






“ 数据统计分析的前奏--数据整理”
导入R studio中的数据文件是以数据框(data.frame)形式呈现的,通俗理解的话,数据框就是常说的表格,数据框具有行和列的二维结构,每一列长度相等,同一列的数据类型一致(R中常见的三种数据类型为:数值型numeric,字符型character,逻辑型logical),不同的列的数据类型可以不一样
[1]
。
现就数据整理的练习做个笔记。首先进行数据导入,数据导入有多种方式,详见笔者上一篇推文
R数据读取和保存
。首先打开R studio,键入read.csv()命令,再通过file.choose()调出复选框,通过文件目录选择导入的文件。
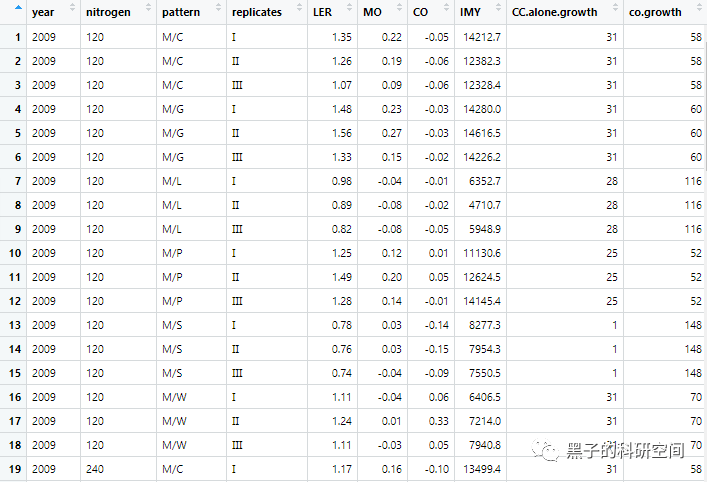 *数据较大,这里只能通过截图呈现部分数据。
1 查看数据
*数据较大,这里只能通过截图呈现部分数据。
1 查看数据

 4 数据提取
这里通过dplyr包来实现。
4 数据提取
这里通过dplyr包来实现。
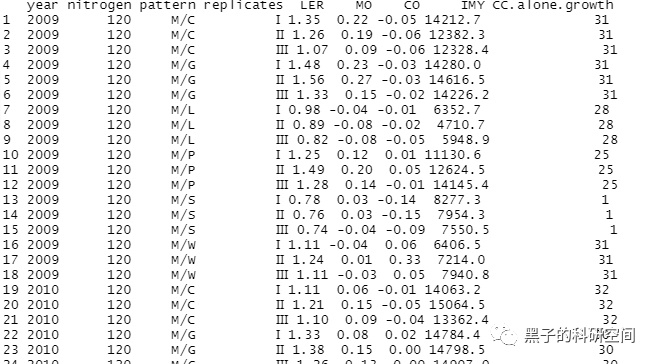

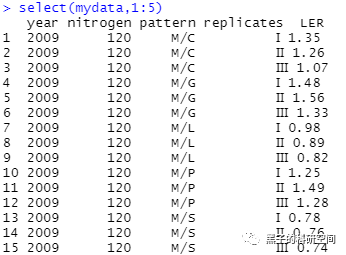
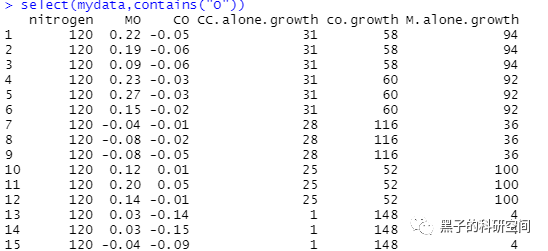
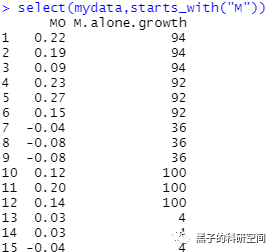 5 数据排序
5 数据排序
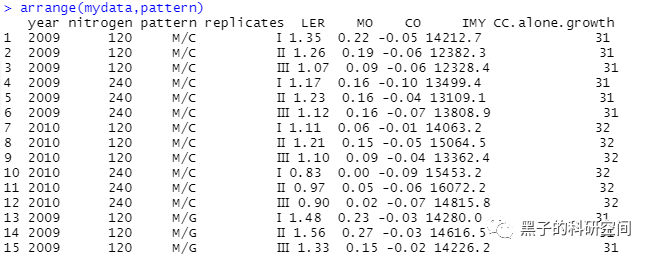
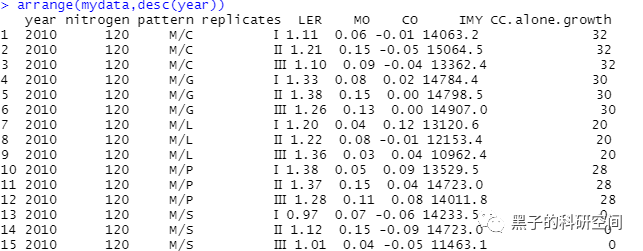 以上是本人此次数据整理练习的笔记,学习过程中了解到,有些操作的实现不只是一种方法的,本文只是用到了其中的一小部分。
实际上以我个人的理解,数据整理的这部分工作可以通过Excel完成,也就是说在Evcel中对想要的数据进行整理后再转换成csv或者txt格式导入R即可。岂不是也很方便。
当然,数据的整理也是R的基本操作,学习R就在于实际操作,所以以后还是要熟练掌握并运用这些基本操作才能对R驾轻就熟。
参考文献:
[1] R 数据框 (https://www.runoob.com/r/r-data-frame.html)
以上是本人此次数据整理练习的笔记,学习过程中了解到,有些操作的实现不只是一种方法的,本文只是用到了其中的一小部分。
实际上以我个人的理解,数据整理的这部分工作可以通过Excel完成,也就是说在Evcel中对想要的数据进行整理后再转换成csv或者txt格式导入R即可。岂不是也很方便。
当然,数据的整理也是R的基本操作,学习R就在于实际操作,所以以后还是要熟练掌握并运用这些基本操作才能对R驾轻就熟。
参考文献:
[1] R 数据框 (https://www.runoob.com/r/r-data-frame.html)
#导入数据,这里是通过选择文件file.choose()导入csv格式的数据文件。mydata #查看数据前6行head(mydata)
#查看全部数据print(mydata)
#查看数据结构str(mydata)
# 重命名9、10、11列的列名colnames(mydata)[9:11] "CCAG",
# 删除第3列,可以看到pattern列没有了mydata[,-3]# 删除第3行数据mydata[-3,]
# 提取第3行mydata[3,]
# 提取第3列mydata[,3]
# 提取1到3行的数据mydata[1:3,]
# 提取1到3列的数据mydata[,1:3]
# 创建新的列New # 创建新的数据框mydata2mydata2 
# 创建行rowrow # 添加row到mydata,形成新的数据框mydata3mydata3 
# 增加1列,列名为New,新增的列是LER列和MO列的和transform(mydata,New=LER+MO)# 调用dplyr包library(dplyr)# 选择mydata数据集中nitrogen=120的数据mydata %>% filter(nitrogen==120)# 将列LER提取出来select(mydata,LER)# 选择1到5列select(mydata,1:5)#选择列名中有字母"O"的列select(mydata,contains("O"))#选择列名中以字母“M”开头的列select(mydata,starts_with("M"))#以列pattern进行排序arrange(mydata,pattern)#按年份以降序排列arrange(mydata,desc(year))














 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









