW_AUTOSIZE);
imshow("Original Image", colorImage);
namedWindow("Gray Image", WINDOW_AUTOSIZE);
imshow("Gray Image", grayImage);
waitKey(0);
return 0;
}
灰度转换后的图像可以进一步使用二值化处理,以简化图像数据。二值化处理通常依赖于设定一个阈值,将图像中的像素点分为两类,一类为背景,一类为前景。下面是二值化处理的代码示例:
Mat binaryImage;
threshold(grayImage, binaryImage, 128, 255, THRESH_BINARY);
3.2.2 噪声去除和图像平滑技术
噪声去除通常利用图像平滑技术,如高斯模糊或者中值滤波等。高斯模糊是通过将图像与高斯核进行卷积,达到图像平滑的效果。而中值滤波则通过取邻域像素的中值来代替原像素值,能有效去除椒盐噪声。下面展示了如何在C++中使用OpenCV进行高斯模糊和中值滤波处理:
Mat gaussianBlurImage;
GaussianBlur(binaryImage, gaussianBlurImage, Size(5, 5), 1.5);
Mat medianFilterImage;
medianBlur(gaussianBlurImage, medianFilterImage, 5);
3.2.3 图像增强和边缘检测
图像增强可以通过直方图均衡化来改善图像的对比度,而边缘检测则是为了识别图像中的重要边界,这在车牌字符分割中尤为重要。下面展示使用C++和OpenCV进行图像增强和边缘检测的代码:
Mat enhancedImage;
equalizeHist(binaryImage, enhancedImage);
Mat edges;
Canny(enhancedImage, edges, 100, 200); // Canny边缘检测
经过上述图像预处理步骤,车牌图像的清晰度、对比度和边缘特征被显著增强,为后续的车牌定位和字符识别打下良好的基础。
4. 车牌定位算法的应用
4.1 车牌定位算法理论解析
4.1.1 车牌定位的一般流程
车牌定位是车牌识别系统中的关键步骤,其目标是准确地从车辆图像中找到车牌的位置。车牌定位算法通常包括以下步骤:
- 图像采集 :首先需要采集车辆的图像,这可以通过摄像头来完成。
- 图像预处理 :对采集到的图像进行预处理,如灰度化、二值化、去噪等,以减少后续处理的计算量并提高定位精度。
- 车牌区域候选 :使用特定的算法或策略确定车牌可能存在的区域,这些区域被称为车牌区域候选。
- 车牌定位 :对候选区域进行详细的分析,最终确定车牌的确切位置。
- 车牌尺寸校正 :由于车牌在图像中的角度和距离可能不同,需要对车牌进行几何变换以校正其尺寸和方向。
4.1.2 车牌特征的提取和分析
车牌特征的提取是车牌定位算法的核心部分,主要包括车牌的颜色、形状、纹理等特征。车牌的颜色特征通常为白色背景、黑色字符,形状特征为矩形,而纹理特征则涉及车牌字符的分布和间隔。
在提取车牌特征时,算法通常会利用边缘检测、纹理分析等图像处理技术。例如,通过边缘检测可以找到图像中的车牌边界,而基于HOG(Histogram of Oriented Gradients)特征的检测器可以用来识别车牌的形状。
4.2 车牌定位算法的实践应用
4.2.1 颜色分析法在车牌定位中的应用
颜色分析法是基于车牌颜色特征的定位方法,其基本原理是利用车牌的标准颜色范围来检测可能的车牌区域。
// 伪代码示例:颜色分析法
void locateLicensePlateByColorAnalysis(Mat &image) {
// 转换到HSV色彩空间
Mat hsvImage;
cvtColor(image, hsvImage, COLOR_BGR2HSV);
// 定义车牌颜色的HSV范围
Scalar lowerWhite(0, 0, 200);
Scalar upperWhite(255, 20, 255);
// 根据颜色范围创建掩模
Mat mask;
inRange(hsvImage, lowerWhite, upperWhite, mask);
// 对掩模进行膨胀等操作,以强化车牌区域
dilate(mask, mask, Mat());
// 寻找掩模中的轮廓
vector<vector<Point>> contours;
findContours(mask, contours, RETR_TREE, CHAIN_APPROX_SIMPLE);
// 进一步的处理和分析以定位车牌...
}
在上述代码块中,我们首先将输入图像从BGR色彩空间转换到HSV色彩空间,然后定义了白色车牌在HSV空间中的范围。通过 inRange 函数创建掩模,然后使用 findContours 找到可能的车牌轮廓。这是车牌定位的初步过程,后续需要进一步的处理来精确识别车牌的位置。
4.2.2 边缘检测与形态学操作结合法
边缘检测与形态学操作结合法主要利用车牌的形状特征进行定位。首先通过边缘检测算子(如Canny算子)来检测图像中的边缘,然后利用形态学操作(如膨胀、腐蚀)来强化车牌区域的轮廓。
// 伪代码示例:边缘检测与形态学操作结合法
void locateLicensePlateByEdgeMorphology(Mat &image) {
// 使用Canny算子进行边缘检测
Mat edges;
Canny(image, edges, 50, 150);
// 定义结构元素,用于形态学操作
Mat element = getStructuringElement(MORPH_RECT, Size(15, 15));
// 膨胀操作,强化边缘并连接断裂部分
Mat dilation;
dilate(edges, dilation, element);
// 腐蚀操作,去除无关的边缘
Mat eroded;
erode(dilation, eroded, element);
// 寻找形态学操作后轮廓并进一步处理...
}
在这个过程里,我们首先应用了Canny边缘检测算法来找到图像中的边缘信息,然后通过膨胀和腐蚀操作来强化车牌区域的轮廓。这个方法可以有效地区分车牌区域和其他边缘区域,有助于定位车牌。
4.2.3 基于机器学习的车牌定位技术
基于机器学习的车牌定位技术使用训练好的模型来识别和定位车牌。这些模型能够学习车牌的外观特征,并在新图像中识别出车牌的位置。
# 伪代码示例:基于机器学习的车牌定位技术(Python)
import cv2
import numpy as np
from sklearn.externals import joblib
# 加载训练好的机器学习模型
model = joblib.load("license_plate_recognizer.pkl")
def locateLicensePlateByMachineLearning(image):
# 图像预处理步骤...
# ...
# 使用模型进行车牌位置预测
prediction = model.predict([processed_image])
# 根据预测结果定位车牌...
# ...
在这里我们首先导入了必要的库,并加载了训练好的机器学习模型。然后定义了一个函数 locateLicensePlateByMachineLearning 来处理输入图像,并利用加载的模型进行预测,预测结果用于最终的车牌定位。这种方法通常能够提供较高的定位准确性,尤其是在复杂背景和不同光照条件下。
5. OCR技术在字符识别中的实现
5.1 OCR技术概述及原理
5.1.1 OCR技术的定义和分类
OCR(Optical Character Recognition,光学字符识别)技术是指通过扫描或图像捕捉设备将各种印刷品的文字图像输入到计算机中,并利用文字识别技术将其转换成文本格式的过程。这一过程允许人们将印刷的文字信息转换为可编辑、可搜索、可索引的数字文本。
OCR技术主要可以分为两类: 1. 基于规则的OCR:通过设定字符的形状、结构、笔画等特征来识别文字。 2. 基于机器学习的OCR:使用大量已标记的文字样本训练识别模型,能够自适应地学习和识别新的文字。
5.1.2 OCR技术的工作原理
OCR技术的核心是一个复杂的字符识别引擎。工作原理可以概括为以下几个步骤:
- 图像预处理 :在字符识别之前,需要对图像进行预处理,包括去噪、二值化、缩放、倾斜校正等操作。
- 字符分割 :将图像中的字符分割成单个字符,以便独立识别。
- 特征提取 :提取每个字符的特征,这些特征可能包括但不限于边缘信息、几何特征、纹理特征等。
- 字符识别 :将提取的特征与OCR系统中存储的字符特征模板进行匹配,识别出字符。
- 后处理 :根据上下文对识别结果进行校正和优化,以提高识别准确率。
5.2 OCR技术在车牌识别中的应用
5.2.1 利用Tesseract进行字符识别
Tesseract是一个开源的OCR引擎,由HP开发,现在由Google维护。Tesseract支持多种操作系统,能够识别多种语言的文字。
在车牌识别中,使用Tesseract进行字符识别,可以按照以下步骤进行:
- 安装Tesseract :首先需要在系统上安装Tesseract OCR引擎。
- 图像预处理 :使用图像处理技术对车牌图像进行预处理,如二值化、去除噪声、字符分割等。
- 设置Tesseract参数 :调用Tesseract的API设置识别语言、图像格式等参数。
- 执行识别 :将预处理后的图像传递给Tesseract进行字符识别。
- 后处理 :根据车牌的特定格式和规则,对Tesseract的识别结果进行校正。
下面是一个使用Tesseract进行字符识别的简单示例代码:
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#include <iostream>
int main() {
// 初始化Tesseract API
tesseract::TessBaseAPI* ocr = new tesseract::TessBaseAPI();
if (ocr->Init(NULL, "eng")) {
std::cerr << "Could not initialize tesseract." << std::endl;
return 1;
}
// 打开图像文件
Pix *image = pixRead("/path/to/your/image.png");
ocr->SetImage(image);
// 识别图像中的文字并打印输出
char *text = ocr->GetUTF8Text();
std::cout << text << std::endl;
// 释放资源
ocr->End();
pixDestroy(&image);
delete [] text;
return 0;
}
5.2.2 优化OCR识别精度的方法
为了提高OCR的识别精度,可以采用以下策略:
- 图像质量优化 :确保输入的车牌图像清晰,减少噪声和模糊。
- 字符分割优化 :改进算法准确地分割字符,避免相邻字符粘连。
- 使用自定义字典 :为OCR系统提供一个包含车牌字符集的自定义字典,提高识别准确性。
- 后处理校验 :利用已知的车牌格式和规则进行校验,纠正识别错误。
- 机器学习增强 :结合机器学习算法,如支持向量机(SVM)或神经网络,提升识别效果。
5.2.3 OCR技术的集成与测试
在实际应用中,集成OCR技术到车牌识别系统需要考虑以下方面:
- 模块化设计 :将OCR识别模块与车牌定位、预处理等模块分离,便于维护和更新。
- 测试与评估 :在不同条件下进行大量的测试,评估OCR模块的性能,包括识别速度、准确率等。
- 用户反馈 :收集用户反馈,不断迭代改进OCR模块。
5.3 结果输出的处理和存储
5.3.1 识别结果的整理与输出
OCR技术在车牌识别中识别出的字符需要整理成可读的格式,方便后续处理。常见的处理步骤如下:
- 字符清洗 :去除识别结果中多余的特殊字符、空格等。
- 格式化输出 :按照车牌的标准格式,整理识别结果。
- 验证与确认 :通过人工或自动的方式验证识别结果的正确性。
5.3.2 结果数据的存储与管理
车牌识别后的结果数据需要存储和管理,以便于查询和检索。以下是存储和管理数据的建议:
- 数据库设计 :设计适合车牌识别结果存储的数据库结构,包括车牌号码、识别时间、地点等信息。
- 数据索引 :创建索引以加速查询操作。
- 数据备份 :定期备份数据,防止数据丢失。
- 安全性考虑 :确保数据存储的安全性,防止未授权访问。
通过上述内容的详细介绍和实践应用,我们可以看到在车牌识别系统中,OCR技术发挥着至关重要的作用。随着技术的不断进步,未来OCR技术在准确度、速度以及处理复杂环境下的能力将更加强大,为车牌识别系统提供更加稳定可靠的解决方案。
简介:车牌检测系统是一个利用高级计算机视觉技术自动识别和定位图像中车牌的程序,广泛应用于智能交通管理等场景。该系统使用Visual C++语言开发,并融合图像预处理、车牌定位、分割与校正、字符识别以及结果输出等关键技术环节。开发者可以通过研究系统代码来学习C++编程在图像处理和机器学习算法中的应用。

















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









