






3/7/2016

这是经理帮我们分析的一个爬虫制作过程。
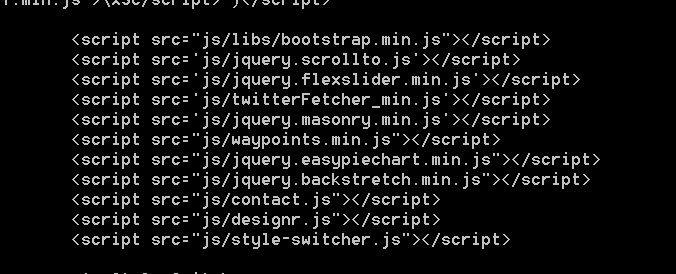
这是初步的访问html页面,但是这个跟直接查看源代码的效果是一样的。。。我们制作爬虫的目的是将一个网站的静态页面爬下来,改成我们自己要做的网站,我感觉我讲的都不清楚,请各位前辈帮忙分析一下我应该怎么入手
3/8/2016
目前进度做到分类(js/css/img)和下载
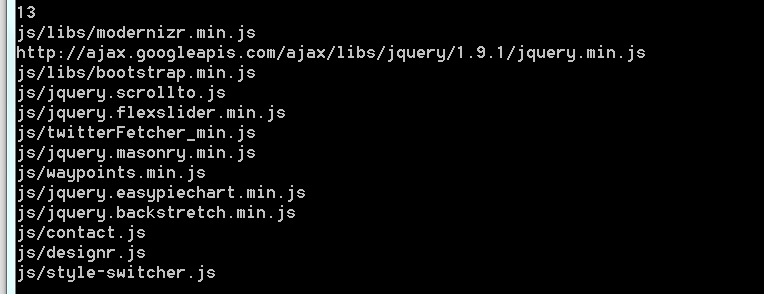
上图是其中的script分类,但是在下载的时候,由于这些js/css/imgt都是外链,下载的时候出现下图
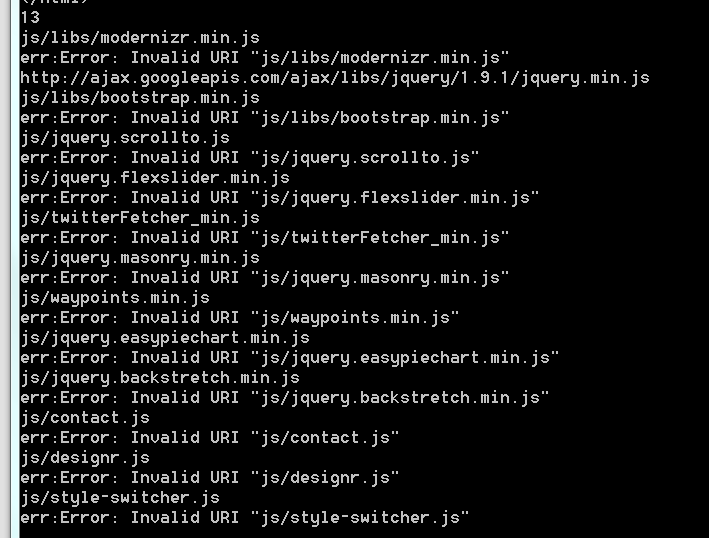
目前正在寻找这解析外链的资料,感觉应该不难,有前辈提示吗?
现在是下午16:18,贴上目前的代码和进度
var http = require(‘http’);
var cheerio = require(‘cheerio’);
var request = require(‘request’);
var path = require(‘path’);
var fs = require(‘fs’);
var url = ‘http://demos.q-themes.net/designr/v1.3/’;
request(url,function (error,response,body) {
if(!error && response.statusCode == 200){
console.log(body);
acquireData_3(body);
}
});
function acquireData_3 (data) {
var $ = cheerio.load(data); //cheerio解析data
var images = $(‘img[src]’).toArray();
console.log(images.length);
var len = images.length;
for (var i=0;i
//console.log(images[i]);
var imgsrc = images[i].attribs.src;
console.log(imgsrc);
var filename = parseUrlForFileName(imgsrc);
downloadImg(imgsrc,filename,function() {
console.log(filename+‘done’);
});
}
}
function parseUrlForFileName (address) {
return filename;
}
var downloadImg = function (uri,filename,callback) {
request.head(uri,function (err,res,body) {
if(err){
console.log(‘err:’+err);
return false;
}
console.log(‘res:’+res);
request(uri).pipe(fs.createWriteStream(‘image/’+filename)).on(‘close’,callback);
});
};
这段代码还是做不到下载外链,我的思路就是用 path.join 这个API来将外链地址组合起来,就是这段:
function parseUrlForFileName (address) {
return filename;
** 但是我的写法肯定错了,有前辈帮忙指出来吗?还是我用的API不对?**
3/21/2016
天哪,刚刚复制时间的时候,我发现我居然是7号开始做的,也就是说我花了一个礼拜的时间还没做完。。。惭愧,得加油了!
下面是url组合成功的结果图
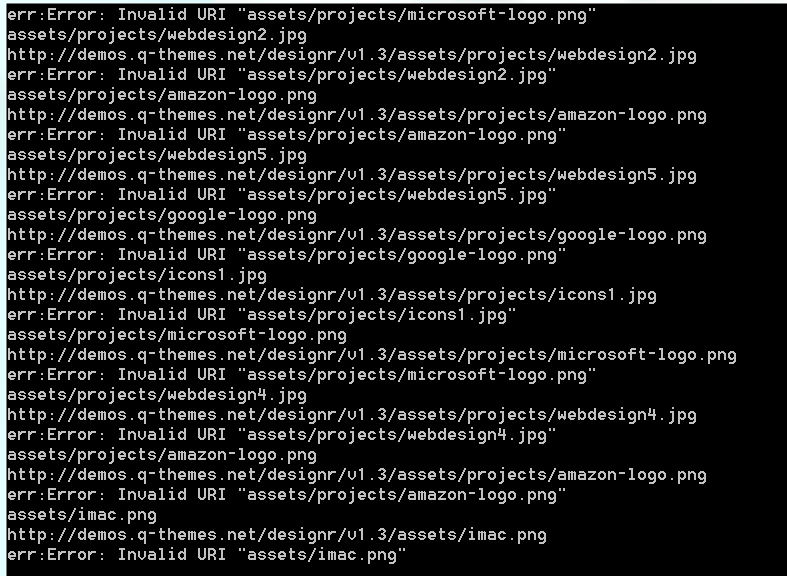
先忽略里面的err,可以看到地址已经拼接成功了,下面贴代码,用的组合方法是url.resolve(‘http://demos.q-themes.net/designr/v1.3/’,imgsrc);
function acquireData_3 (data) {
var $ = cheerio.load(data); //cheerio解析data
var images = $(‘img[src]’).toArray(); //contain img script
console.log(images.length);
var len = images.length;
for (var i=0;i
//console.log(images[i]);
var imgsrc = images[i].attribs.src;
console.log(imgsrc);
var filename = url.resolve(‘http://demos.q-themes.net/designr/v1.3/’,imgsrc);
console.log(filename);
downloadImg(imgsrc,filename,function() {
console.log(filename+’ 下载成功’);
});
}
}
var downloadImg = function (uri,filename,callback) {
request.head(uri,function (err,res,body) {
if(err){
console.log(‘err:’+err);
return false;
}
console.log(‘res:’+res);
request(uri).pipe(fs.createWriteStream(‘image/’+filename)).on(‘close’,callback);
});
};
显然错误原因就是downloadImg方法中uri的路径还是imgsrc也就是没有拼接的地址,修改过几次不同的方式,但是都没成功,所以先继续看request的API,有前辈知道怎么改的话帮忙提出来,谢谢!
这是用组合出来的地址访问到的
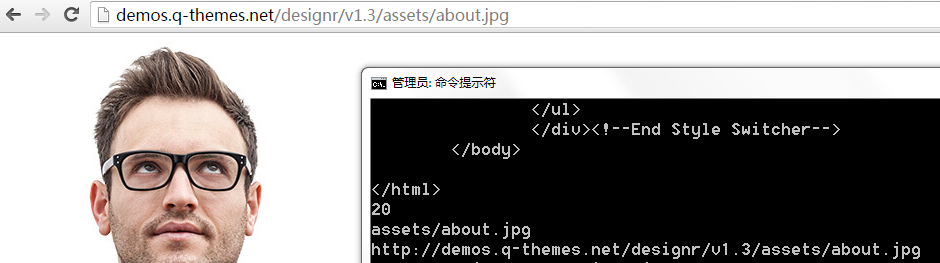
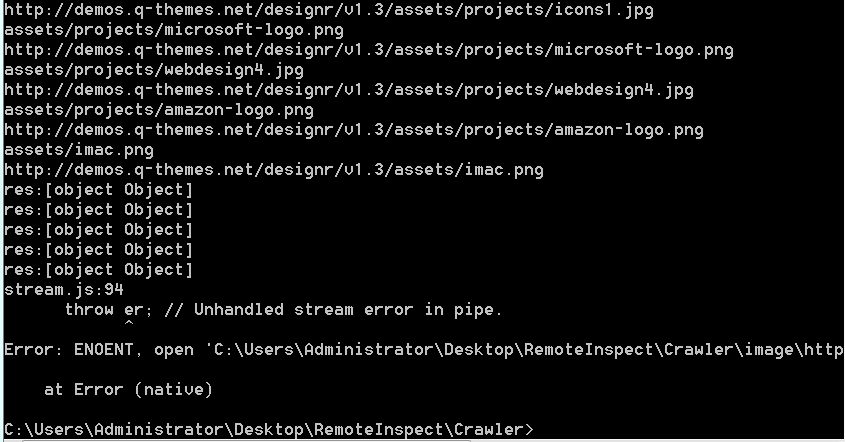
这是目前的错误提示,图下面贴代码
function acquireData_3 (data) {
var $ = cheerio.load(data); //cheerio解析data
var images = $(‘img[src]’).toArray(); //contain img script
console.log(images.length);
var len = images.length;
for (var i=0;i
//console.log(images[i]);
var imgsrc = images[i].attribs.src;
console.log(imgsrc);
var filename = url.resolve(‘http://demos.q-themes.net/designr/v1.3/’,imgsrc);
//console.log(filename);
var imgsrc_0 = url.resolve(‘http://demos.q-themes.net/designr/v1.3/’,imgsrc);
console.log(imgsrc_0);
downloadImg(imgsrc_0,filename,function() {
console.log(filename+’ 下载成功’);
});
}
}
var downloadImg = function (uri,filename,callback) {
request(uri,function (err,res,body) {
if(err){
console.log(‘err:’+err);
return false;
}
console.log(‘res:’+res);
request(uri).pipe(fs.createWriteStream(‘image/’+filename)).on(‘close’,callback);
});
};















 3321
3321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









