






一、基本架构
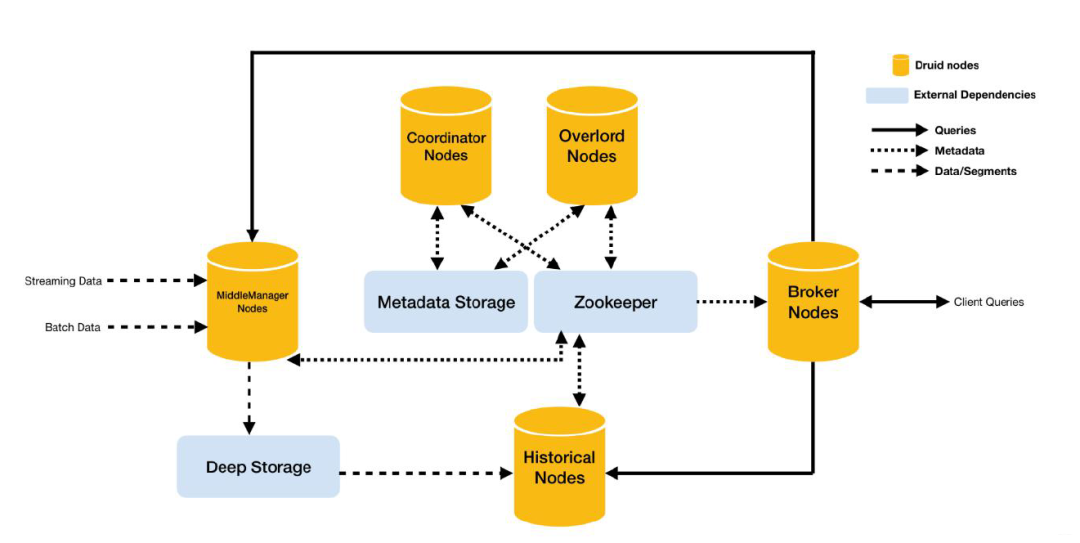
Druid 总体包含以下 5 类节点:
- 中间管理节点(middleManager node):及时摄入实时数据,已生成 Segment 数据文件。
MiddleManager 进程是执行提交的任务的工作节点。Middle Managers 将任务转发给在不同 JVM 中运行的 Peon进程(如此,可以做到资源和日志的隔离)。MiddleManager、Peon、Task 的对应关系是,每个 Peon 进程一次只能运行一个Task 任务,但一个 MiddleManager 却可以管理多个 Peon 进程。
- 历史节点(historical node):加载已生成好的数据文件,以供数据查询。historical 节点是整个集群查询性能的核心所在,因为 historical 会承担绝大部分的 segment 查询。
Historical 进程从 Deep Storage 中下载 Segment,并响应有关这些 Segment 的查询请求(这些请求来自Broker 进程)。另外,Historical 进程不处理写入请求 。Historical 进程采用了无共享架构设计,它知道如何去加载和删除 Segment,以及如何基于 Segment 来响应查询。因此,即便底层的 Deep Storage无法正常工作,Historical 进程还是能针对其已同步的 Segments,正常提供查询服务
查询节点(broker node):接收客户端查询请求,并将这些查询转发给 Historicals 和 MiddleManagers。当 Brokers 从这些子查询中收到结果时,它们会合并这些结果并将它们返回给调用者。
协调节点(coordinator node):主要负责历史节点的数据负载均衡,以及通过规则(Rule) 管理数据的生命周期。协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、 和为了负载均衡移动数据。
Coordinator 是周期性运行的(由 druid.coordinator.period 配置指定,默认执行间隔为 60s)。因为需要评估集群的当前状态,才能决定应用哪种策略,所以,Coordinator 需要维护和 ZooKeeper 的连接,以获取集群的信息。而关于 Segment 和 Rule 的信息保存在了元数据库中,所以也需要维护与元数据库的连接。
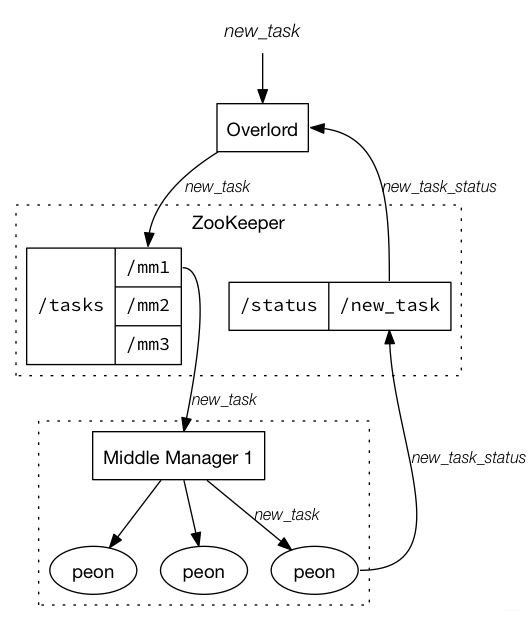
- 统治者(overlord node):进程监视 MiddleManager 进程,并且是数据摄入 Druid 的控制器。他们负责将提取任务分配给 MiddleManagers 并协调 Segement 发布,包括接受、拆解、分配 Task,以及创建 Task 相关的锁,并返回 Task 的状态。大致流程如下:
 除了上述五个节点之外,还有一个 Router 负责将请求路由到Broker, Coordinators和Overlords。
除了上述五个节点之外,还有一个 Router 负责将请求路由到Broker, Coordinators和Overlords。
- Router 进程可以在 Brokers、Overlords 和 Coordinators 进程之上,提供一层统一的 API网关。Router 进程本身是可选的,不过如果集群的数据规模已经达到了 TB级别,还是需要考虑启用的(druid.router.managementProxy.enabled=true)。因为一旦集群规模达到一定的数量级,那么发生故障的概率就会变得不容忽视,而 Router 支持将请求只发送给健康的节点,避免请求失败。同时,查询的响应时间和资源消耗,也会随着数据量的增长而变高,而 Router 支持设置查询的优先级和负载均衡策略,避免了大查询造成的队列堆积或查询热点等问题。
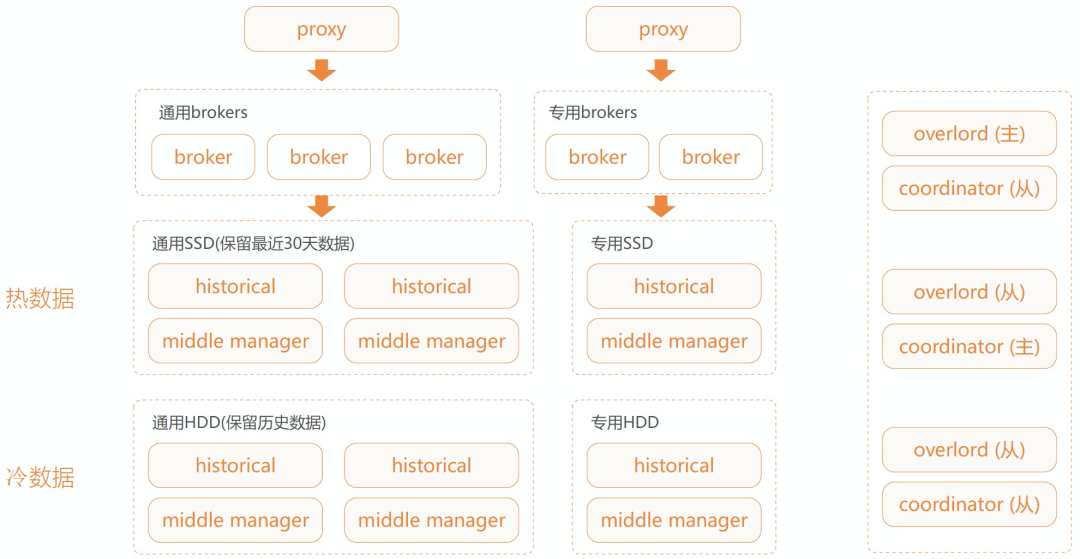
- 另外,Router 节点还可用于将查询路由到不同的 Broker 节点,便于实现冷热分层,以更好地应对超大规模数据集。默认情况下,Router 会根据设置的 Rule 规则,来路由查询请求。例如,如果将最近 1 个月的数据加载到热集群中,则最近一个月内的查询可以路由到一组专用 Broker,超出该时间范围的查询将被路由到另一组 Broker,如此便实现了查询的冷热隔离。
Apache Druid Hot-Warm 如下图:
 以上 所讲 Druid 的进程可以被任意部署,但是为了理解与部署组织方便。这些进程分为了三类:
以上 所讲 Druid 的进程可以被任意部署,但是为了理解与部署组织方便。这些进程分为了三类:
- Master: Coordinator, Overload 负责数据可用性和摄取
- Query: Broker and Router,负责处理外部请求
- Data: Historical and MiddleManager,负责实际的Ingestion负载和数据存储
二、外部依赖
同时,Druid 还包含 3 类外部依赖:
- 数据文件存储库(Deep Storage):存放生成的 Segment 数据文件,并供历史服务器下载, 对于单节点集群可以是本地磁盘,而对于分布式集群一般是 HDFS。
Druid 仅将 Deep Storage 用作数据的备份,并将其作为在 Druid 进程之间在后台传输数据的一种方式。当接受到查询请求,Historical 进程不会从 Deep Storage 读取数据,而是在响应任何查询之前,读取从本地磁盘 pre-fetched 的 Segments。这意味着 Druid 在查询期间永远不需要访问 Deep Storage,从而极大地降低了查询延迟。这也意味着,必须保证 Deep Storage 和 Historical 进程所在节点,能拥有足够的磁盘空间。
元数据库(Metadata Storage),存储 Druid 集群的元数据信息,比如 Segment 的相关信息,一 般用 MySQL 或 PostgreSQL。
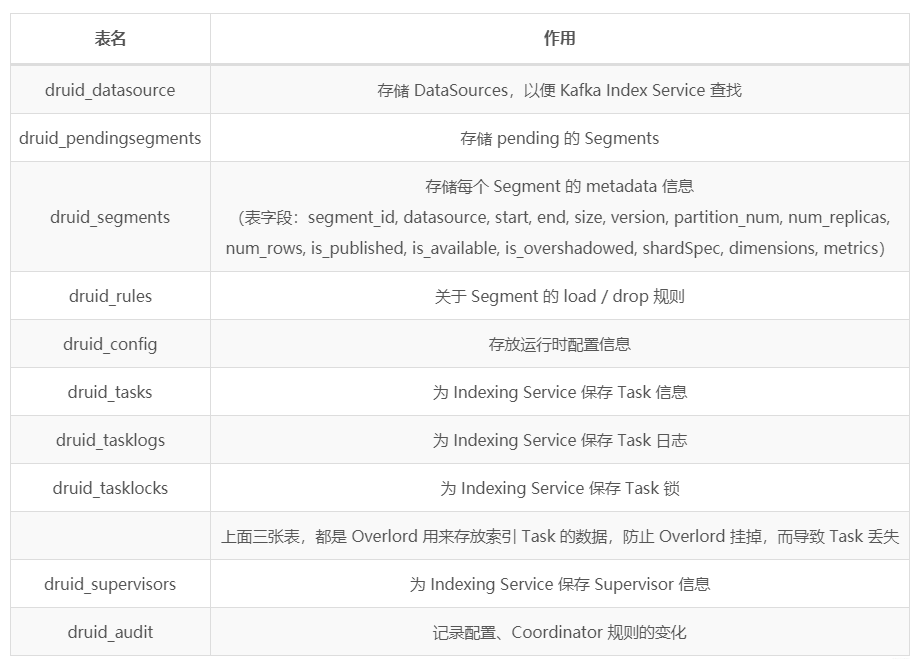
Zookeeper:为 Druid 集群提供以执行协调服务。如内部服务的监控,协调和领导者选举。
涵盖了以下的几个主要特性:Coordinator 节点的 Leader 选举 Historical 节点发布 Segment 的协议 Coordinator 和 Historical 之间 load / drop Segment 的协议 Overlord 节点的 Leader 选举 Overlord 和 MiddleManager 之间的 Task 管理
三、架构演进
设计总图
Apache Druid 初始版本架构图 ~ 0.6.0(2012~2013)
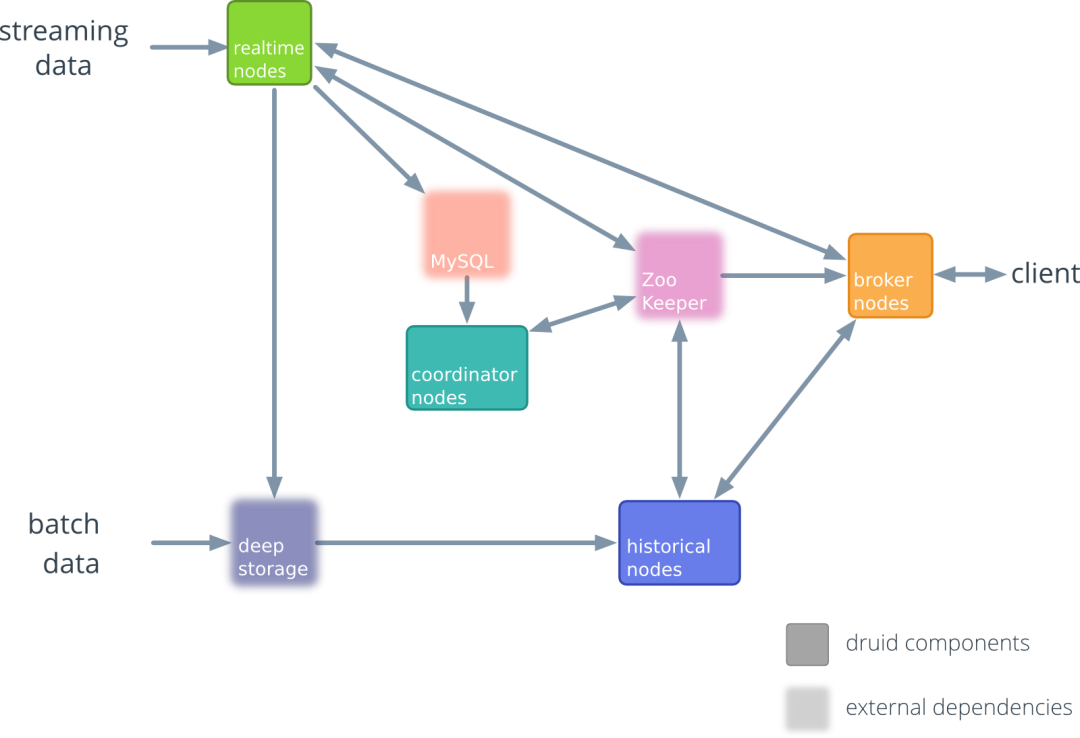
0.7.0 ~ 0.12.0(2013~2018)
Apache Druid 旧架构图——数据流转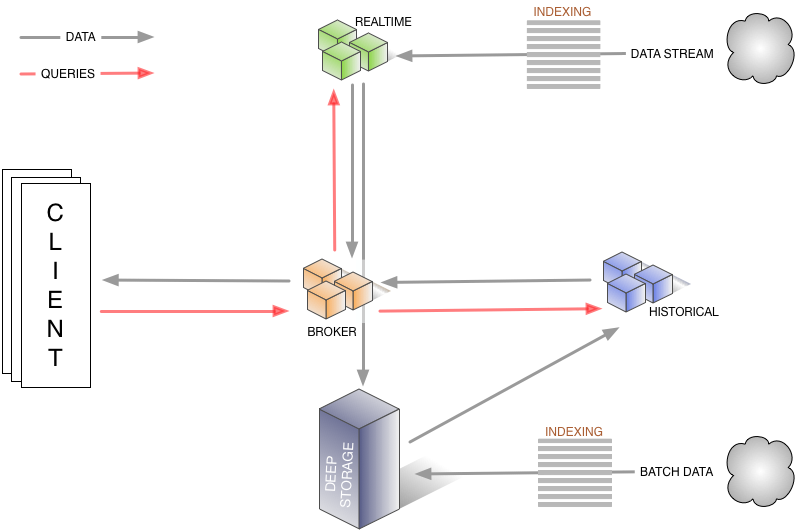 查询路径:红色箭头:①客户端向Broker发起请求,Broker会将请求路由到②实时节点和③历史节点 Druid数据流转:黑色箭头:数据源包括实时流和批量数据. ④实时流经过索引直接写到实时节点,⑤批量数据通过IndexService存储到DeepStorage,⑥再由历史节点加载. ⑦实时节点也可以将数据转存到DeepStorage
查询路径:红色箭头:①客户端向Broker发起请求,Broker会将请求路由到②实时节点和③历史节点 Druid数据流转:黑色箭头:数据源包括实时流和批量数据. ④实时流经过索引直接写到实时节点,⑤批量数据通过IndexService存储到DeepStorage,⑥再由历史节点加载. ⑦实时节点也可以将数据转存到DeepStorage
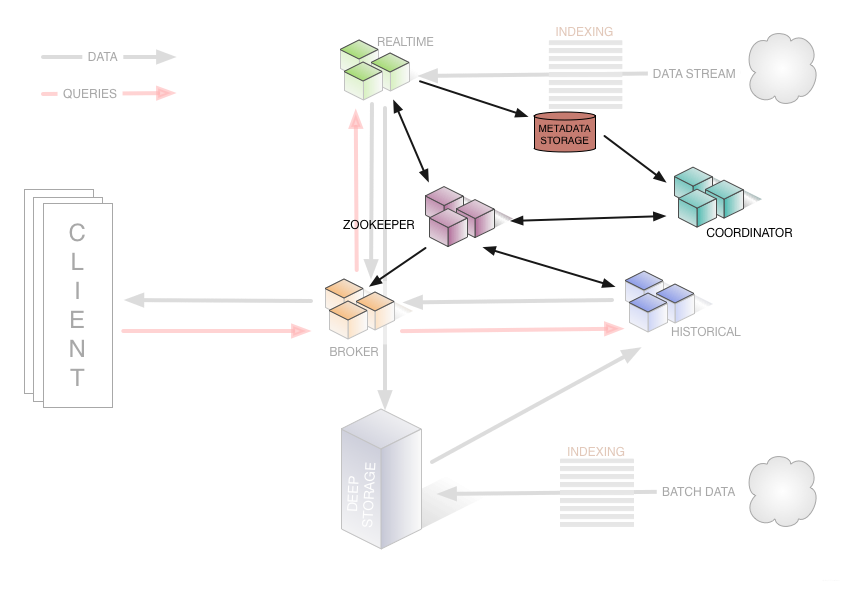
Apache Druid 旧架构图——集群管理
 0.13.0 ~ 当前版本(2018~now)
0.13.0 ~ 当前版本(2018~now)
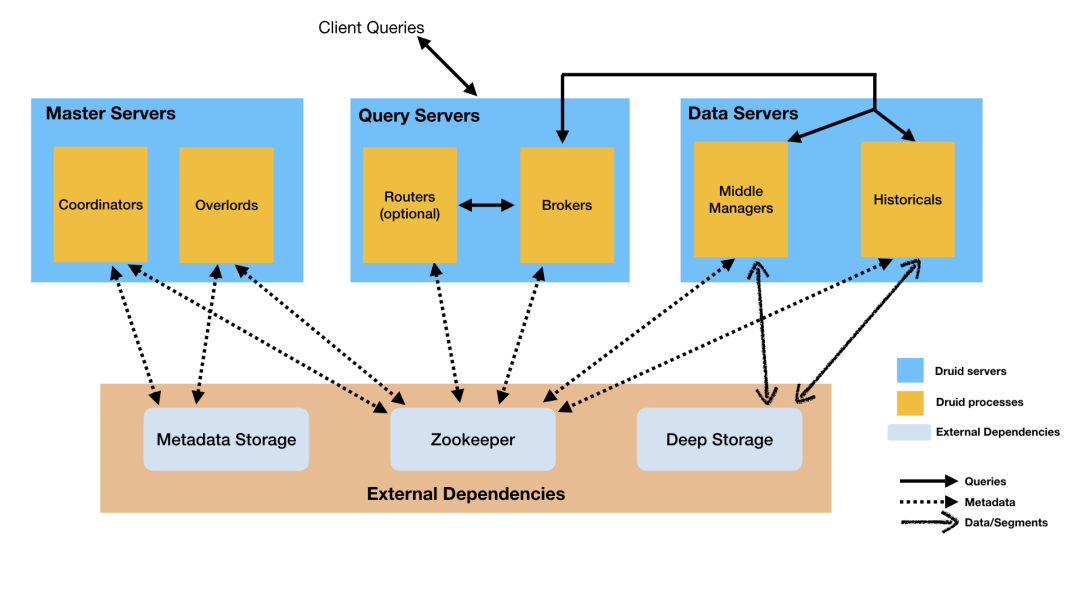
从架构图中可以看出来 Apache Druid 集群的通讯是基于 Apache ZooKeeper 的。
四、Lambda 流式架构
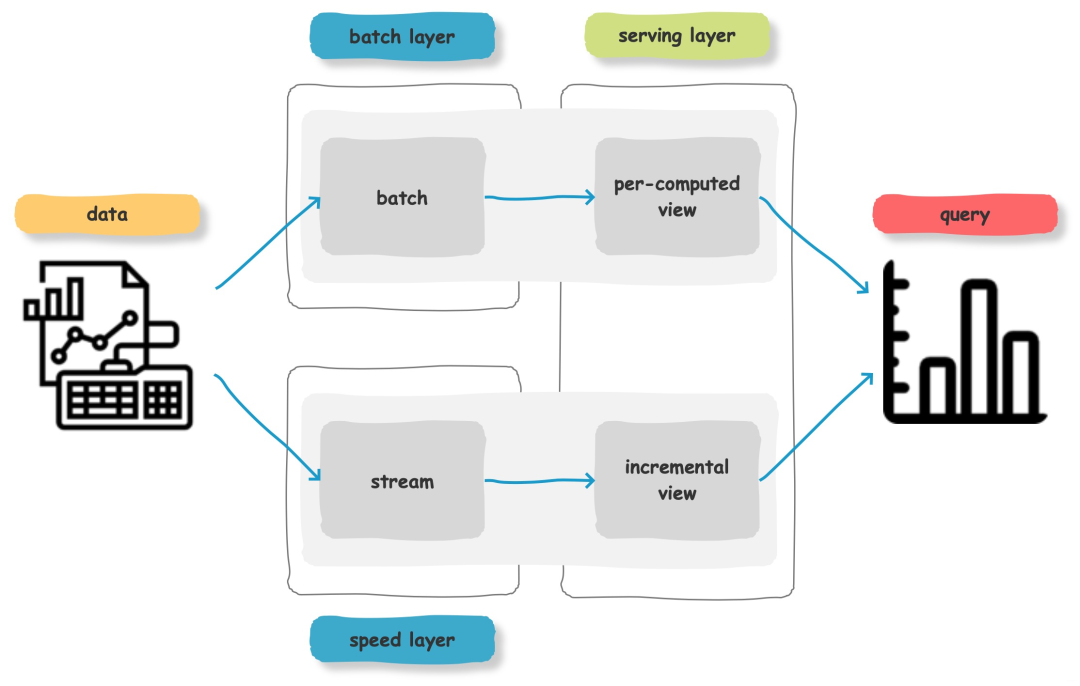
通常流式数据的链路为 Raw data → Kafka → Stream processor(optional, typically for ETL) → Kafka(optional)→ Druid → Application / user,而批处理的链路为 Raw data → Kafka(optional)→ HDFS → ETL process(optional)→ Druid → Application / user
我是「云祁」,一枚热爱技术、会写诗的大数据开发猿,Love&Peace!



Apache Druid(一)基本介绍
师兄大厂面试遇到这条 SQL 数据分析题,差点含泪而归!
从BAT大数据工程师那里总结的大数据学习方法















 2404
2404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









