







常用术语::


分词算法::
- 词典匹配分词法
- 与机器字典词条匹配
- 包括:
- 正向最大匹配
- 逆向最大匹配
- 最小切分(一句话切的词数最小)
- 语义理解分词法
- 目前中文分词没达到这种级别
- 词频统计分词法
- 相邻的字搭配出现的频率越高,越有可能是个词
- 不需要切分词典
- 高频共同出现的两个字有的也不是一个词,需要专门处理以提高精度
- 应与字典分词结合使用
- 可以很好的解决新词未被收录词典的问题
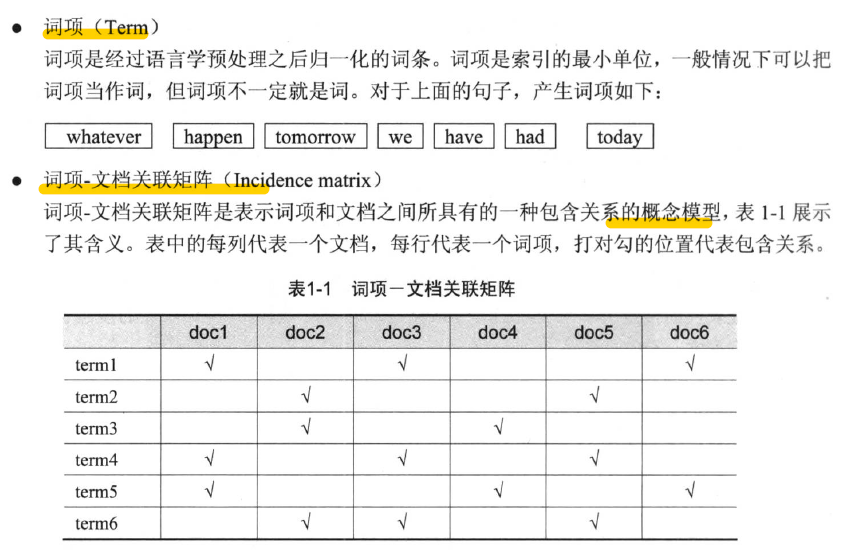
倒排索引
- 反向索引
布尔检索模型
- 布尔运算符连接各个检索词
- 优先级:NOT>AND>OR
- AND
- OR
- NOT
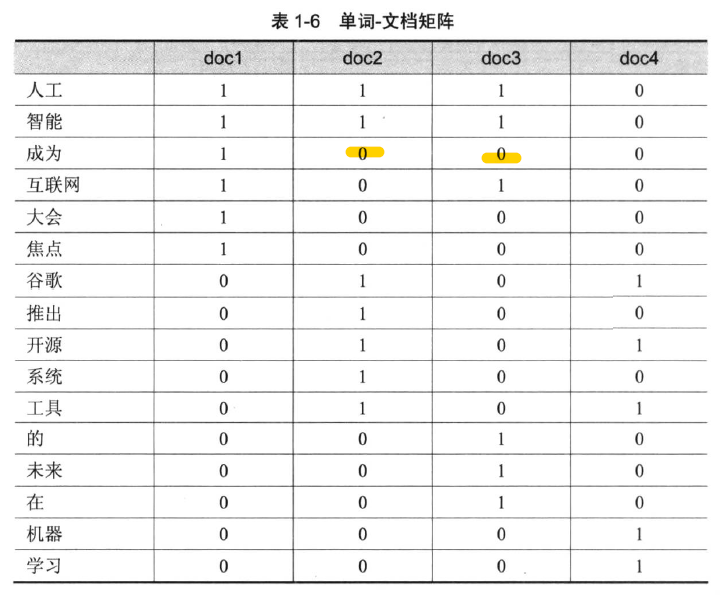
单词-文档矩阵
![]()

- 结果是0101:代表文档2 和文档4 为查询结果
布尔运算模型优点:
- 符合人们思维
- 表达式直观清晰
- 方便扩检、缩检
- 易于计算机实现
布尔运算模型缺点:
- 仅仅基于0、1二元判断标准
- 不能进行关键词重要性排序
- 没有反应语义含义
- 很多用户想查询的东西很难用表达式表达
- 完全匹配导致太少的结果被返回
- 没有加权的概念,容易出现漏检
tf-idf 权重计算
- tf-idf 叫词频-逆文档频率
- 词项(item)的重要性由:
- 在文档中出现的频率正相关
- 在文档集中出现的次数反相关

- lucene 采取的计算词频标准化的方法:
- df 代表文档集中出现词项的文档数量

- + 1 是因为分母不能为零
- 词项权重::
- 一个文档就可以表示成是 n 维词项向量

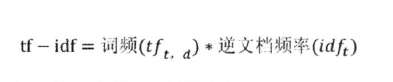
向量空间模型::
- 向量求余弦的方法计算相似性
- 余弦相似性理论:
- Lucene 的评分机制更加复杂:
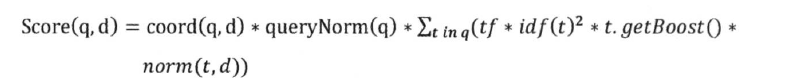

- 上述公式整体依然是按照tf-idf 和向量空间模型的相似性计算
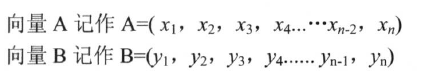
概率检索模型::
- 从概率排序原理推导而来
- 基本思想:
- 给定一个查询,返回结果是按照与查询语句相关性得分排序的
- 比如:BM25模型(best match 25)
- 最成功的概率检索模型
- 贝叶斯决策理论
- 概率检索模型的数学基础
- 在机器学习、自然语言处理等领域广泛应用
- 海量文本数据分类:
- 比如垃圾邮件甄选、过滤
- 核心思想:选择高概率对应的类别

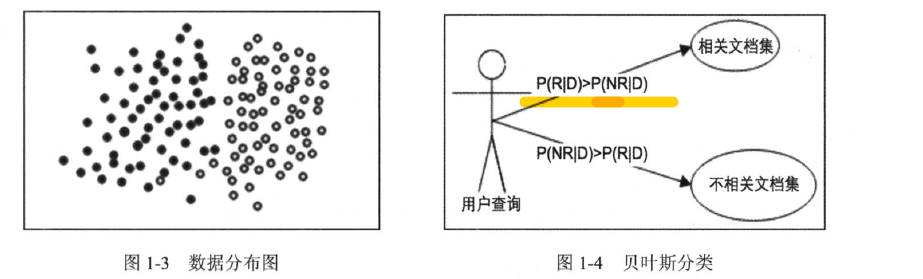
文档D,P(R|D)属于相关文档集的概率、P(NR|D) 不属于相关文档集的概率
- 由贝叶斯公式计算:
- 推导得出公式:

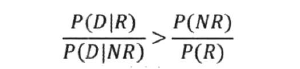
二值独立模型::
- 词项的独立性假设(假设每个词都是独立出现的)
- 文档频率转换成词项概率的乘积
- 推导出公式::
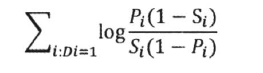
- Pi 表示第i 个词项出现在文档中的概率
- Si 表示第i 个词项在不相关文档集中出现的概率
- Di = 1 表示单词在文档出现
- Di = 0 表示单词在文档不出现

- 最后是计算log 值,做一个平滑处理不影响结果 大小顺序
- 分子分母 加上常数,避开log(0)
- 分子分母 加上常数,避开log(0)
- 最后公式::
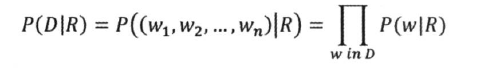
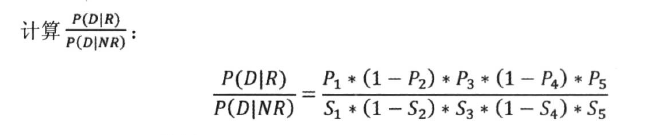
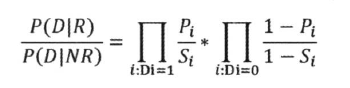
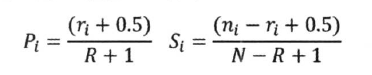
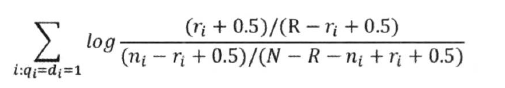
Okapi BM25 模型::
- 二值独立模型,仅仅考虑了词项出现与否,没有考虑单词的权重,实际效果不理想
- BM25 进行了改进,考虑进去了:
- idf 因子、文档长度、查询词频等因素
- idf 因子、文档长度、查询词频等因素
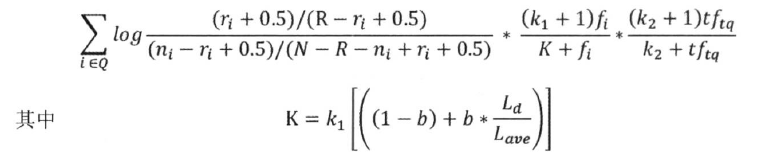
BM25F ::
- Okapi BM25 仅仅是把文档当做整体考虑
- 没有考虑不同区域的权重差异
- 比如网页,标题、主题词、摘要、内容权重是不一样的
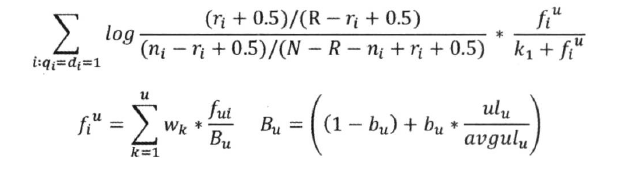















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









