







1,问题描述
取script里面的数据,如图
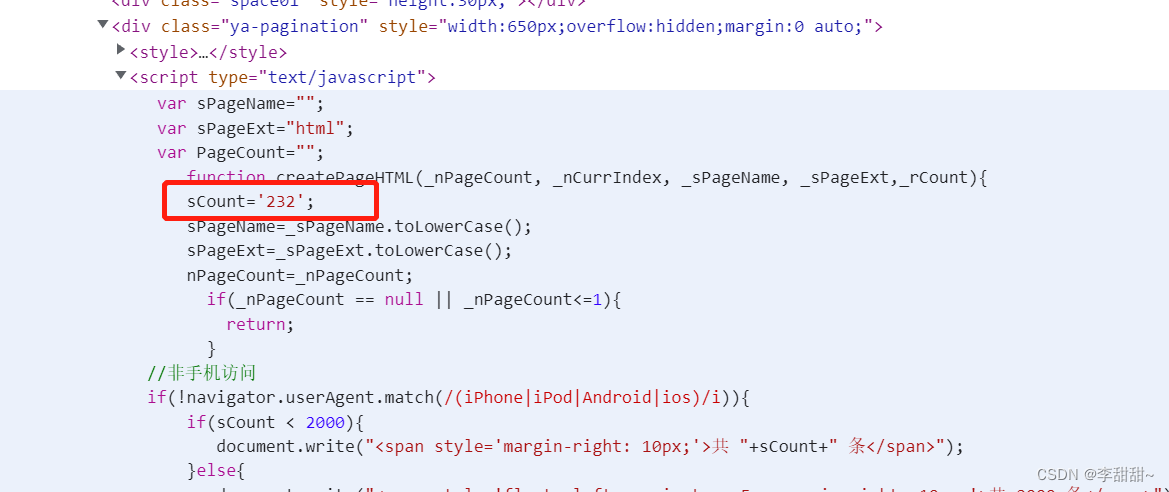
2,解决
1,框架:scrapy
2,通过xpath去到标签
3,利用正则表达取出内容
不知为啥正则写成r"sCount=.*;$" 匹配不成功,得写为r"sCount=.*" 【摊手】.jpg
text = response.xpath('/html/body/center/div/div[3]/div[2]/div[3]/script/text()').get()
count = re.compile(r"sCount=.*")
self.page = int(count.findall(text)[0].split("'")[1])
# 上面那个写的不好,看下面这个
script = response.xpath("//script[contains(.,'sCount')]").get()
page = int(re.findall(r"var sCount='(\d+)'", script, flags=re.S)[0])














 6982
6982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









