







第二篇
前面实现了一个最基础的爬取单网页的爬虫,这一篇则着手解决深度爬取的问题
简单来讲,就是爬了一个网页之后,继续爬这个网页中的链接
1. 需求背景
背景比较简单和明确,当爬了一个网页之后,目标是不要就此打住,扫描这个网页中的链接,继续爬,所以有几个点需要考虑:
哪些链接可以继续爬 ?
是否要一直爬下去,要不要给一个终止符?
新的链接中,提取内容的规则和当前网页的规则不一致可以怎么办?
2. 设计
针对上面的几点,结合之前的实现结构,在执行 doFetchPage 方法获取网页之后,还得做一些其他的操作
扫描网页中的链接,根据过滤规则匹配满足要求的链接
记录一个depth,用于表示爬取的深度,即从最原始的网页出发,到当前页面中间转了几次(讲到这里就有个循环爬取的问题,后面说)
不同的页面提取内容规则不一样,因此可以考虑留一个接口出来,让适用方自己来实现解析网页内容
基本实现
开始依然是先把功能点实现,然后再考虑具体的优化细节
先加一个配置项,表示爬取页面深度; 其次就是保存的结果,得有个容器来暂存, 所以在 SimpleCrawlJob 会新增两个属性
/**
* 批量查询的结果
*/
private List crawlResults = new ArrayList<>();
/**
* 爬网页的深度, 默认为0, 即只爬取当前网页
*/
private int depth = 0;
因为有深度爬取的过程,所以需要修改一下爬取网页的代码,新增一个 doFetchNetxtPage方法,进行迭代爬取网页,这时,结果匹配处理方法也不能如之前的直接赋值了,稍微改一下即可, 改成返回一个接过实例
/**
* 执行抓取网页
*/
public void doFetchPage() throws Exception {
doFetchNextPage(0, this.crawlMeta.getUrl());
this.crawlResult = this.crawlResults.get(0);
}
private void doFetchNextPage(int currentDepth, String url) throws Exception {
HttpResponse response = HttpUtils.request(new CrawlMeta(url, this.crawlMeta.getSelectorRules()), httpConf);
String res = EntityUtils.toString(response.getEntity());
CrawlResult result;
if (response.getStatusLine().getStatusCode() != 200) { // 请求成功
result = new CrawlResult();
result.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase());
result.setUrl(crawlMeta.getUrl());
this.crawlResults.add(result);
return;
}
result = doParse(res);
// 超过最大深度, 不继续爬
if (currentDepth > depth) {
return;
}
Elements elements = result.getHtmlDoc().select("a[href]");
for(Element element: elements) {
doFetchNextPage(currentDepth + 1, element.attr("href"));
}
}
private CrawlResult doParse(String html) {
Document doc = Jsoup.parse(html);
Map> map = new HashMap<>(crawlMeta.getSelectorRules().size());
for (String rule : crawlMeta.getSelectorRules()) {
List list = new ArrayList<>();
for (Element element : doc.select(rule)) {
list.add(element.text());
}
map.put(rule, list);
}
CrawlResult result = new CrawlResult();
result.setHtmlDoc(doc);
result.setUrl(crawlMeta.getUrl());
result.setResult(map);
result.setStatus(CrawlResult.SUCCESS);
return result;
}
说明
主要的关键代码在 doFetchNextPage 中,这里有两个参数,第一个表示当前url属于爬取的第几层,爬完之后,判断是否超过最大深度,如果没有,则获取出网页中的所有链接,迭代调用一遍
下面主要是获取网页中的跳转链接,直接从jsoup的源码中的example中获取,获取网页中链接的方法
// 未超过最大深度, 继续爬网页中的所有链接
result = doParse(res);
Elements elements = result.getHtmlDoc().select("a[href]");
for(Element element: elements) {
doFetchNextPage(currentDepth + 1, element.attr("href"));
}
测试case
测试代码和之前的差不多,唯一的区别就是指定了爬取的深度,返回结果就不截图了,实在是有点多
/**
* 深度爬
* @throws InterruptedException
*/
@Test
public void testDepthFetch() throws InterruptedException {
String url = "https://my.oschina.net/u/566591/blog/1031575";
CrawlMeta crawlMeta = new CrawlMeta();
crawlMeta.setUrl(url);
SimpleCrawlJob job = new SimpleCrawlJob(1);
job.setCrawlMeta(crawlMeta);
Thread thread = new Thread(job, "crawlerDepth-test");
thread.start();
thread.join();
List result = job.getCrawlResults();
System.out.println(result);
}
3. 改进
问题
上面虽然是实现了目标,但问题却有点多:
就比如上面的测试case,发现有122个跳转链接,顺序爬速度有点慢
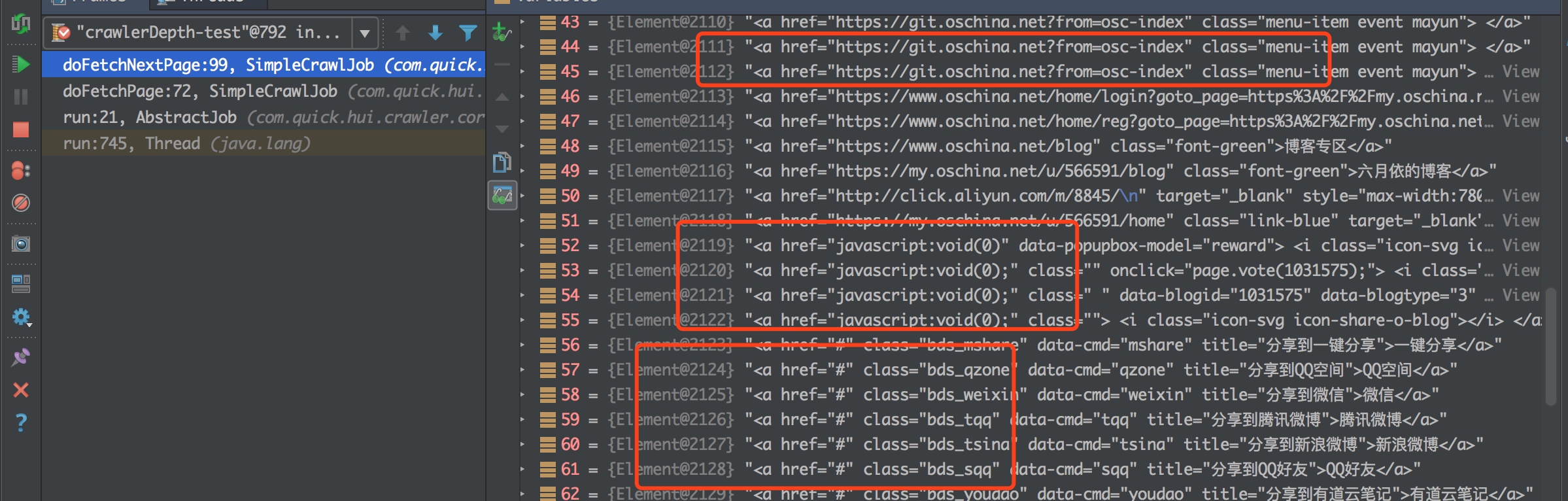
链接中存在重复、页面内锚点、js等各种情况,并不是都满足需求
最后的结果塞到List中,深度较多时,链接较多时,list可能被撑暴
- 添加链接的过滤
过滤规则,可以划分为两种,正向的匹配,和逆向的排除
首先是修改配置类 CrawlMeta, 新增两个配置
/**
* 正向的过滤规则
*/
@Setter
@Getter
private Set positiveRegex = new HashSet<>();
/**
* 逆向的过滤规则
*/
&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









