







简介:网站架构设计是构建高效、可扩展且可靠在线服务的核心。本文集合了123篇关于Facebook、Google和Amazon的架构设计文章,涵盖了这些互联网巨头的核心架构理念、技术栈、演化历程以及面临的挑战和解决方案。Facebook以社交网络为核心,采用了动态内容分发网络(CDN)、大数据处理框架(Hadoop/Spark)、缓存系统(Memcached)、分布式NoSQL数据库(Cassandra)和HHVM虚拟机。Google以搜索和广告业务为主,使用MapReduce并行计算模型、Bigtable分布式列式数据库、GFS分布式文件系统、Chubby锁服务和Borg集群管理系统。Amazon作为电商和云计算的领军者,其架构设计特点包括弹性计算云(EC2)、简单存储服务(S3)、亚马逊简单队列服务(SQS)、CloudFront内容分发网络服务和DynamoDB NoSQL数据库服务。这些架构设计和实践对于构建可扩展、容错性强、响应迅速的大型网站以及利用云计算和分布式系统解决实际问题具有重要价值。 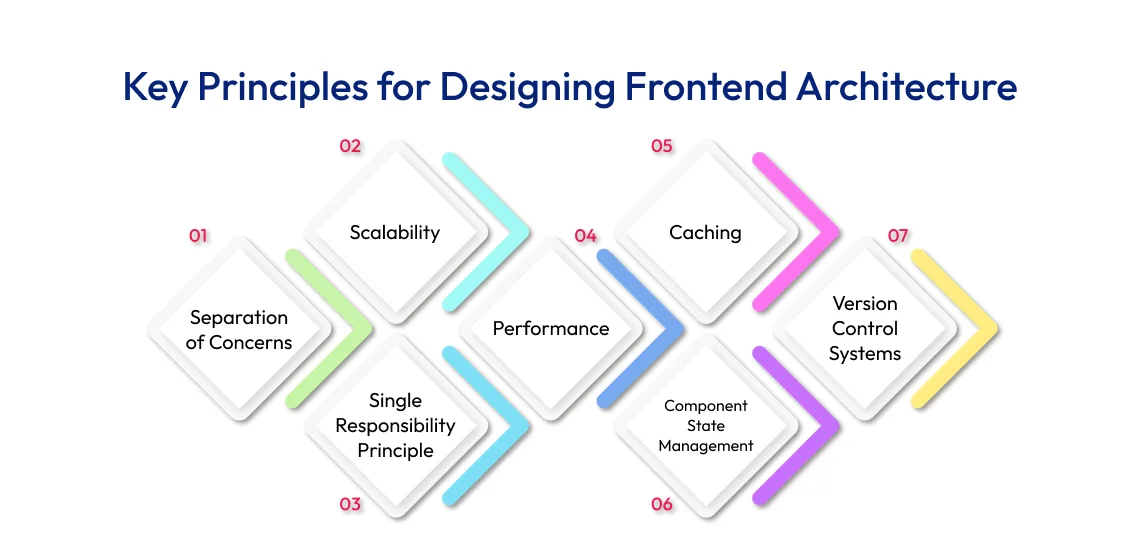
1. 网站架构设计的重要性
在当今的数字化时代,网站架构设计不仅仅是技术实现的基础,它更是企业竞争力的体现。一个优秀的架构设计能够确保网站的高性能、良好的可扩展性、高级别的安全性和易于维护性。这些因素直接影响用户体验和企业的市场表现。
理论基础
网站架构设计的核心价值在于提供一个稳定的平台,确保用户能够快速访问网站内容。这涉及到前端和后端服务的协同工作,以及如何通过合理的资源分配和负载均衡来实现高可用性。
基本原则
在设计网站架构时,需要遵循几个基本原则:
- 性能 :优化加载时间和响应速度,减少延迟。
- 可扩展性 :能够根据需求动态调整资源,适应流量波动。
- 安全性 :保护网站不受攻击,保障用户数据安全。
- 维护性 :简化系统升级和故障排除流程。
总结
通过深入理解网站架构设计的重要性,并遵循其基本原则,可以为企业构建一个强大且灵活的网络平台,为用户和业务创造更多价值。接下来的章节将深入探讨各大互联网公司的核心架构理念与技术栈,以及如何将这些理论应用于实践。
2. Facebook核心架构理念与技术栈
2.1 Facebook架构理念概述
2.1.1 社交网络的特殊需求
社交网络平台如Facebook,其架构设计理念受到其业务模式的特殊需求所驱动。社交网络的用户基数庞大,且用户行为模式多样,需要一个能够处理海量用户请求、保证高可用性、支持复杂社交互动和数据处理的强大架构。
在本章节中,我们将探讨Facebook如何通过其核心架构理念来满足这些特殊需求。
首先,Facebook的架构设计必须能够处理高并发的用户访问。社交网络用户的活跃度往往集中在特定时间段,如节假日、大型事件或热门话题事件期间,这种现象被称为“流量峰值”。因此,Facebook需要设计一个能够应对瞬时高流量的系统,确保用户不会因为访问量过大而遭遇服务不可用。
其次,社交网络的特点是用户之间的互动频繁,如好友关系建立、消息发送、照片和视频的分享等。这些互动往往涉及到复杂的关联数据处理,如好友推荐、新闻动态排序等。Facebook的架构设计需要支持复杂的社交图谱计算,以及高效的数据关联查询。
最后,随着用户基数的增长,数据量也呈爆炸式增长。Facebook需要一个能够支持大规模数据存储和快速访问的架构。这不仅包括用户数据的存储,还包括大量的非结构化数据,如图片、视频等多媒体内容。
总结: Facebook的架构设计必须具备高并发处理能力、支持复杂社交互动的数据处理能力以及大规模数据存储和访问能力。这些设计理念共同支撑起了一个能够应对数亿用户需求的社交网络平台。
2.1.2 架构设计的哲学和目标
Facebook的架构设计哲学是“快速、简单、透明”,这三个关键词指导了Facebook的技术栈选择、系统设计和运维实践。
在本章节中,我们将深入分析Facebook如何贯彻这一哲学,以及它对技术栈选择和系统设计的影响。
快速意味着Facebook追求快速迭代和敏捷开发。为了实现快速开发,Facebook采用了模块化和微服务的架构方式,允许团队独立开发和部署不同的服务。这样的设计不仅加快了开发速度,还提高了系统的灵活性和可维护性。
简单是指在技术选型和系统设计上追求简洁明了。Facebook避免过度设计,尽量减少不必要的复杂性。这种简洁的设计哲学使得Facebook的工程师能够快速理解系统的工作原理,降低了培训成本和沟通成本。
透明则是指在系统运维和监控方面追求高度的可观察性。Facebook构建了一套完善的监控和报警系统,确保工程师能够及时发现并解决系统问题。透明的运维哲学有助于维护系统的稳定性和可靠性。
小结: Facebook的架构设计哲学“快速、简单、透明”不仅体现在技术栈的选择上,也深刻影响了系统的设计和运维方式。这种设计理念有助于Facebook构建一个高效、稳定且易于维护的社交网络平台。
2.2 技术栈详解
2.2.1 前端技术栈
React与GraphQL
Facebook的前端技术栈以React为核心,React是一个由Facebook开发的用于构建用户界面的JavaScript库。React的虚拟DOM机制能够有效地处理组件状态和DOM的渲染,从而提高页面的响应速度和性能。
在本章节中,我们将探讨React的基本原理以及它如何与GraphQL结合使用。
React通过组件化的开发方式,让开发者可以构建可复用的UI组件,这些组件在状态变化时能够智能地更新DOM,而无需重新渲染整个页面。这种按需渲染的机制极大地提高了前端性能,尤其是在处理大量数据和复杂交互时。
GraphQL是Facebook开发的一种数据查询语言,它允许前端开发者以声明的方式定义数据需求,而不仅仅是一个返回全部数据的API。通过GraphQL,开发者可以精确地获取所需的最小数据集,减少网络传输和提高用户体验。
React和GraphQL的结合使用,使得前端开发者能够在不依赖后端API的情况下,进行快速的原型设计和迭代。同时,GraphQL的模式定义机制保证了前后端数据交互的一致性,减少了开发和调试的成本。
代码示例:
import React from 'react';
import { useQuery, gql } from '@apollo/client';
const GET_USER_PROFILE = gql`
query GetUserProfile($userId: ID!) {
user(userId: $userId) {
name
bio
profilePicture {
url
}
}
}
`;
function UserProfile({ userId }) {
const { loading, error, data } = useQuery(GET_USER_PROFILE, {
variables: { userId }
});
if (loading) return <p>Loading...</p>;
if (error) return <p>Error :(</p>;
return (
<div>
<h1>{data.user.name}</h1>
<p>{data.user.bio}</p>
<img src={data.user.profilePicture.url} alt="Profile" />
</div>
);
}
在上述代码中,我们定义了一个GraphQL查询 GET_USER_PROFILE ,并在React组件 UserProfile 中使用 useQuery 钩子来发起查询。这种方式使得前端开发者可以直接在组件中处理数据获取和状态管理,提高了开发效率。
参数说明:
-
gql:用于定义GraphQL查询字符串。 -
useQuery:Apollo Client提供的钩子,用于发起GraphQL查询并获取结果。
逻辑分析:
- 当组件加载时,
useQuery钩子发起GraphQL查询,并在查询期间返回一个loading状态。 - 一旦查询完成,
data对象包含了查询结果,组件可以根据这些数据渲染UI。 - 如果查询过程中发生错误,
error对象会被设置,组件可以根据错误信息渲染一个错误提示。
本章节介绍: React和GraphQL的结合使用提供了一种高效、灵活的前端开发方式,它们的组合成为Facebook前端技术栈的核心部分。
Node.js与Express
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,它使得JavaScript可以运行在服务器端。Express是一个灵活的Node.js Web应用框架,提供了一系列简单而强大的功能来创建Web应用。
在本章节中,我们将分析Node.js和Express在Facebook前端技术栈中的作用。
Facebook利用Node.js的非阻塞I/O和事件驱动特性,构建了高性能的后端服务。Node.js的单线程模型使得它在处理大量并发连接时表现出色,这对于Web应用尤为重要。Facebook的许多服务都是基于Node.js构建的,以满足其高并发需求。
Express框架则为Node.js应用提供了一种快速搭建Web应用和API的方法。它简化了路由、中间件、模板引擎等Web开发中的常见任务。Facebook使用Express来构建RESTful API,这些API为前端React应用提供数据。
代码示例:
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => {
res.send('Hello World!');
});
app.listen(port, () => {
console.log(`Example app listening at ***${port}`);
});
在上述代码中,我们创建了一个简单的Express应用,它监听3000端口,并在根路径 '/' 上响应一个简单的“Hello World!”消息。
参数说明:
-
express:Express框架的核心模块。 -
app:Express应用实例。 -
port:服务器监听的端口号。
逻辑分析:
-
app.get定义了一个GET路由处理器,当访问根路径'/'时,它会发送一个字符串'Hello World!'。 -
app.listen启动服务器并监听指定端口,当服务器启动后,控制台会输出一条消息。
本章节介绍: Node.js和Express的结合使用为Facebook提供了一个高效的后端服务开发环境,使得其前端技术栈更加完善。
2.2.2 后端技术栈
PHP与HipHop虚拟机
Facebook的后端技术栈最初是以PHP为基础,随着用户基数的增长,为了提高性能,Facebook开发了HipHop虚拟机(HHVM)。
在本章节中,我们将探讨PHP和HHVM在Facebook后端技术栈中的应用和优化策略。
PHP是一种广泛使用的开源服务器端脚本语言,它的简单性和易用性使得Facebook在早期选择了PHP作为主要的后端开发语言。然而,随着业务的快速发展,PHP的性能成为了瓶颈。
为了应对性能挑战,Facebook开发了HipHop虚拟机(HHVM),它是一个开源的JIT(即时编译)编译器,可以将PHP代码编译成机器码执行。HHVM相比传统的PHP解释器,能够提供更高的性能和更快的执行速度。
HHVM的引入显著提高了Facebook应用的响应速度和吞吐量。它还支持更多的PHP特性和扩展,使得开发者可以继续使用熟悉的PHP开发方式。
代码示例:
<?php
echo "Hello, World!";
?>
这是一个简单的PHP脚本,它输出“Hello, World!”字符串。
参数说明:
-
<?php:PHP代码的开始标记。 -
echo:PHP中的输出函数。
逻辑分析:
- 当PHP脚本被执行时,它输出一个简单的字符串。
本章节介绍: PHP和HHVM的结合使用为Facebook提供了强大的后端性能支持,使得其能够应对海量用户请求。
数据库选择与使用
Facebook的后端技术栈中,数据库的选择和使用也是非常关键的。Facebook使用了多种数据库技术来满足不同的需求。
在本章节中,我们将分析Facebook如何选择和使用不同的数据库技术。
Facebook的用户基数庞大,数据类型多样,因此它需要一个能够处理大规模数据存储和快速查询的数据库解决方案。Facebook在其后端技术栈中使用了MySQL、Cassandra和HBase等数据库技术。
MySQL是一种关系型数据库管理系统,它被用于处理结构化数据,如用户信息、关系数据等。Facebook对MySQL进行了大量的优化和定制,以提高其性能和可扩展性。
Cassandra是一种分布式NoSQL数据库,它被用于处理半结构化数据,如日志数据、用户行为数据等。Facebook的Cassandra集群规模巨大,支撑了其海量数据的存储和分析。
HBase是基于Hadoop的列式存储数据库,它被用于处理大规模的数据集。Facebook使用HBase来存储和分析大规模的非结构化数据。
本章节介绍: Facebook通过选择和使用多种数据库技术,满足了其处理大规模数据存储和快速查询的需求。
2.2.3 基础设施与服务
数据存储与缓存
Facebook的基础设施与服务中,数据存储和缓存是核心组成部分。
在本章节中,我们将探讨Facebook如何构建和优化其数据存储和缓存系统。
Facebook的数据存储系统需要支持海量的用户数据和访问请求。为此,Facebook构建了分布式数据存储系统,使用HDFS(Hadoop Distributed File System)和Cassandra等技术来存储和管理数据。
HDFS是一种高度容错的分布式文件系统,它可以存储和处理大规模的数据集。Facebook使用HDFS来存储用户上传的内容,如照片、视频等。
Cassandra作为一种分布式NoSQL数据库,能够处理大规模的数据写入和读取请求,适用于用户行为数据的存储和分析。
缓存是提高数据访问速度和系统性能的重要手段。Facebook使用Memcached和Redis等缓存技术来减少对数据库的直接访问压力,提高系统的响应速度。
Memcached是一种分布式内存对象缓存系统,它被用于缓存热点数据,如用户信息、新闻动态等。Facebook通过大规模部署Memcached集群,极大地提高了数据访问速度。
Redis是一种支持多种数据结构的缓存和消息传递系统,它被用于处理需要高读写性能的场景,如实时消息推送等。
本章节介绍: Facebook通过构建和优化数据存储和缓存系统,有效地支持了其大规模数据处理和快速访问的需求。
CDN与网络优化
内容分发网络(CDN)和网络优化对于Facebook这样的全球性社交网络平台至关重要。
在本章节中,我们将分析Facebook如何利用CDN和网络优化技术提高内容分发效率和用户体验。
CDN是一种分布式网络服务,它可以将数据缓存到世界各地的边缘节点上,使得用户可以从最近的节点下载内容,从而减少延迟和提高速度。
Facebook使用CDN来分发静态内容,如图片、视频、JavaScript和CSS文件等。通过CDN,Facebook能够有效地减少核心服务器的负载,并提高用户访问静态内容的速度。
除了CDN,Facebook还通过网络优化技术来提高用户体验。这包括使用QUIC协议来替代传统的TCP协议,减少连接建立时间,以及使用Brotli压缩算法来减小数据传输体积。
QUIC是一种基于UDP的传输层网络协议,它支持多路复用和连接迁移等特性,能够在网络条件变化时保持连接的稳定性。
Brotli是一种无损数据压缩算法,它在压缩率和压缩速度方面优于传统的gzip算法,能够有效地减少数据传输的大小,提高内容加载速度。
本章节介绍: Facebook通过CDN和网络优化技术,有效地提高了内容分发效率和用户体验,使得其在全球范围内保持了高速度和低延迟的服务。
2.3 实践案例分析
2.3.1 成功的架构设计案例
Facebook的架构设计案例中,有许多是成功的典范,它们展示了Facebook如何将其核心架构理念和技术栈应用于实际问题。
在本章节中,我们将通过一个具体的案例来分析Facebook如何实施其架构理念和技术栈。
假设我们要分析Facebook如何构建一个高性能的用户动态流服务。用户动态流是社交网络中的核心功能之一,它需要实时地向用户展示来自好友和关注对象的最新动态。
首先,Facebook会采用微服务架构来构建动态流服务,将服务拆分成独立的组件,如用户信息查询、动态内容获取、内容排序等。这样的设计有助于提高服务的可维护性和可扩展性。
其次,Facebook会使用PHP和HHVM来构建这些服务的后端逻辑,以保证高效的数据处理和快速的响应速度。对于数据存储,Facebook会使用MySQL来处理用户信息和好友关系数据,使用Cassandra来存储动态内容数据。
在前端,Facebook会使用React和GraphQL构建动态流的用户界面。React允许开发者构建可重用的UI组件,GraphQL则允许前端精确地获取所需的最小数据集,从而提高性能和用户体验。
最后,Facebook会使用CDN来分发静态资源,如图片和视频等,以减少服务器负载并提高内容加载速度。
本章节介绍: 通过这个案例,我们可以看到Facebook如何将其核心架构理念和技术栈应用于实际问题,成功地构建了一个高性能、可扩展的用户动态流服务。
2.3.2 架构演进与挑战
Facebook的架构不断演进,以应对不断变化的技术和业务挑战。
在本章节中,我们将探讨Facebook在其架构演进过程中遇到的挑战和解决方案。
随着用户基数的增长和用户行为的多样化,Facebook面临着数据量和访问量的爆炸式增长。为了应对这一挑战,Facebook不断地对其技术栈进行优化和升级。
例如,Facebook在数据库技术方面进行了大规模的优化,包括引入Cassandra和HBase等新的数据库技术,以及对MySQL进行深度定制和优化。这些改进提高了数据处理的效率和可扩展性。
在前端技术栈方面,Facebook也不断地引入新的技术,如React和GraphQL,以提高开发效率和用户体验。同时,Facebook也在持续优化其前端架构,减少网络延迟和提高页面加载速度。
在基础设施方面,Facebook构建了全球规模的CDN网络,并不断优化其网络架构,以减少延迟和提高内容分发效率。
本章节介绍: Facebook的架构演进是一个持续的过程,它需要不断地应对新的技术和业务挑战。通过不断的优化和创新,Facebook成功地保持了其技术领先地位,并提供了一个高性能、可扩展的社交网络平台。
3. Google核心架构理念与技术栈
Google作为全球领先的技术公司,其核心架构理念和技术栈对整个行业产生了深远的影响。本章将深入探讨Google的架构理念,以及它如何通过技术创新和架构设计来处理大规模数据和分布式系统。
3.1 Google架构理念概述
3.1.1 分布式系统的基石
Google的架构理念是建立在分布式系统之上的。分布式系统允许Google处理巨大的数据量和流量,同时保持系统的可扩展性和可靠性。通过分布式系统,Google能够在世界各地建立数据中心,将数据和服务分布到离用户更近的位置,从而提高访问速度和服务质量。
3.1.2 数据驱动与机器学习的集成
Google的架构设计中融入了数据驱动的理念,这意味着所有的决策都基于数据的分析和理解。此外,Google还将机器学习集成到其核心架构中,利用大数据进行训练模型,从而提高搜索质量、广告投放效果以及用户体验。
3.2 技术栈详解
3.2.1 前端技术栈
. . . Go语言与AngularJS
Google在前端技术栈中采用了Go语言和AngularJS的组合。Go语言以其高效、简洁的特性被用于后端服务和微服务架构中,而AngularJS则作为一个强大的前端框架,用于构建动态的网页应用。
3.2.2 后端技术栈
. . . MapReduce与Bigtable
MapReduce是一个分布式数据处理框架,它允许Google对大量数据进行处理和分析。Bigtable是Google设计的一个分布式数据库,用于存储结构化数据,支持高吞吐量的读写操作。
. . . Kubernetes与服务网格
Kubernetes是Google推出的一个开源容器编排平台,用于自动化容器化应用的部署、扩展和管理。服务网格(如Istio)提供服务发现、负载均衡、故障恢复和监控等功能,确保服务之间的通信高效可靠。
3.2.3 基础设施与服务
. . . Spanner与分布式数据库
Spanner是Google设计的一个全球分布式数据库,它提供一致性保证,并能够自动扩展和管理分布式数据。Spanner支持跨地理区域的数据复制和分布式事务,是Google内部使用的数据库技术。
. . . Borg与集群管理
Borg是一个集群管理系统,它负责管理和调度Google内部的大量计算任务。Borg的设计目标是提高资源利用率、优化任务调度,并简化集群的日常运维工作。
3.3 实践案例分析
3.3.1 架构创新的案例
Google在架构设计上的创新体现在其对现有技术的改进和新工具的开发。例如,Bigtable和Spanner都是Google为解决自身大规模数据处理需求而设计的,它们后来成为了业界的参考模型。
3.3.2 现实挑战与应对策略
面对大规模分布式系统的管理和维护挑战,Google采用了一系列应对策略。例如,通过自动化工具和智能监控系统来提高系统的稳定性和运维效率。同时,Google也在不断探索如何更好地利用机器学习来优化系统性能和用户体验。
本章节介绍了Google的核心架构理念,包括分布式系统的基石、数据驱动与机器学习的集成,以及Google的技术栈详解,包括前端技术栈(Go语言与AngularJS)、后端技术栈(MapReduce与Bigtable、Kubernetes与服务网格),以及基础设施与服务(Spanner与分布式数据库、Borg与集群管理)。此外,本章节还通过实践案例分析,展示了Google在架构创新和应对现实挑战方面的策略和成果。
4.1 Amazon架构理念概述
4.1.1 电商生态系统的架构需求
Amazon作为全球最大的电商平台,其架构设计理念首先围绕着满足电商生态系统的需求展开。电商生态系统不仅要处理海量的商品信息,还需要应对大量的用户交互、订单处理、支付交易、物流跟踪等复杂业务流程。这些需求对系统的可扩展性、高可用性、一致性和安全性提出了极高的要求。为了应对这些挑战,Amazon的架构设计强调了服务的模块化和微服务化,使得各个组件能够独立部署和扩展。
4.1.2 云服务的领导者的视角
Amazon在架构设计上不仅仅是电商平台的领导者,更是云服务领域的先驱和领导者。AWS(Amazon Web Services)的推出,标志着Amazon将自身的架构设计理念转化为可以提供给全球用户的服务。通过提供弹性计算、对象存储、内容分发网络等基础设施服务,Amazon展现了其对于云计算架构的深刻理解和实践。
4.2 技术栈详解
4.2.1 电商平台技术栈
AWS与EC2
Amazon的电商平台广泛使用其自家的云服务AWS(Amazon Web Services)来支撑其庞大的业务需求。其中,EC2(Elastic Compute Cloud)作为AWS中的弹性计算服务,为电商平台提供了可扩展的计算能力。EC2允许用户根据实际需求来启动或终止虚拟服务器实例,并按使用量付费,这极大地提高了资源的利用效率和成本控制能力。
S3与数据存储
S3(Simple Storage Service)是AWS提供的一个面向对象的数据存储服务,它具有高可靠性、安全性和无限的扩展性。电商平台使用S3存储静态内容如图片、视频等,同时也利用其提供的数据备份和归档功能来保证数据的持久性和安全性。通过S3,Amazon实现了对海量数据的高效管理,同时降低了存储成本。
4.2.2 云计算服务技术栈
Lambda与无服务器架构
Lambda是AWS提供的一个计算服务,它允许用户无需管理服务器或运行环境即可运行代码。Lambda与无服务器架构理念相结合,为开发者提供了编写和运行代码的平台,而无需担心底层的服务器管理。这种架构极大地简化了开发和运维流程,使得开发者可以更专注于业务逻辑的实现。
DynamoDB与NoSQL数据库
DynamoDB是AWS提供的一种完全管理的NoSQL数据库服务,它支持键值对和文档数据结构。DynamoDB提供快速的读写性能和高可用性,适用于需要快速响应和高吞吐量的应用场景。电商平台使用DynamoDB来存储用户数据、会话信息等,这些数据的访问模式通常不固定,DynamoDB的灵活性能够很好地满足这种需求。
4.3 实践案例分析
4.3.1 云服务架构的成功案例
Amazon通过自身的电商平台和AWS的成功实践,证明了其架构设计理念的有效性。AWS的用户遍布全球,包括初创公司、大型企业和政府机构,他们在使用AWS服务时都获得了显著的业务优势。这些成功案例展示了Amazon如何通过先进的架构设计和技术栈来构建稳定、可扩展的云服务平台。
4.3.2 系统扩展与性能优化实例
Amazon在系统扩展和性能优化方面有着丰富的经验和实践。例如,通过使用Auto Scaling自动扩展功能,AWS可以根据负载自动调整资源的使用量,保证服务的高可用性。同时,Amazon还利用CDN技术来优化内容分发的效率,减少延迟,提升用户体验。这些实践案例不仅展示了Amazon的技术实力,也为其他企业提供了宝贵的经验和参考。
在本章节中,我们深入探讨了Amazon的架构设计理念和技术栈,以及它们在电商平台和云计算服务中的应用。通过分析Amazon的技术实践,我们可以看到一个成功的架构设计是如何满足复杂业务需求、提升系统性能并优化用户体验的。Amazon的案例证明了,一个良好的架构设计不仅能够支撑业务的发展,还能够在竞争激烈的市场中保持领先地位。
5. 动态内容分发网络(CDN)的设计与实现
动态内容分发网络(CDN)是现代互联网架构中的重要组成部分,它通过在网络边缘缓存内容来提高内容交付的速度和效率。本章将深入探讨CDN的基本原理、技术实现以及实际应用。
5.1 CDN的基本原理
5.1.1 分布式缓存的概念
CDN的核心是分布式缓存技术。分布式缓存指的是将数据缓存到多个节点上,这些节点遍布全球不同地理位置,靠近最终用户。通过这种方式,内容可以更快地被用户获取,从而减少延迟和带宽消耗。当用户请求内容时,CDN会根据用户的位置将请求重定向到最近的缓存节点,而不是直接访问原始服务器。
5.1.2 内容分发的策略
内容分发策略决定了哪些内容需要被缓存以及如何维护这些缓存。常见的内容分发策略包括:
- 动态内容缓存 :对于经常变化的内容,CDN需要定期从原始服务器更新缓存,以保证内容的时效性。
- 静态内容缓存 :对于不经常变化的内容,CDN可以长时间缓存,甚至可以设置缓存过期时间,减少对原始服务器的请求次数。
- 智能分发 :CDN可以根据内容的流行度和用户的行为模式智能地调整内容的分发策略。
5.2 CDN的技术实现
5.2.1 边缘计算与节点分布
CDN的实现依赖于边缘计算技术,即在物理距离用户较近的网络边缘节点上进行数据处理和存储。这些节点通常部署在世界各地的数据中心。为了实现高效的缓存和分发,CDN需要精心设计节点分布策略,确保覆盖到主要的互联网用户群体。
5.2.2 路由算法与流量控制
CDN使用复杂的路由算法来决定如何高效地将用户请求导向最近的节点。这些算法需要考虑到网络拥塞、延迟、带宽等因素。同时,CDN还需要进行流量控制,以避免某一节点的负载过重,导致服务质量下降。
5.3 CDN的实际应用
5.3.1 实践中的CDN案例
许多大型互联网公司和服务提供商,如Netflix、Facebook和Google,都广泛使用CDN来分发其内容。这些公司通常会构建自己的CDN网络,或者与专业的CDN服务提供商合作,以确保其内容能够快速、可靠地交付给全球用户。
5.3.2 性能优化与用户体验
CDN的使用可以显著提升用户体验,因为它能够减少内容加载时间,提高网站的响应速度。此外,CDN还可以作为网站防御的一部分,帮助抵御DDoS攻击,因为它能够分散流量负载。
graph LR
A[用户请求] --> B[边缘节点]
B --> C{内容是否缓存}
C -->|是| D[快速响应]
C -->|否| E[向源服务器请求]
E --> D
上图展示了CDN处理用户请求的简化流程。用户请求首先到达边缘节点,如果内容已经缓存,则直接响应;如果未缓存,则从源服务器请求内容,然后将内容缓存到边缘节点,以便未来快速响应。
代码逻辑解读分析
在CDN的工作流程中,路由算法是关键部分。以下是一个简化的路由算法的代码示例,用于说明如何将用户请求导向最近的节点:
import math
def calculate_distance(user_location, node_location):
# 计算两个地理位置之间的欧氏距离
return math.sqrt((user_location[0] - node_location[0]) ** 2 + (user_location[1] - node_location[1]) ** 2)
def find_nearest_node(user_location, nodes):
# 寻找最近的节点
nearest_node = None
min_distance = float('inf')
for node in nodes:
distance = calculate_distance(user_location, node['location'])
if distance < min_distance:
min_distance = distance
nearest_node = node
return nearest_node
# 示例节点数据
nodes = [
{'location': (10, 10), 'id': 'node1'},
{'location': (20, 20), 'id': 'node2'},
{'location': (30, 30), 'id': 'node3'},
]
# 用户位置
user_location = (15, 15)
# 寻找最近的节点
nearest_node = find_nearest_node(user_location, nodes)
print(f"最近的节点是: {nearest_node['id']}")
在这个示例中,我们定义了一个简单的距离计算函数 calculate_distance ,用于计算用户位置和节点位置之间的欧氏距离。然后,我们定义了一个 find_nearest_node 函数,它遍历所有节点,找到距离用户最近的节点。最后,我们模拟了一个用户请求和一组示例节点,找出并打印最近的节点。
通过这个示例,我们可以看到CDN如何通过计算用户位置和节点位置之间的距离来决定将用户请求导向哪个节点。
参数说明
-
user_location: 用户的地理位置坐标,通常为经纬度。 -
node_location: 节点的地理位置坐标,同样为经纬度。 -
nodes: 一个包含所有节点位置和标识符的列表。
执行逻辑说明
- 定义计算距离的函数
calculate_distance。 - 定义寻找最近节点的函数
find_nearest_node。 - 设置用户位置和一组示例节点。
- 调用
find_nearest_node函数,找到最近的节点。 - 打印最近节点的标识符。
这个简单的示例展示了CDN路由算法的基本逻辑,实际的CDN系统会使用更复杂的算法和数据结构来处理全球范围内的用户请求和节点分布。
6. 大数据处理框架的应用
大数据处理框架是现代数据密集型应用的核心,它允许我们从海量数据中提取价值,进行复杂的分析和处理。本章将深入探讨大数据处理的基础概念、不同框架的内部工作机制以及实际应用案例。
6.1 大数据处理的基础概念
6.1.1 大数据的定义与特点
大数据通常指的是规模巨大到无法用传统数据库管理和分析工具处理的数据集。它具有体量巨大(Volume)、速度快(Velocity)、种类多(Variety)、价值密度低(Value)等特点。随着物联网、社交媒体和在线交易的兴起,大数据已经成为企业战略决策的重要组成部分。
6.1.2 处理框架的设计目标
大数据处理框架的设计目标是为了高效地存储、处理和分析这些大规模数据。它们需要能够处理非结构化和半结构化数据,支持海量数据的分布式存储和计算,并提供高速的数据访问和分析能力。
6.2 大数据处理框架详解
6.2.1 Hadoop生态系统
. . . HDFS与数据存储
Hadoop分布式文件系统(HDFS)是Hadoop生态的核心组件之一,它是一个高度容错的系统,适合在廉价的硬件上运行。HDFS将大文件分割成固定大小的数据块,并将这些块分布式存储在不同节点上。
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path("/user/hadoop/input/file.txt");
FSDataInputStream in = fs.open(path);
. . . MapReduce与数据处理
MapReduce是一种编程模型,用于处理大量数据。它将任务分解为两个阶段:Map和Reduce。Map阶段处理输入数据,生成中间数据;Reduce阶段则对这些中间数据进行汇总和处理。
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
6.2.2 Spark与实时数据处理
. . . RDD与数据流转
弹性分布式数据集(RDD)是Spark的核心概念,它是一个不可变的分布式对象集合。RDD可以通过并行操作实现高效的数据处理,并提供了容错机制。
. . . Stream与实时分析
Spark Streaming是Spark的扩展,它提供了实时数据流处理的能力。通过DStream(离散流),Spark Streaming可以将实时数据流分解为一系列小批次进行处理。
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
6.3 大数据的实际应用案例
6.3.1 大数据在业务中的应用
在实际业务中,大数据处理框架被广泛应用于用户行为分析、市场趋势预测、风险控制等领域。例如,通过分析用户交易数据,企业可以优化产品推荐系统,提高用户满意度。
6.3.2 框架选择与性能优化
选择合适的框架对于大数据项目至关重要。Hadoop适合批处理和存储需求大的场景,而Spark则更适合需要快速迭代和实时分析的应用。性能优化可以通过调整计算资源、优化数据分区和缓存策略等方式实现。
# 示例代码:Spark DataFrame操作
df = spark.read.json("/data/jsonFile")
df.select("field").where("condition").show()
通过以上内容,我们可以看到,大数据处理框架不仅仅是技术的堆砌,更是业务价值的实现工具。在实际应用中,我们需要根据具体需求选择合适的框架,并不断进行性能优化以满足业务发展的需要。
简介:网站架构设计是构建高效、可扩展且可靠在线服务的核心。本文集合了123篇关于Facebook、Google和Amazon的架构设计文章,涵盖了这些互联网巨头的核心架构理念、技术栈、演化历程以及面临的挑战和解决方案。Facebook以社交网络为核心,采用了动态内容分发网络(CDN)、大数据处理框架(Hadoop/Spark)、缓存系统(Memcached)、分布式NoSQL数据库(Cassandra)和HHVM虚拟机。Google以搜索和广告业务为主,使用MapReduce并行计算模型、Bigtable分布式列式数据库、GFS分布式文件系统、Chubby锁服务和Borg集群管理系统。Amazon作为电商和云计算的领军者,其架构设计特点包括弹性计算云(EC2)、简单存储服务(S3)、亚马逊简单队列服务(SQS)、CloudFront内容分发网络服务和DynamoDB NoSQL数据库服务。这些架构设计和实践对于构建可扩展、容错性强、响应迅速的大型网站以及利用云计算和分布式系统解决实际问题具有重要价值。

















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









