



 本文是一篇关于使用Hysplit进行后推气流轨迹聚类分析的速成指南,详细介绍了从气象数据准备、批量计算轨迹、轨迹聚类到结合污染物浓度分析的全过程,旨在帮助研究者理解目标地点的气团来向和污染物源解析。
本文是一篇关于使用Hysplit进行后推气流轨迹聚类分析的速成指南,详细介绍了从气象数据准备、批量计算轨迹、轨迹聚类到结合污染物浓度分析的全过程,旨在帮助研究者理解目标地点的气团来向和污染物源解析。

作者:陈天舒,山东大学环境科学(大气化学)博士在读
发现网上关于用Hysplit做后推气流轨迹聚类分析的教程较少并且不详细,因此萌生写个速成指南的想法。
后推气流轨迹的聚类指的是将一段时间内的后退气流轨迹按照一定方法进行分类归纳。聚类分析可以用于分析目标地点的气团的来向构成以及占比。
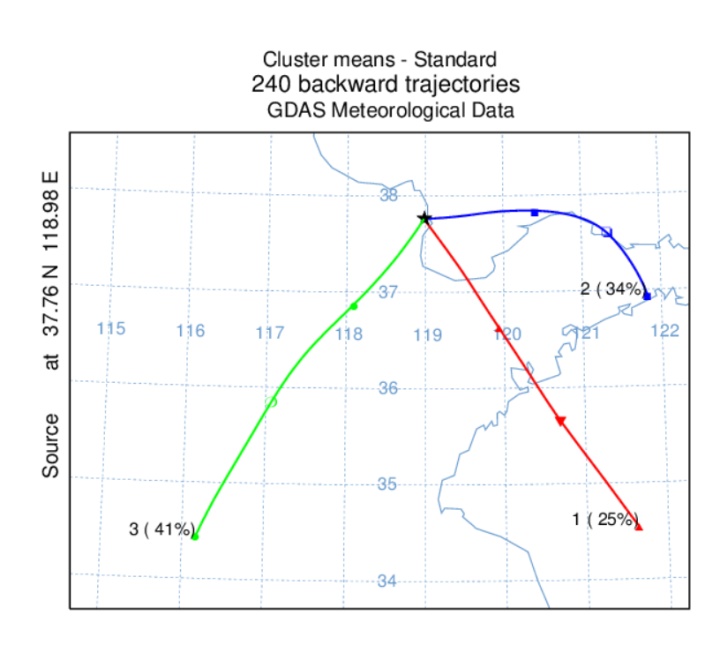
我们常在文献中看到这样的图,用于分析研究地点的气团传输机制:
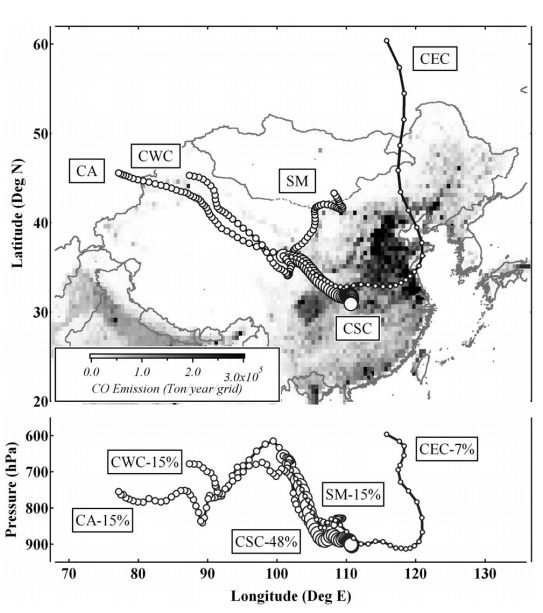
也会看到这样的表,分析不同来源的气团的污染物浓度:
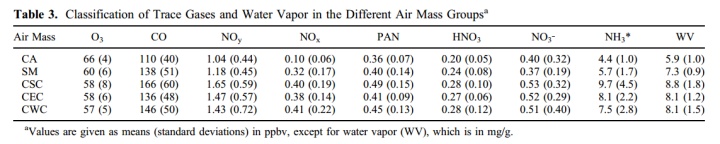
这些分析通过Hysplit可以做到。
分为四个步骤:气象数据准备;按所需时间段批量计算后推气流轨迹;对后退气流轨迹数据进行聚类;将聚类结果与污染物浓度数据结合分析。
一、下载气象数据
要计算后退气流轨迹,最重要的是气象数据,一般常用的气象数据为GDAS1。
下载地址为:下载gdas1气象数据
文件格式为“gdas1.英文月份缩写+年份.第几周”。例如,“gdas1.apr05.w3”指的是2005年四月第三周的气象数据。
其他Hysplit支持的气象数据格式详见:
READY - Gridded Data Archivesready.arl.noaa.gov
二、按所需时间段批量计算后退气流轨迹
分为两小步:
1、初始参数设置
打开Hysplit主界面->“Trajectory"->“Setup Run”
无论是跑单次的后推气流轨迹还是跑一段时间的,都需要在Setup Run的页面里进行参数的预先设置。如图所示:
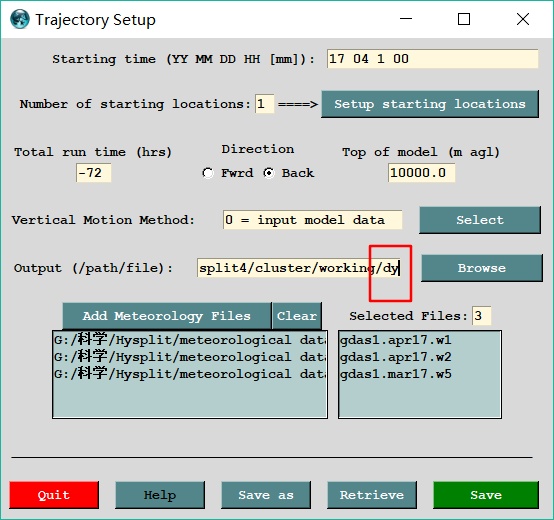
需要设置的参数有:
(1)开始时间:按年月日小时的顺序输入起始时间,注意空格。
(2)起始位置的数量:一般只研究一个点,填1。同时点击右侧的Setup starting location,填写坐标经纬度以及起始高度。
(3)总运行时间:按实际需求填写,一般和你要研究的物种的大气化学寿命相关。
(4)方向:选择后推“Back”。
(5)模型层高:填写模型的最大高度,一般按默认即可。
(6)垂直运动模式:点击“Select”,选择“0 = input model data",按输入的气象数据内置的垂直运动模式即可。
(7)输出:轨迹结果输出目录。注意一个细节,在目录最后要加上几个字母作为这次计算的输出文件的前缀,以便下一步计算的时候识别并锁定。
(8)添加气象数据:按所要计算的时间范围选择多个气象文件。
(9)可点击“save as”保存配置文件,以便下一次使用。点击“save”保存配置。
2、运行批量计算
Hysplits 最多可以进行一个月的批量后推气流轨迹计算。
返回Hysplit主界面->“Special Runs"->“Daily”
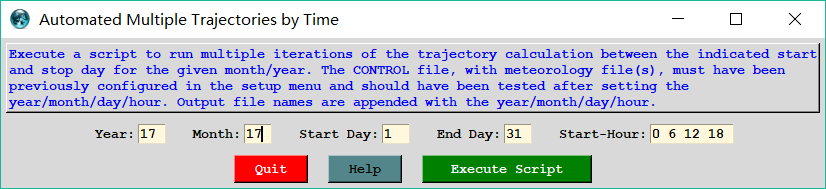
填写所需要计算的开始日期、计算的总天数(最多一个月)、每天计算的时间点。
点击“执行脚本”,稍等片刻(这时候会不断闪现对话框),直到下图出现,表示计算完成。点击“继续”。
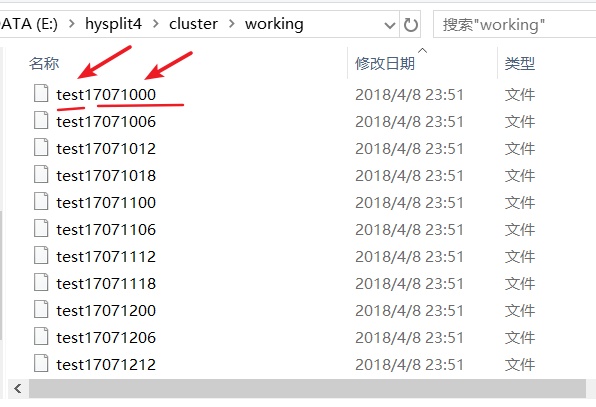
这时候在前一步配置的工作目录里会出现我们刚计算的结果,文件名结构为”前缀+年月日小时”。
三、对后退气流轨迹数据进行聚类
我们现在有多日多条的后推气流轨迹,接下来要做的就是将所有轨迹按照距离进行归类。
返回Hysplit主界面->“Special Runs"->"Clustering"->"Standard"
选择标准模式进行聚类。
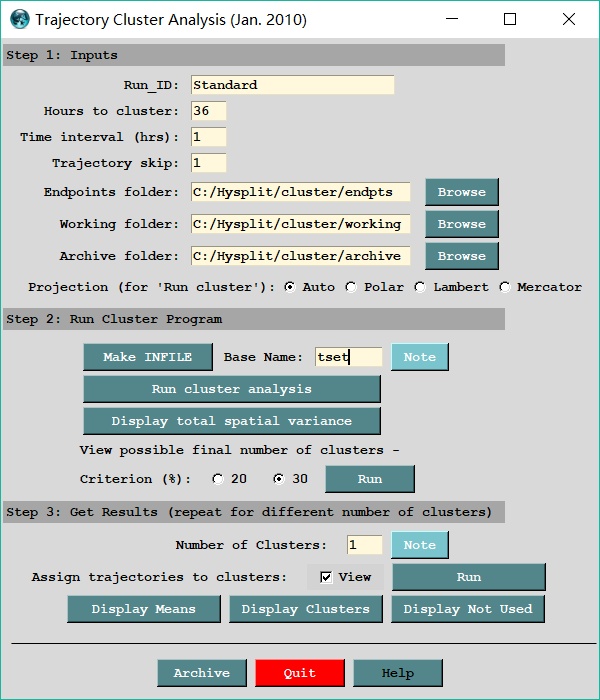
从对话框可以看到,需要进行三小步。
1、第一小步,进行配置。
需要填写以下几个选项:
(1)聚类时间:需要进行聚类的时间长度。需要注意的是,72小时的后推气流轨迹,可以只聚类前36小时。但是36小时的后推气流轨迹无法聚类72小时的。这样一说你应该能理解这个选项。
(2)聚类时间间隔:选择将轨迹划分为几段进行聚类计算。例如36小时的聚类时间+1小时的聚类时间间隔,就意味着把所有轨迹每隔1小时进行一次距离比对,共进行36小时的距离比对。
(3)轨迹间隔:简单地说就是每隔几条纳入计算范围。例如填写1,就是每一条都参加计算,填写2,就是每两条取一条进行计算。
(4)端点文件夹:选取批量计算的轨迹结果所在的文件夹。
(5)工作文件夹:输出聚类结果的文件夹。
(6)结果文件夹:当点击页面最下方的“完成”按钮后,工作文件夹的数据数据会被自动移动到结果文件夹。
2、第二小步,运行聚类程序。
首先要锁定目标轨迹文件。这时候就需要用到我们在批量输出轨迹时预先设置的文件前缀。例如上文提到我输出的批量轨迹的前缀是“test”,这里我就填写“test”。点击“MAKE INFILE”。如果成功识别锁定我们要的那批轨迹文件,会有如下提示。
点击“Run cluster analysis”,会出现如下对话框依次聚类每条轨迹,完成后点击退出即可。
接下来是最关键的步骤,确定聚类的簇数量。在操作之前先介绍一下聚类的简单原理。理解了这一原理,操作下面的步骤就易如反掌。
Hysplit聚类的原理是运行集群(所有轨迹组成的集合)从N个轨迹(簇)开始,一条一条加进去,进行类似簇的配对,直到所有轨迹都位于一个簇中。 每次迭代后,将计算总空间方差(TSV),即所有聚类空间方差的总和,并计算前一次迭代的TSV变化百分比。(迭代是后指向的,例如第一次迭代是从N到N-1,因此变化率也是,例如,cluster 10的TSV变化率是10到11的TSV与9到10的TSV差值比去9到10的TSV,理解这点很关键)。
理解以上原理后,我们来看具体操作。
确定簇的数量就是看两个指标:TSV变化图和TSV变化的变化率。
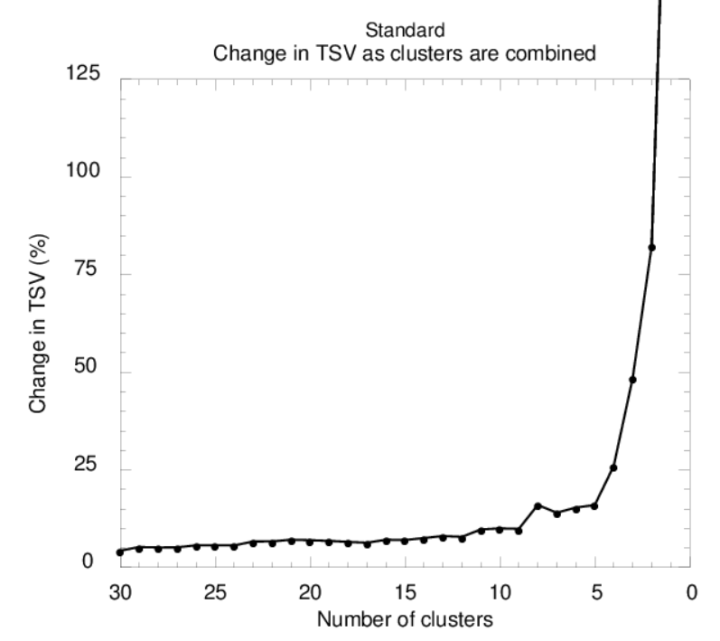
单击运行按钮“Display total spatiall variance”以生成TSV变化图。
在前几个聚类迭代中,TSV的变化非常大,那么对于大部分聚类来说,随着聚类数量的减少,TSV的增加速率通常很小,并且几乎不变。在某一时刻,TSV的变化迅速上升,表明组合的簇不是非常相似。通常会有几个较大的上升点。 在这些TSV大幅增加的点之前的聚类数量给出了可能的最终结果。
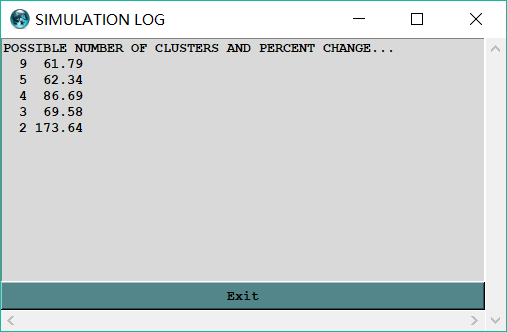
单击下图的运行按钮以生成可能的最终簇数的文本列表(CLUSEND)。

结果如下图。一列为簇数,一列为该簇数的迭代的TSV变化相对于前一个簇数的迭代的TSV变化的变化率。
通常,TSV变化率大于30%表示“不同”簇被配对了,也就是说匹配前的簇数是可能的最终结果。但是,如果30%未识别任何最终簇数,则可以使用20%的标准。如何确定呢,以下图结果为例,图中2虽然变化率很大,但是2的簇数太少,综合考虑,可以选择5条。
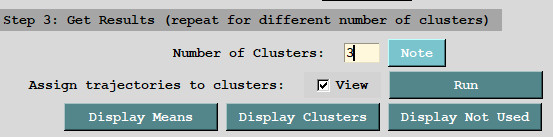
3、第三小步,获取聚类结果。
确定簇数后,我们就可以进入第三小步,进行聚类结果输出。填写我们想要的簇数,然后点击运行即可。
会出现如下运行框,完成后点击退出即可。
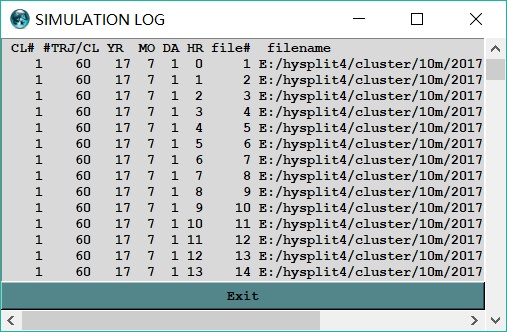
这个时候聚类就已经完成了。我们可以点击“Display Means”查看分类结果,也可以点击“Display Clusters”查看单个簇中的所有轨迹。

聚类结果会生成在working文件夹里。主要有以下几个结果文件:
(1)CLUSLIST_N (N是聚类的簇数)。
(2)C1_Nmean.tdump(簇数是多少,就会有几个这样的文件,C1_N一直到CN_N,介绍的是具体每个簇的信息)。
(3)Cmean1_N.tdump (每个簇的平均情况)。
(4)clusmean1_N(簇的分布图)。
最后一步匹配浓度的时候,需要用的文件是CLUSLIST_N 。
三、将聚类结果与污染物浓度数据结合分析
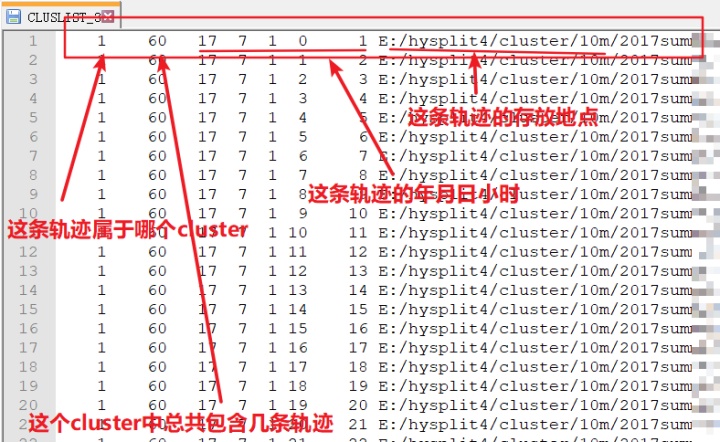
打开CLUSLIST_N文件,会见到如下的数据格式。文件中会列出聚类时间段里的所有轨迹,以及他们所属的cluster。将文件中数据用excel打开,并整理后可以得到两列,一列是cluster编号,一列是时间点组成的序列。这样我们就得到了时间点和cluster的对应信息。再把污染物浓度与时间点对应,我们就可以得到每个cluster的的污染物浓度情况。
有了cluster的数据以及相应的浓度数据,我们就可以分析气团传输机制以及污染物来源了。

















 2162
2162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









