






 本文介绍了3D打印中的CLI格式,包括文件结构、二进制与ASCII的区别以及处理二进制CLI文件的挑战。内容涉及CLI的文件头、几何信息的129、130、131三种格式,强调了数据格式开放性和处理的重要性,并分享了一个将二进制CLI转换为ASCII的Python程序。
本文介绍了3D打印中的CLI格式,包括文件结构、二进制与ASCII的区别以及处理二进制CLI文件的挑战。内容涉及CLI的文件头、几何信息的129、130、131三种格式,强调了数据格式开放性和处理的重要性,并分享了一个将二进制CLI转换为ASCII的Python程序。
1、CLI介绍
最近因为触及打印机的一些底层运作,因此必须要接触一些基础的文件格式。其中,CLI文件就是一个很有代表性、应用很广的文件格式。 这个格式存储的实际上是polygon line的坐标,是由德国人搞的。
全称叫做:Common Layer Interface (CLI)。
关于其介绍、格式见:
https://www.hmilch.net/downloads/cli_format.html
CLI一般用来存储切片过后的轮廓数据,由封闭的polygon line构成。但是实际上它不仅能存储轮廓,
也能存储路径。
怎么把STL切片成CLI呢,
详见这篇文章:
《
3D打印基本原理:扫描路径
》
各种文件格式实际上差别不是很大,拿通用的Gcode来说,它的好处是可以带参数处理。如果我们在Gcode后面附加激光功率,完全可以将之改造成振镜打印机所需要的格式。
难的不是创造一个格式,难的是让下位机能够解析你赋予的功能。例如:
G1 X10.0 Y12.0 F600 L170
如果把这段代码用在SLM机型上,则它表示的是:从当前位置扫描至(10.0,12.0),速度600mm/s,功率170W。
只要下位机将各个数字转换为振镜运动信号、激光器功率调制信号,格式就完全可用。
国内的厂商有很多就是这么干的,直接就拿Gcode加几个参数,再把它封装成二进制格式,看起来很高大上的样子,这其中有多少是根据自己对工艺的理解制定的数据格式就不知道了。
这个格式存储的实际上是polygon line的坐标,是由德国人搞的。
全称叫做:Common Layer Interface (CLI)。
关于其介绍、格式见:
https://www.hmilch.net/downloads/cli_format.html
CLI一般用来存储切片过后的轮廓数据,由封闭的polygon line构成。但是实际上它不仅能存储轮廓,
也能存储路径。
怎么把STL切片成CLI呢,
详见这篇文章:
《
3D打印基本原理:扫描路径
》
各种文件格式实际上差别不是很大,拿通用的Gcode来说,它的好处是可以带参数处理。如果我们在Gcode后面附加激光功率,完全可以将之改造成振镜打印机所需要的格式。
难的不是创造一个格式,难的是让下位机能够解析你赋予的功能。例如:
G1 X10.0 Y12.0 F600 L170
如果把这段代码用在SLM机型上,则它表示的是:从当前位置扫描至(10.0,12.0),速度600mm/s,功率170W。
只要下位机将各个数字转换为振镜运动信号、激光器功率调制信号,格式就完全可用。
国内的厂商有很多就是这么干的,直接就拿Gcode加几个参数,再把它封装成二进制格式,看起来很高大上的样子,这其中有多少是根据自己对工艺的理解制定的数据格式就不知道了。
2、CLI格式的基本结构
CLI格式由文件头($$HEADERSTART...$$HEADEREND之间的内容)、几何信息两个部分构成。这在其格式介绍里讲的非常明白,文件头里包含了如单位、模型大小、出版单位、版本等一系列的信息。需要注意的是,即使在二进制的CLI文件中,文件头一般都是以ASCII码形式存储的,一目了然。
主要需要注意的就是CLI的几何部分,它有129、130、131三种格式,区别就是用于存储坐标的字节数、数据类型不一样,单位也不太一样。不过绝大部分就是采用129格式,精度足够了。

这里有个坑,后文会讲到。
3、二进制的CLI
CLI格式可以很方面的被各种3D打印技术使用,在DLP这样的工艺里,直接就可以用作轮廓数据发送给打印机。其它的需要路径填充的,则对其进行填充后获得路径信息发送给打印机就可以了。
但是,因为ASCII文件一般比较大,所以绝大部分都是以二进制格式传播、交流。很多软件不提供导出ASCII码文件的功能,默认只能是二进制的,这其中有一份原因可能是软件厂商不愿意把自己的处理方式公布出来,亦或者有些厂商将之作为收费功能。
其实大可没有必要,数据格式必须是开放的、易于理解和处理的才能有助于行业的发展。
宝哥遇到二进制文件,也是一脸无奈,它长这样:
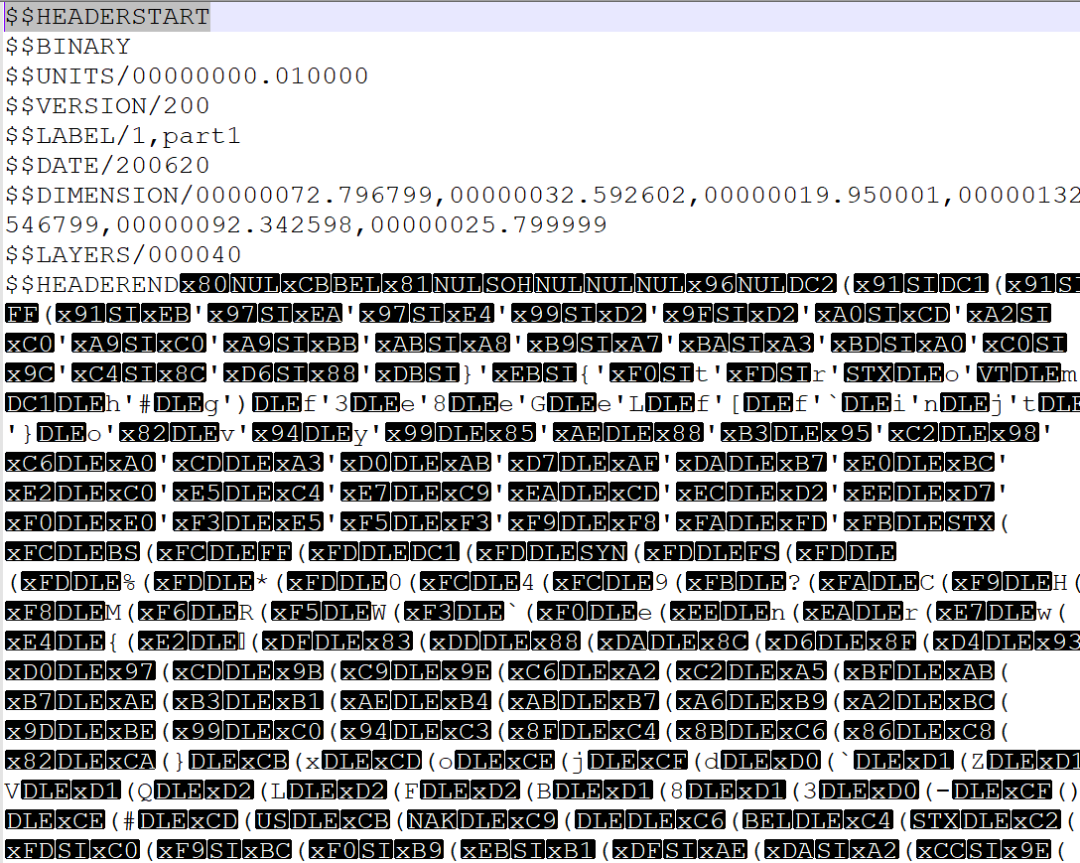
人类能读得懂文件头的ASCII码部分,后面读不懂呀!想把坐标数据拿出来处理,也做不到。
主流的软件不提供ASCII文件的导出功能,想要用还得额外购买。没办法,只能自己写转换器。
所以宝哥就花了一点时间,把二进制转ASCII的python程序写出来了,供大家使用,希望以后不要再受制于没有良心的钻钱眼里的(玩笑)厂商们。
这段代码给出的没有官方CLI的各种关键字,因为我觉得没必要,通常只需要提取内外轮廓的坐标就可以了,那么多的关键字看起来很费神。
当然,代码很容易修改,想要加上关键字也很容易。程序也很直观,只要对照官方的说明就能很容易看懂,不需要过多的解释。
class Que(): #定义一个队列的类 def __init__(self): self.L=[] def creat_que(self,num): for i in range(0,num): self.L.append(str("b'x'")) return self.L def push(self,item): #在末尾增加一个,开头删除一个,实现栈操作 self.L.append(item) self.L.pop(0) return self.L def str_head(self): st = [ item.replace("b'",'') for item in self.L] st = [ item.replace("'",'') for item in st] st = ''.join(st) return st #返回一个L合并后的字符串 def b2int(self): # 将读取到的二进制字节转化为 unsign int (2个字节) un_int, = struct.unpack("h",self.L[0]) return un_intque_headerend=Que() #实例化一个对象来处理$$HEADERENDque_headerend.creat_que(11) #创建一个包含2个元素的队列,用于寻找$$分隔符que_layer =Que() #实例化一个对象来处理$$HEADERENDque_layer.creat_que(2) #创建一个包含2个元素的队列,用于寻找128/129class Structure(): def __init__(self,f_dir,f_w): #CI,id,dir,n,p1x,p1y,... pnx,pny self.UNIT = 0 self.LAYERS = 0 self.f = f_dir self.f_ascii = f_w self.head = {} self.CI_start = 0 self.layer_thick = 0 self.CI_layer = 0 self.id = 0 self.dir = 0 self.n = 0 self.pn = [] def rep(self,byt): s = str(byt).replace("b",'') s = s.replace("'",'') return s def get_head(self): #获取文件头,返回一个字典 f = self.f byts = ' ' #d_Ls = [] while byts: #处理文件头 byts = f.read(1) que_headerend.push(str(byts)) s = que_headerend.str_head() byt = self.rep(byts) L.append(byt) if s == "$$HEADEREND": #print("$$HEADEREND FOUND!") sL = ''.join(L) sL = sL.replace("\\n",'') ''' sL = $$HEADERSTART$$BINARY$$UNITS/00000000.010000$$VERSION/200$$LABEL/1,part1$$DATE/200620$$DIMENSION /00000072.796799,00000032.592602,00000019.950001,00000132.546799,00000092.342598,00000025.799999 $$LAYERS/000040$$HEADEREND ''' Ls = sL.split("$$") ''' Ls = ['', 'HEADERSTART', 'BINARY', 'UNITS/00000000.010000', 'VERSION/200', 'LABEL/1,part1', 'DATE/200620', 'DIMENSION/00000072.796799,00000032.592602,00000019.950001,00000132.546799,00000092.342598,00000025.799999', 'LAYERS/000040', 'HEADEREND'] ''' Ls = [s for s in Ls if '/' in s] ''' Ls = ['UNITS/00000000.010000', 'VERSION/200', 'LABEL/1,part1', 'DATE/200620', 'DIMENSION/00000072.796799,00000032.592602, 00000019.950001,00000132.546799,00000092.342598,00000025.799999', 'LAYERS/000040'] ''' Ls = [item.split('/') for item in Ls] ''' Ls = [['UNITS', '00000000.010000'], ['VERSION', '200'], ['LABEL', '1,part1'], ['DATE', '200620'], ['DIMENSION', '00000072.796799,00000032.592602,00000019.950001,00000132.546799,00000092.342598,00000025.799999'], ['LAYERS', '000040']] ''' d_Ls = dict(Ls) ''' d_Ls = {'UNITS': '00000000.010000', 'VERSION': '200', 'LABEL': '1,part1', 'DATE': '200620', 'DIMENSION': '00000072.796799,00000032.592602,00000019.950001,00000132.546799,00000092.342598,00000025.799999', 'LAYERS': '000040'} ''' self.UNIT = float(d_Ls['UNITS']) self.LAYERS = int(d_Ls['LAYERS']) return d_Ls break def get_layer(self): f1 = self.f_ascii byts = ' ' byt = 0 L = [] n = 1 while byts : byts = self.f.read(2) byt_int, = struct.unpack("h",byts) if byt_int == 128: #写入128 f1.write(str(byt_int)) f1.write('\n') #写入层厚mm byts = self.f.read(2) byt_int, = struct.unpack("h",byts) f1.write(str(byt_int*self.UNIT)) f1.write('\n') elif byt_int == 129: #写入129 f1.write(str(byt_int)) f1.write('\n') #写入层厚mm byts = self.f.read(2) byt_int, = struct.unpack("h",byts) f1.write(str(byt_int*self.UNIT)) f1.write('\n') #写入内/外轮廓(0:内轮廓;1:外轮廓) byts = self.f.read(2) byt_int, = struct.unpack("h",byts) f1.write(str(byt_int)) f1.write('\n') #写入顶点的个数 byts = self.f.read(2) byt_int, = struct.unpack("h",byts) f1.write(str(byt_int)) f1.write('\n') m = 2*byt_int while m > 0: byts = self.f.read(2) byt_int, = struct.unpack("h",byts) cod = byt_int*self.UNIT cod = round(cod,2) f1.write(str(cod)) f1.write(',') m-=1 f1.write('\n')f= open('D:/py_dir/CLI/tt.cli','rb') f_ascii = open('D:/py_dir/CLI/tt1.cli','w') structure = Structure(f,f_ascii)d = structure.get_head()l = structure.get_layer()print(l)layers = structure.LAYERSf.close()f_ascii.close()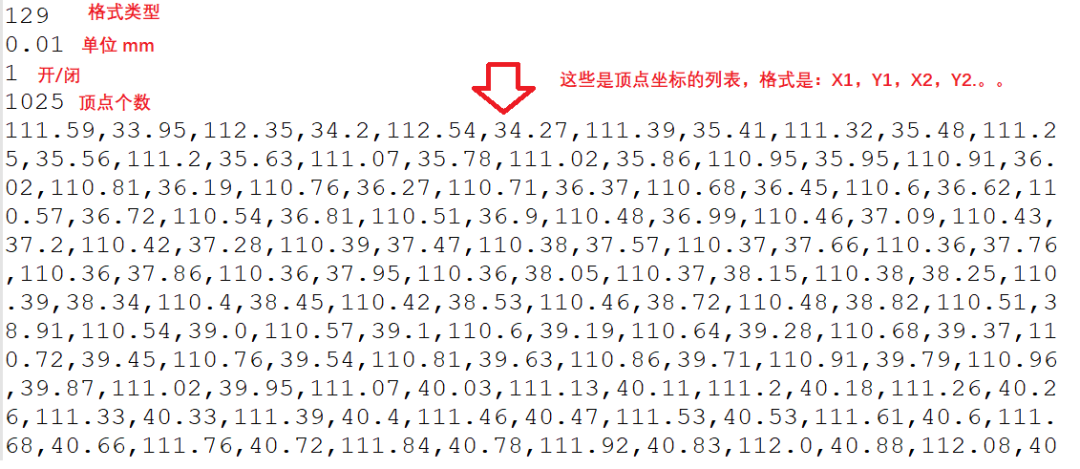 前文提到有个坑,就是129格式里的点坐标,标记的是unsigned INTEGER。对应C语言里的应该是4字节,如果按4字节就错了,实际应该是2字节的int。
掉这个坑爬了好久,当然也有可能是Magics这样的软件作者私自改了标准格式。各个厂家标新立异,不按照标准格式来,实际上对形成整体发展规则非常不利。
前文提到有个坑,就是129格式里的点坐标,标记的是unsigned INTEGER。对应C语言里的应该是4字节,如果按4字节就错了,实际应该是2字节的int。
掉这个坑爬了好久,当然也有可能是Magics这样的软件作者私自改了标准格式。各个厂家标新立异,不按照标准格式来,实际上对形成整体发展规则非常不利。
 最后补充一张结构图:
最后补充一张结构图:


















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









