






全局唯一ID使用场景
分布式系统设计时,数据分片场景下,通常需要一个全局唯一id;
在消息系统中需要消息唯一ID标识来防止消息重复;
多系统打通需要一个全局唯一标识 (如集团各业务线面对不同用户,需要一个全局用户id)。
如何生成一个全局唯一id?或者说设计一个ID发号器呢?
常用如下几种方式:
1、UUID
Universally Unique Identifier 是自由软件基金会组织制定的唯一辨识ID生成标准,大多数系统已实现,如微软的GUID实现。
生成格式如:3d422567-f034-4ab4-b98f-a34fd263d0de
2、sequence表
使用DB统一维护一张(N张)发号表, 使用主键自增值生成唯一ID。
生成格式如:1,2,3,4,5....(递增数字)
3、SnowFlake 雪花算法
Twitter实现的算法,使用时间戳+机器分配标识+自增序列组成64位数字ID。
生成格式如:1292755860950487050
具体实现方式
1、UUID实现方案
1.1 使用linux程式
$ /usr/bin/uuidgendce6813b-c989-45ba-9704-0289c3e7c8d31.2 代码实现
package mainimport ( "fmt" "os/exec")func main() { out, err := exec.Command("uuidgen").Output() if err != nil { panic(err) //todo } fmt.Printf("%s", out)}1.3 google提供的实现方案
github.com/google/uuid
1.4 优点
性能高,本地生成,无依赖
1.5 缺点
生成格式太长,不适合做数据库主键id;
基于mac地址生成算法可能导致mac泄露
2、sequece表实现方案
2.1sequence表结构
id int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id'stub varchar(10) NOT NULL DEFAULT '' COMMENT '存根'2.2sql实现
插入并获取最新序号,这里也可以直接使用replace方式。
BEGIN;insert into sequence (stub) value ('x');select LAST_INSERT_ID();COMMIT;2.3服务部署
冗余服务部署,可部署多个库表,设置不同step,让每个sequence产生不同号码。
如部署2个服务节点,并行获取数据,两个表均设置step=2,一个start from 1 (获取1,3,5,7,9...),一个start from 2 (获取2,4,6,8,10...)
2.4优点
ID呈单调自增趋势,满足一些场景如搜索排序
方案成熟,使用及部署简单
2.5缺点
依赖DB,有单节点DB性能瓶颈
如果DB采用主从架构,主从切换时可能会重复发号
生成号码存在递增规律,如可推断出一天的新增订单量,两天在同一时间点分别下单,然后根据订单号相减
2.6优化方案
提前从数据库读取一段放到代理服务器内存中,可减少数据库IO操作,提高性能
3、SnowFlake 雪花算法实现方案
3.1 实现原理:
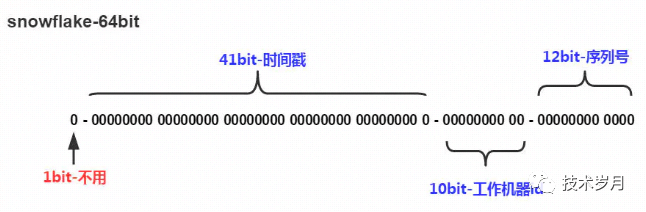
(图片来自网络)
1位最高位:符号位不使用(0表正数,1表负数)
41位时间戳:2^41-1个数字代表69年,所以设置发号起始时间最好为发号器首次运行时间
10位工作机器id:也会分为5位datacenterId和5位workerId
12位序列号:2^12-1个数字总共4095,同一毫秒同一机器节点可以并发产生4095个不同Id
3.2代码实现
package mainimport ( "fmt" "errors" "runtime" "sync" "time")//global varvar sequence int = 0var lastTime int = -1//every segment bitvar workerIdBits = 5var datacenterIdBits = 5var sequenceBits = 12//every segment max numbervar maxWorkerId int = -1 ^ (-1 << workerIdBits)var maxDatacenterId int = -1 ^ (-1 << datacenterIdBits)var maxSequence int = -1 ^ (-1 <//bit operation shiftvar workerIdShift = sequenceBitsvar datacenterShift = workerIdBits + sequenceBitsvar timestampShift = datacenterIdBits + workerIdBits + sequenceBitstype Snowflake struct { datacenterId int workerId int epoch int mt *sync.Mutex}func NewSnowflake(datacenterId int, workerId int, epoch int) (*Snowflake, error) { if datacenterId > maxDatacenterId || datacenterId < 0 { return nil, errors.New(fmt.Sprintf("datacenterId cant be greater than %d or less than 0", maxDatacenterId)) } if workerId > maxWorkerId || workerId < 0 { return nil, errors.New(fmt.Sprintf("workerId cant be greater than %d or less than 0", maxWorkerId)) } if epoch > getCurrentTime() { return nil, errors.New(fmt.Sprintf("epoch time cant be after now")) } sf := Snowflake{datacenterId, workerId, epoch, new(sync.Mutex)} return &sf, nil}func (sf *Snowflake) getUniqueId() int { sf.mt.Lock() defer sf.mt.Unlock() //get current time currentTime := getCurrentTime() //compute sequence if currentTime < lastTime { //occur clock back //panic or wait,wait is not the best way.can be optimized. currentTime = waitUntilNextTime(lastTime) sequence = 0 } else if currentTime == lastTime { //at the same time(micro-second) sequence = (sequence + 1) & maxSequence if sequence == 0 { //overflow max num,wait next time currentTime = waitUntilNextTime(lastTime) } } else if currentTime > lastTime { //next time sequence = 0 lastTime = currentTime } //generate id return (currentTime-sf.epoch)< sf.workerId<}func waitUntilNextTime(lasttime int) int { currentTime := getCurrentTime() for currentTime <= lasttime { time.Sleep(1 * time.Second / 1000) //sleep micro second currentTime = getCurrentTime() } return currentTime}func getCurrentTime() int { return int(time.Now().UnixNano() / 1e6) //micro second}func main() { runtime.GOMAXPROCS(runtime.NumCPU()) datacenterId := 0 workerId := 0 epoch := 1596850974657 s, err := NewSnowflake(datacenterId, workerId, epoch) if err != nil { panic(err) } var wg sync.WaitGroup for i := 0; i < 1000000; i++ { wg.Add(1) go func() { fmt.Println(s.getUniqueId()) wg.Done() }() } wg.Wait()}3.3 运行效果
$go run snowflake.go >y
$cat y|wc -l
1000000
$sort -nr y|uniq -c|head -2
1 1649336840618140
1 1649336840618139
并发获取100w个号码,没有重复。
3.4 服务部署
不同机器使用不同DatacenterId(数据中心集群id),WorkerId (机器节点id),最多可部署1024个节点。
3.5优点
使用时间在高位,ID呈现递增趋势,满足一些场景如搜索排序。
不依赖其他组件,易于部署维护。
3.6缺点
依赖机器时钟,因时钟回拨问题会导致发号重复或不可用,代码实现时采用循环等待下一时钟的方式,可能会有性能问题。
3.7优化方案
多节点部署时,可使用zookeeper做节点分布式协调 一致性管理,当出现时钟回拨可由zk来同步时间或摘除节点。
4.总结
UUID | sequence | snowflake | |
描述 | 集成在标准系统中可简单生成 | 使用DB自增id实现 | 根据时间+机器分配标识+自增序列生成 |
依赖 | 无 | DB | 无 |
优点 | 本地生成性能高 | 部署简单 生成ID单调递增 | 部署简单 生成ID单调递增 |
缺点 | 生成号码复杂,很多场景不利于使用 | 依赖DB有性能问题和重复发号问题 号码存在规律会泄露信息 | 依赖系统时钟,时钟回拨会造成重复发号问题 |
说明:
针对sequence表方式、snowflake方式的缺点,美团leaf给出了更详细的优化方案可以参考,这里就不过多引用,直接查看参考文档。
参考文档
meituan leaf:
https://tech.meituan.com/2017/04/21/mt-leaf.html
twitter snowflake:
https://github.com/twitter-archive/snowflake/blob/snowflake-2010/src/main/scala/com/twitter/service/snowflake/IdWorker.scala














 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









