






这里将教学视频过程规划任务转化为一个分布的拟合与采样问题,并使用条件投影扩散模型完成了这一任务。PDPP在三个不同规模的数据集以及不同的预测长度设置下都达到了最好的性能,能够生成兼具多样性与准确性的动作规划。
本文介绍我们媒体计算课题组近期被CVPR 2023接受的工作:PDPP: Projected Diffusion for Procedure Planning in Instructional Videos。针对教学视频过程规划任务的特点,PDPP将需要预测的所有动作视为一个整体的序列进行拟合,从而将该任务建模为一个特征空间分布拟合与采样问题。考虑到教学视频过程规划任务中存在的规划多样性特点,我们利用一个条件投影扩散模型来完成动作序列特征分布的拟合,通过在学习和采样阶段引入噪声实现预测的多样性。同时,我们还利用任务类别标签代替以往方法中需要的监督信息,减少了完成此任务需要的标注成本。相比于之前的SOTA方法,PDPP利用更简单的训练策略和更易获得的监督信息,在CrossTask,NIV和COIN三个数据集的指标上都取得了大幅度的提升。
论文链接:
https://arxiv.org/abs/2303.14676
教学视频过程规划任务(Procedure Planning in Instructional Videos)通过提供一段教学视频开始以及结束的视频片段,要求模型预测出这之间发生的一系列动作。之前的方法可以分为自回归式预测[1][2][3]与并行预测[4]两种。自回归式预测方法将每一个中间动作发生时对应的视频片段作为监督信号,一步步地预测接下来发生的动作和场景,从而完成整个动作序列的预测。这种方法的缺点在于预测慢,训练复杂,而且前期预测发生错误将会导致之后的预测全部失败。并行预测方法则利用一个transformer模型直接预测所有的动作。为了获得好的结果,该方法利用中间动作的文本标签作为监督信号,并引入了可学习的memory bank,GAN以及后处理策略来完成该预测任务,从而带来了复杂的训练策略与冗杂的推理过程。
过去的方法都着重于如何准确地预测每一个单独的动作,忽视了这些动作之间的关联性。因此,我们将学习目标由每一个离散的动作转化为整个动作序列,即将需要预测的动作视为一个完整的特征分布,从而将这个序列预测问题转化为一个特征拟合以及采样的问题。这样就可以直接利用MSE loss完成训练,避免了之前方法中复杂的训练策略,还可以一次预测所有的中间动作。此外,我们还注意到预测动作序列与要执行任务的类别相关度很高,例如在 "jacking up a car" 任务中,是不会出现 "add sugar" 这种动作的。因此我们提出使用任务类别标签作为监督信息,进一步减少数据标注的成本。
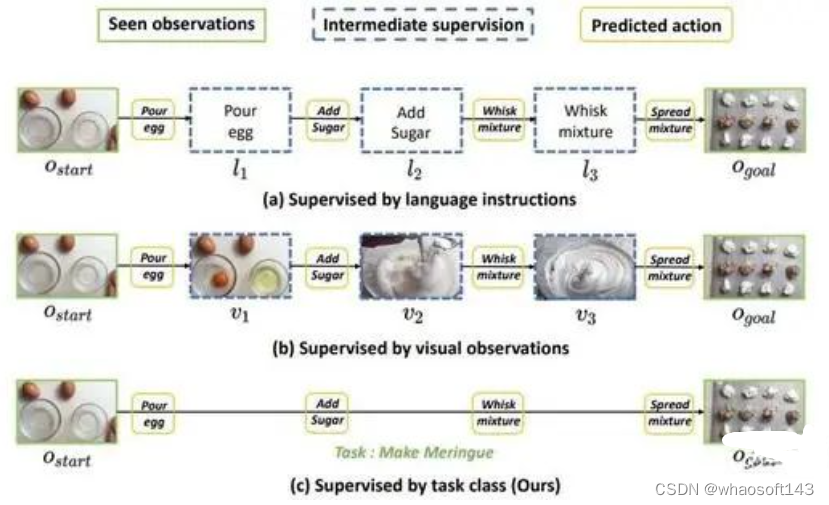
教学视频过程规划任务方法示意图
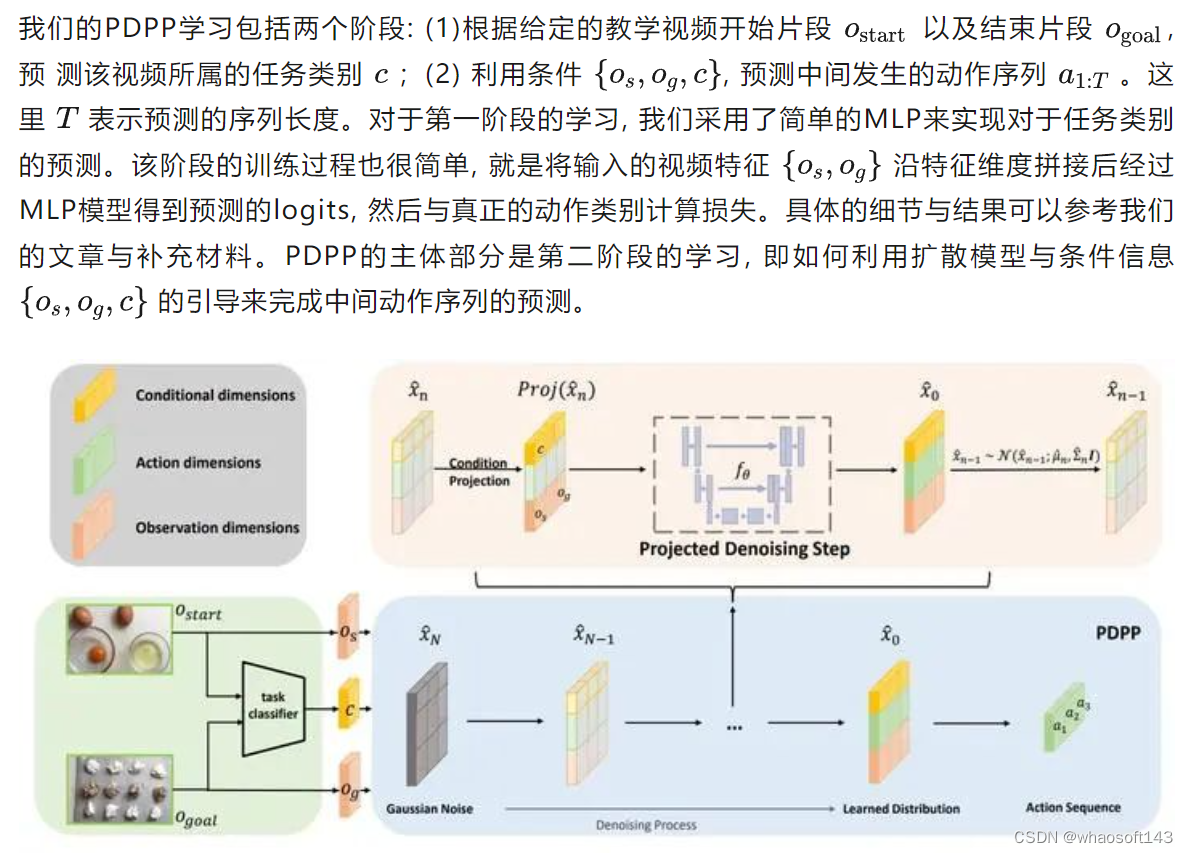
教学视频过程规划任务中还存在着规划多样性的特点,即给定教学视频开始以及结束的片段,合理的中间动作序列可以有很多。例如,在 "makingcake" 任务中,"add sugar" 与 "add butter" 两个动作发生的顺序是完全可以调换的。因此需要考虑如何实现预测的多样性。考虑到扩散模型在训练与采样过程中都会引入随机噪声,因此非常合适用来完成多样性的预测。由此,我们将教学视频过程规划任务建模为一个条件引导的分布拟合问题,并通过一个条件投影扩散模型来完成该任务。
扩散模型DDPM
在正式介绍PDPP之前,先简单回顾一下扩散模型DDPM[5]。DDPM包含前向加噪与反向去噪两个过程,分别表示为:

PDPP介绍

此外,在实验中我们发现直接预测每一步添加的噪声会导致训练失败,这与将diffusion应用到NLP任务[6]中的现象是一致的。可能的原因就是我们预测的特征分布具有很强的语义性,在去噪初期预测的噪声并不是很准确的情况下,去噪后的特征分布不具备要求的强语义性,从而导致后面的一系列去噪操作偏离正确的方向。因此,我们采用了预测初始分布 x_0x_0 的训练策略,为模型的去噪学习提供一个强的锚点。
基于以上改进思路,我们得到了PDPP的训练策略以及采样过程:

实验结果
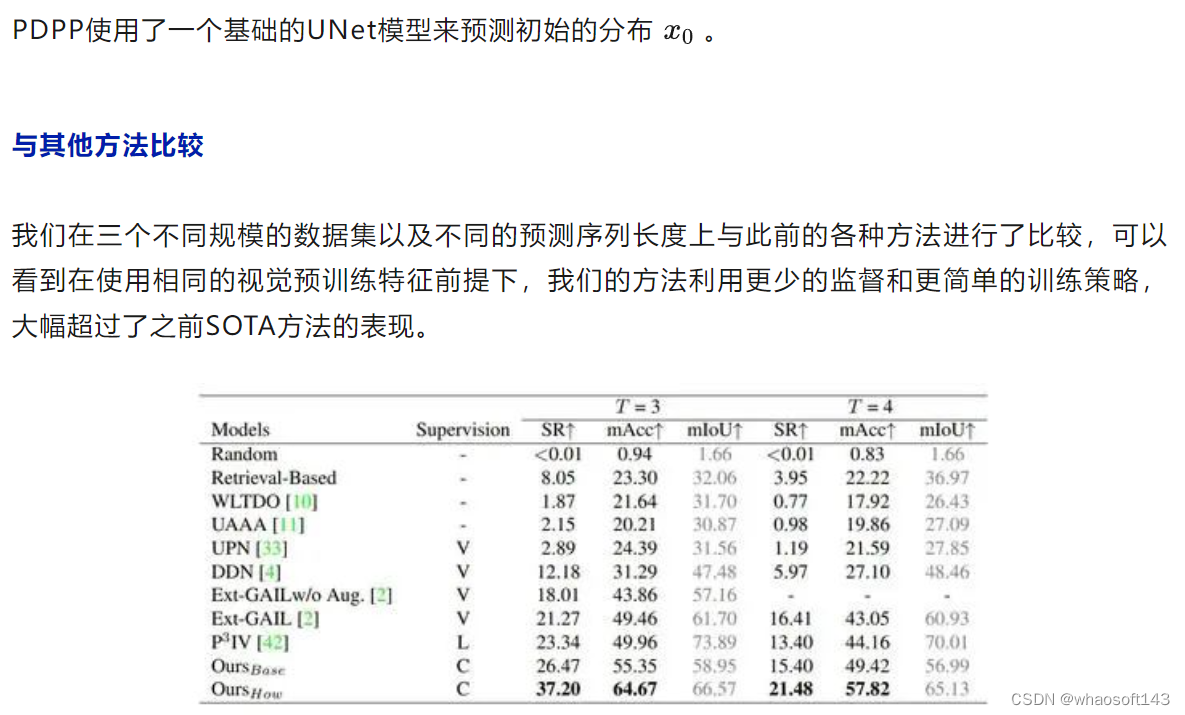

这里关于mIoU指标表现不佳的原因是因为我们在测试时选取了batch size=1,之前的方法则是在整个batch上计算得到mIoU。为了验证batch size对mIoU指标的影响,我们选取了不同的batch size对相同的模型进行了测试,发现batch size确实会大幅度影响mIoU的结果:
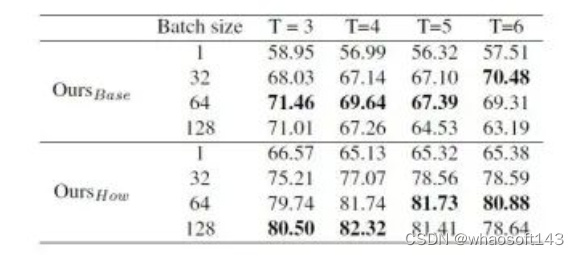
任务类别条件引导的作用
我们进一步验证了任务类别条件 c 对于预测结果的作用:
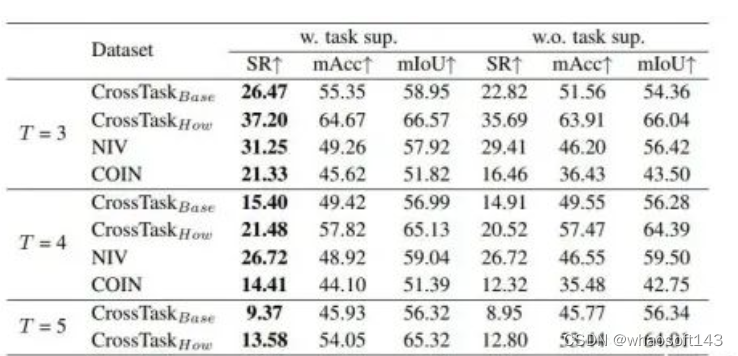
可以看到,任务类别条件能够帮助模型完成更加准确的动作规划,尤其是对于COIN这种任务类别众多、数据量大的数据集,类别条件可以大幅提高预测的准确性。同时也可以看到,即使没有类别条件的引导,我们的方法也在多个指标上达到了SOTA,进一步证明了我们方法的有效性。
规划多样性测试
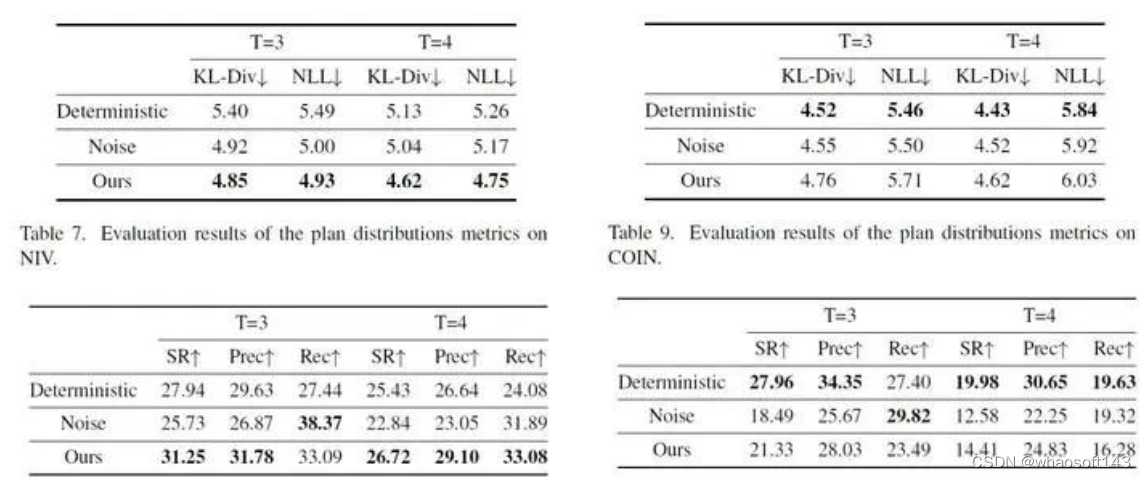
我们利用扩散模型来完成教学视频过程规划任务,希望能够适应该任务中规划多样性的特点,因此我们对于PDPP生成规划的多样性进行了测试。为了进行对比,我们提出了Noise和Deterministic两个基线方法:
- Noise:在PDPP的基础上移除diffusion过程,即学习如何从一个随机高斯噪声中根据条件信息通过一次采样得到动作序列;
- Deterministic:在Noise的基础上将采样的起始点由高斯随机噪声改为0,即直接利用条件信息生成预测的动作序列
这样,对于Noise方法,预测多样性的来源只有初始高斯噪声的随机性;而对于Deterministic方法,则完全没有预测的多样性。
我们首先统计了三个数据集拥有相同起始动作、不同中间动作的序列数目,统计结果如下:
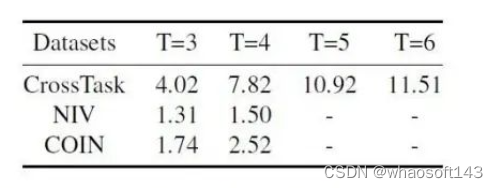
由此可以看出,CrossTask中的规划多样性是最强的,相对来说NIV与COIN的多样性就没有那么明显。
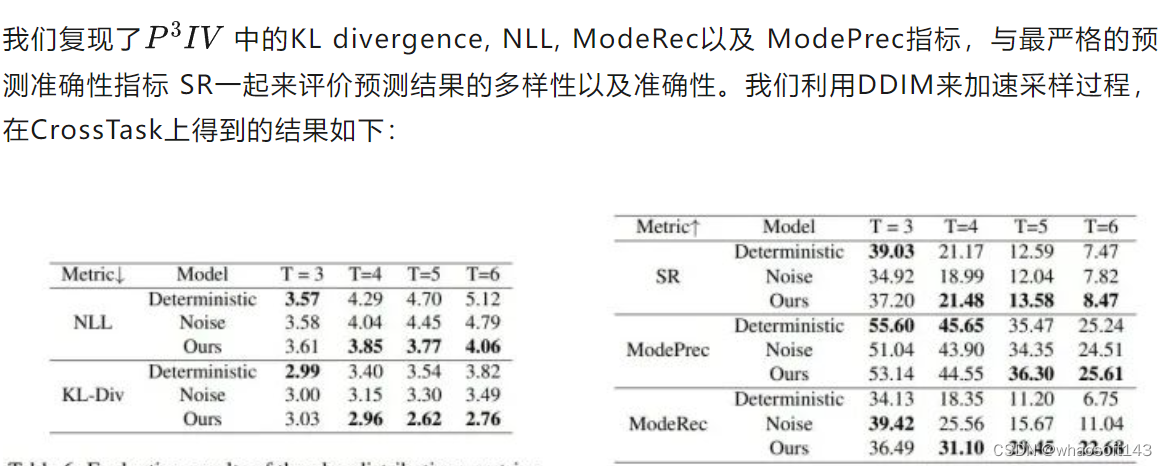
可以看到,对于CrossTask数据集,在预测长度较长时(T>3),PDPP能够给出既准确又多样的动作序列规划,其中反映预测结果多样性的指标 ModeRec 的提升最为明显。在T=3时,不添加噪声的 Deterministic 方法可以得到更准确的预测结果,这是因为在预测长度较小时,相应动作序列的多样性也会减少。
对于COIN与NIV两个多样性并不太明显的数据集,PDPP的表现完全相反:对于NIV数据集,PDPP能够兼顾预测的准确性和多样性,很好地完成动作序列的预测;而对于COIN数据集,PDPP的表现则不如不添加噪声的 Deterministic 方法。我们认为造成这种差异的原因是数据集的规模不同。对于小的数据集NIV,我们的模型能够很好地对其进行拟合,这时引入噪声起到了一种防止过拟合的作用,配合扩散模型采样的过程,就可以得到多样且准确的结果;但是对于数据量很大的COIN数据集,我们的模型还没能实现充分的拟合,这时加入噪声反而会对模型的训练起到反作用。
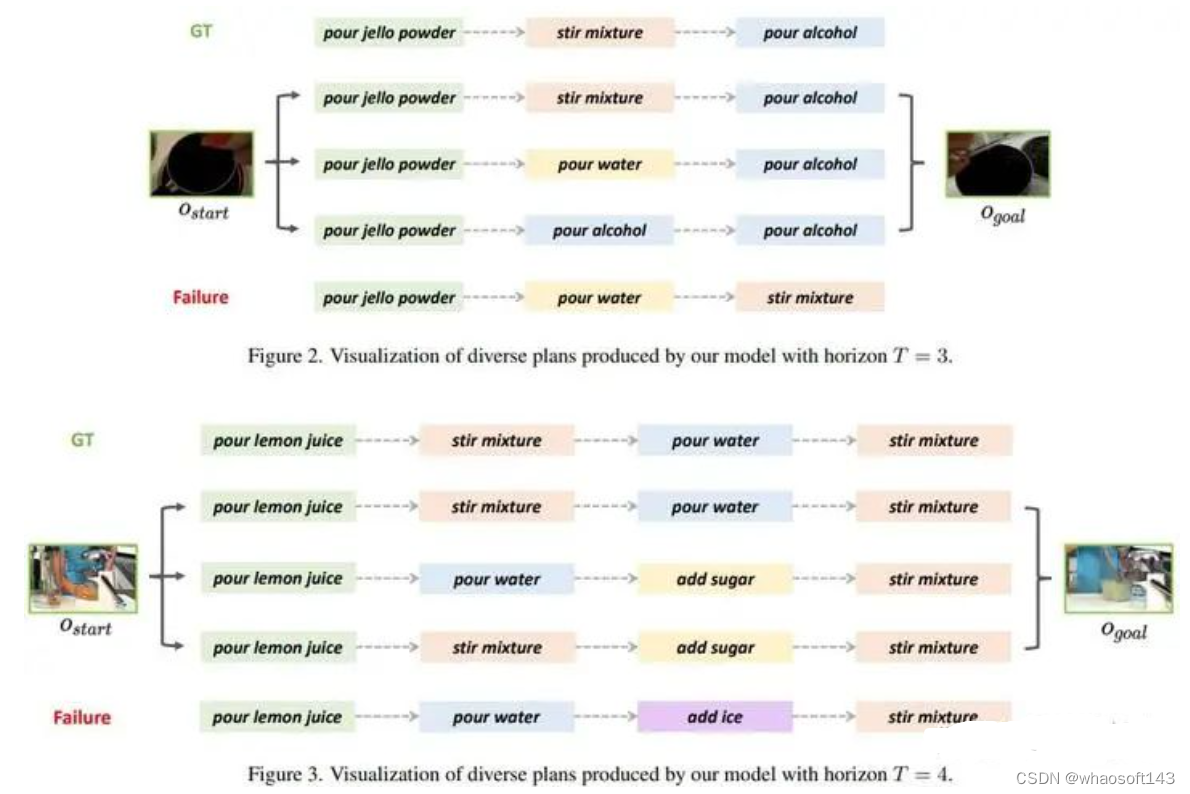
规划多样性可视化
我们将不同预测长度下的动作序列生成结果进行了可视化,可以看到PDPP能够基于给定的视频开始和结束片段生成多种合理的动作规划序列。这里的Failure结果指的只是相应的动作序列没有在测试集中出现过,但仍有一定的合理性,例如T=4时的 Failure 结果,"add ice"也是一种比较合理的中间动作。

总结
在这篇文章中,我们将教学视频过程规划任务转化为一个分布的拟合与采样问题,并使用条件投影扩散模型完成了这一任务。和之前的工作相比,PDPP需要的监督信息更少,训练的策略也简单了很多。PDPP在三个不同规模的数据集以及不同的预测长度设置下都达到了最好的性能,能够生成兼具多样性与准确性的动作规划。对于大多数指标,即使不使用任何额外的监督信息,我们的方法也能够超过之前的SOTA。我们的工作证明了对于教学视频过程规划任务,将动作序列预测问题转化为分布拟合问题是一种有效且便捷的解决方法。
参考
- ^[1]: Jing Bi, Jiebo Luo, and Chenliang Xu. Procedure planning in instructional videos via contextual modeling and modelbased policy learning. In ICCV, pages 15591–15600. IEEE, 2021.
- ^[2]: Chien-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, and Juan Carlos Niebles. Procedure planning in instructional videos. In ECCV (11), volume 12356 of Lecture Notes in Computer Science, pages 334–350. Springer, 2020.
- ^[3]: Jiankai Sun, De-An Huang, Bo Lu, Yun-Hui Liu, Bolei Zhou, and Animesh Garg. Plate: Visually-grounded planning with transformers in procedural tasks. IEEE Robotics Autom. Lett., 7(2):4924–4930, 2022.
- ^[4]: He Zhao, Isma Hadji, Nikita Dvornik, Konstantinos G. Derpanis, Richard P. Wildes, and Allan D. Jepson. P3iv: Probabilistic procedure planning from instructional videos with weak supervision. In CVPR, pages 2928–2938. IEEE, 2022.
- ^[5]: Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020.
- ^[6]: Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori B. Hashimoto. Diffusion-lm improves controllable text generation. CoRR, abs/2205.14217, 2022.















 6034
6034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









