






 本文介绍了如何使用WebScraper浏览器插件进行零代码爬虫,详细讲解了从创建工程、构建链接和非链接节点到运行爬虫的流程。并分享了在应对网址变化规律和不规律翻页时的处理策略,以及当网页格式不一致时,利用Ranorex Selocity增强选择器适应性的方法。
本文介绍了如何使用WebScraper浏览器插件进行零代码爬虫,详细讲解了从创建工程、构建链接和非链接节点到运行爬虫的流程。并分享了在应对网址变化规律和不规律翻页时的处理策略,以及当网页格式不一致时,利用Ranorex Selocity增强选择器适应性的方法。

背景
我是一个Python的老玩家了,但是爬虫这方面一直不太熟练,一两年前系统地学习过一次没学会,半年前为了动态监控一个小网站的内容,磕磕绊绊地跟着教程重新做了一遍,最终是把东西做出来了,但是确实还是有些麻烦。
最近因为要一次性地爬取一个学术会议的公开论文的下载链接,所以估计得重新做一个爬虫。但是因为对写爬虫代码感到“窒息般的恐惧”,所以搜索了一下有没有零代码的爬虫解决方法,结果还真被我找到了一个。跟着英文演示视频,十分钟就搞定了,真是爽到飞起~
这个工具就是我们今天得主角:WebScraper
WebScraper
是什么:是一个浏览器插件,能够让你通过简单的操作,就能实现一个爬虫的功能。基础版的是免费的,对于大部分个人用户肯定也够用了。
大致流程:先简单地在插件中创建一个爬虫工程,然后可视化地构建链接节点和非链接节点,最后点击运行,就可以开始爬取。
节点?:链接节点的功能是为了描述网页结构,以及跟踪链接跳转。而非链接节点的功能就是为了获取数据啦~
为了保险:构建完节点之后,还支持节点图结构展示,以及每个节点数据的预览,保证你对自己的节点自信慢慢,或者发现错误也能及时纠正。
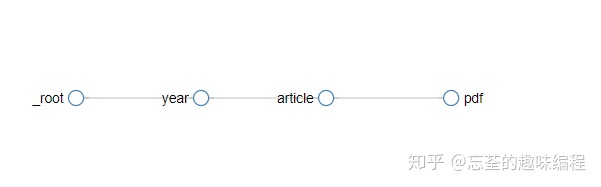
详细教程
官网:链接
中文教程:WebScraper中文文档(不是我写的,只是刚好查到的):
WebScraper中文文档webscraper.topB站上也有一些中文的相关教学视频,请自行前往~
2020.10.22更新
最近两天我大量地使用了WebScraper,收货比较多,特地前来分享一下自己的学习笔记。主要参考的是这个链接:
Web Scraper 官方教程 #3 —— 分页处理【中英双语字幕】_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com
因为这次我爬取的几个网站的形式也都是“翻页+每页都是一个项目列表”形式的,而上面的视频的内容也刚好是官方介绍的对这种组织形式的网页的爬取。视频中一共有三种形式,从易到难分别对应了三种不同的情况。
- 翻页的时候网址会变化,且网址变化有规律 -> 在start url 中将网址中变化部分使用中括号里面的数字表示。如[1-23]表示这个位置的值要依次选1到23。
- 翻页的时候网址会变化,但网址变化没有规律 -> 使用link元素将各页串联起来(两种串联方法。一种是从第一页开始,只给“下一页”的按钮打上link标记;另外一种是从任意一页开始,并给所有翻页相关的按钮打上link标记)
- 翻页的时候网址不会变化 -> 使用 Element Click。注意Element Click是一种Element ,所以用了Element Click之后就不用再用Element重新组织元素了(Element有点“容器”的意思,是为了产生要爬取的数据的分组结构,从而描述清楚数据爬取的逻辑)。
哈哈,可能直接看不容易看懂。强烈建议去看一下上面的视频链接哦~
最后推荐一下,如果遇到特别长的网址,需要看翻页的时候网址有没有变化的时候,可以使用一些在线的文本对比工具:

2020.10.26 更新 :
使用Ranorex Selocity插件为WebScraper生产更高质量的元素选择器
今天遇到了一个格式特别乱的网站,看目录页明明排列的很整齐:

但是每项点进去后,发现各个网页都有细微的差别。不管这些网页中的哪些页面使用web scraper选择你想要的数据,最后都发现只能得到一小部分页面的数据,而其他页面的数据不是错误的就是空的,真的是让人非常恼火。后来我分析原因,发现是web scraper的选择器的适应性太弱,有时候甚至在哪页做出来的,就只能抓哪一页的数据,效果奇差。
所以最后还是找到了解决办法:我先查了一下web scraper的选择器的格式,发现它使用的是CSS选择器,详情参考:
CSS selector | Web Scraper Documentationwebscraper.io然后我就在chrome的插件商店里面,找到了一个最受欢迎的CSS选择器自动生成插件Ranorex Selocity。安装了该插件后,只需要选中自己想要的网页元素,然后右键后在右键菜单选“检查”,最后在Element页的Ranorex Selocity选项卡中,就能够找到最适合该元素的选择器:
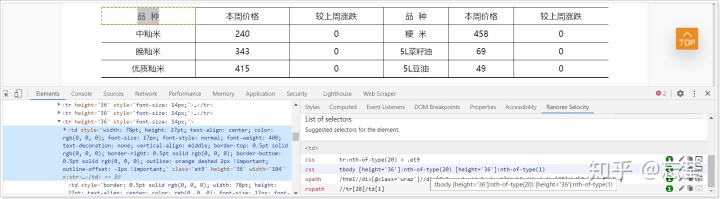
通过这种方式得到的选择器更加可靠,能够帮助你在低质量或者格式不太统一的一些网页中,顺利找到自己想要的数据。
(安装该插件之后,鼠标点击该插件就能看到使用步骤说明和配套动图,非常地贴心,我就是看着这个一步步做的,非常简单流畅):















 3279
3279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









