







 本教程介绍了如何使用Python的requests和beautifulsoup库创建和解析第一个爬虫程序,目标是抓取游戏葡萄网站的首页HTML源码。首先讲解了Python基础学习的重要性,然后逐步展示了创建爬虫文件、处理requests库的安装与使用,以及源码的解析过程,最终成功获取新闻标题和链接。
本教程介绍了如何使用Python的requests和beautifulsoup库创建和解析第一个爬虫程序,目标是抓取游戏葡萄网站的首页HTML源码。首先讲解了Python基础学习的重要性,然后逐步展示了创建爬虫文件、处理requests库的安装与使用,以及源码的解析过程,最终成功获取新闻标题和链接。

教程中的项目请跟着在pycharm中写一遍,注意查看注释内容。推荐的课外练习请自行完成,完成后再查看参考代码。
本章知识点:
- python基础
- 使用requests库发送请求
- 使用beautifulsoup解析网页源码
python基础学习
本教程爬虫开发需要python语言基础,请根据自身情况选择:
- 我是零基础:请先学习python基础教程,强烈推荐:廖雪峰的python教程。
- 重点学习章节:python基础、函数、高级特性、模块、面相对象编程、错误、调试和测试、IO编程。
- 初步了解章节:进程和线程、正则表达式、常用内建模块、常用第三方模块、virtualenv、网络编程、Web开发。这些内容十分重要,但初期涉及不多。
- 暂时跳过章节:面向对象高级编程、函数式编程、图形界面、电子邮件、访问数据库、异步IO、实战,这些内容会在Python爬虫-高级进阶系列教程涉及。
- 学习时间:2~3天。
- 我有编程基础:直接开始爬虫教程。
第一个爬虫程序:游戏葡萄
创建一个game_grape.py文件,写入代码:
from urllib import request # 导入urllib中的request模块
response= request.urlopen('http://youxiputao.com/') # 用urlopen()函数执行一次请求,地址是游戏葡萄的首页,并把返回对象赋值给response变量。
html = response.read().decode() # 从response中读取结果,解码成str类型的字符串,就是我们的html源码。
print(html) # 在控制台打印html源码。执行程序,控制台打印出首页的html源码:
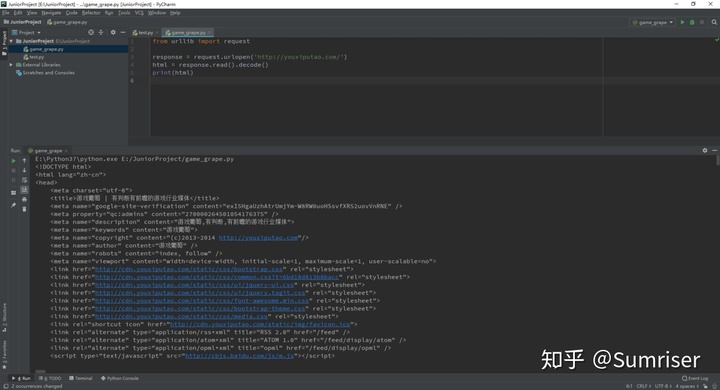
程序运行成功,超级简单有木有!
其实爬虫的本质就是: 发起请求, 获得响应, 解析结果。企业中千万级爬虫、分布式爬虫都是在这个基础上抓取得更快、存储得更多、突破各种反爬虫措施而已。
使用requests进行抓取
使用python内置的urllib包虽然可以进行抓取,但使用非常不方便,特别是面对复杂的网络请求时,使用起来会力不从心。我们来尝试用第三方网络请求工具requests重写爬虫。
import requests
response = requests.get('http://youxiputao.com/')
print(response.text)执行程序,报错:
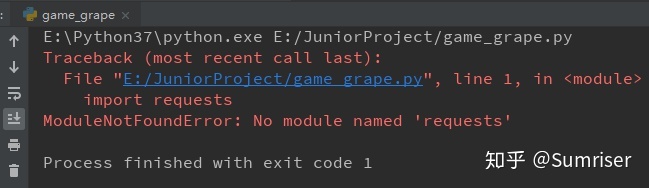
requests是第三方库,需要安装后使用:按住Win+R,输入powershell(Win10以下输入cmdÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









