






为了统一形式,对条件(1)与条件(2)两边同时取对数,整理后得到新的概率差分隐私约束条件:
(3)$\forall {T_i} \in D,\sum\limits_{\forall ite{m_j} \in {T_i}} {\ln \left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} \ge \theta ,\theta = \max \left[ {\ln \left( {\frac{1}{{{e^\varepsilon }}}} \right),\ln (1 - \delta )} \right]$
图 1(Fig.1)
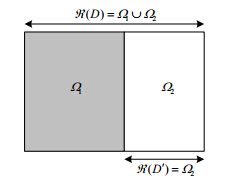
Fig.1
Sample space图 1
抽样结果空间
3.3 分布式非线性规划模型
分布式结构下,为了分析数据及进行数据挖掘任务,各站点协作共享数据.从数据应用出发,不同应用对数据质量的要求不同,有些应用只需要数据的部分信息.例如,关联规则挖掘仅需要频繁项集.发布数据时,一方面要保护个体隐私,另一方面要为数据分析保留足够的数据信息.可见,优化输出数据的效用性非常必要.本文定义数据效用性优化目标为:最大化支持计数.尽可能最大化结果中项的支持计数,对于Top-K查询等应用具有重要的意义.
定义优化目标函数为$[\sum\nolimits_{\forall ite{m_j}} {ite{m_j}.x} $,令概率差分隐私约束条件为优化问题的约束条件,定义如公式(4)的优
化问题,该优化问题的解为最优输出效用性.最后,对结果x的取值为ëxû.
$\left\{ \begin{array}{l}
\max :\sum\nolimits_{\forall ite{m_j}} {ite{m_j}.x} \\
{\rm{s}}{\rm{.t}}{\rm{. }}\forall {T_i} \in D,\sum\nolimits_{\forall ite{m_j} \in {T_i}} {\ln \left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} \ge \max \left[ {\ln \left( {\frac{1}{{{e^\varepsilon }}}} \right),\ln (1 - \delta )} \right]
\end{array} \right.$
(4)
优化问题(4)的标准形式为
$\left\{ \begin{array}{l}
\min :f(X) = - sum(X)\\
{\rm{s}}{\rm{.t}}{\rm{. }}{g_i}(X) = - \sum\limits_{j = 1}^m {\left( {\ln \left( {1 - \frac{{X[j]}}{{C[j]}}} \right) \times D[i,j]} \right) + \theta \le 0,i = 1,...,n} \\
X[i] \ge 0,i = 1,...,n
\end{array} \right.$
(5)
其中,n为事务数;m为项集数,站点A拥有前m1个项,站点B拥有后m-m1个项;q为全局共享参数;X是一个(1xm)的向量,为各项未知的最优支持计数,全局共享;C是一个(1xm)的向量,为各项的已知支持计数,站点A拥有前m1个值,站点B拥有后m-m1个值;δ为垂直划分的分布式事务数据集,δ[i,j]={0,1}.非线性规划问题(5)的条件约束与项集数|U|以及事务数|T|相关.
3.4 分布式非线性规划安全求解
随机抽样机制Â的第1步是求解非线性规划问题(5),得到项的最优支持计数.本文提出两种解决方案:第1种为全局解决方案(global solution,简称GS),基于全局数据,在分布式结构下,首先通过K-T条件等价转换得到非线性方程组,然后应用Marquardt法[,基于安全数量积和协议求解方程组,得到全局各项最优支持计数;第2种为局部解决方案(local solution,简称LS),基于局部数据,各站点采用SQP方法[独立求解非线性规划问题(5),得到各自所拥有项的最优支持计数.概率差分隐私组合定理表明,LS同样满足概率差分隐私约束.
3.4.1 全局解决方案
求解非线性规划问题最有效的方法是采用SQP[方法,由于SQP算法的复杂性,难以在分布式结构下实现,根据定理1,通过K-T等价条件将非线性规划问题转化为非线性方程组.
定理1. 非线性规划问题(5)为凸规划问题.
证明:非线性规划问题满足如下两个条件:
(1) 所有的线性函数均为凸函数,因此,f(X)为凸函数;
(2) gi(X)(i=1,…,n)的Hessian矩阵为
$H = {\nabla ^2}{g_i}(X) = \left[ {\begin{array}{*{20}{c}}
{\frac{{D[i,1]}}{{{{(X[1] - C[1])}^2}}}} \cdots 0\\
\vdots \ddots \vdots \\
0 \cdots {\frac{{D[i,m]}}{{{{(X[m] - C[m])}^2}}}}
\end{array}} \right]$
(6)
其中,δ[i,j]={0,1},j=1,…,m.对于所有不为0的XÎRn,都有XHXT≥0,所以H为半正定矩阵,因此,gi(X)(i=1,…,n)为凸函数.
根据凸规划问题的定义[,非线性规划问题(5)满足同时条件(1)与条件(2),证明非线性规划问题(5)为凸规划问题. □
对于凸规划问题,根据最优解的一阶充分条件[,如果满足K-T必要条件的点$\bar X$存在,则$\bar X$为非线性规划
问题(5)的全局最优解.公式(5)的K-T条件可以等价写为
$\left\{ \begin{array}{l}
\nabla f(\bar X) - \sum\limits_{i = 1}^n {{w_i}\nabla {g_i}(\bar X)} = 0\\
{w_i}{g_i}(\bar X) = 0,i = 1,...,n\\
{w_i} \ge 0,i = 1,...,n
\end{array} \right.$
(7)
方程组(7)含有m+n个未知数(m个x,n个Ω)、m+n个等式方程,为非线性方程组,它的解为优化问题(5)的全局最优解.计算f(X)与gi(X)(i=1,…,n)的梯度,方程组(7)化解为如下m+n个等式方程:
· 前m个等式方程为
${h_j} = 1 + \sum\limits_{i = 1}^n {\left( {\frac{{{w_i} \cdot D[i,j]}}{{X[j] - C[j]}}} \right)} = 0,j = 1,...,m$
(8)
· 后n个等式方程为
${l_i} = {w_i} \cdot \left( {\sum\limits_{j = 1}^m {\left( {\ln \left( {1 - \frac{{X[j]}}{{C[j]}}} \right) \times D[i,j]} \right) - \theta } } \right) = 0,i = 1,...,n$
(9)
令f=[h1…hm l1…ln],该方程组可以应用非线性最小二乘法的改进方法Marquardt法[求解.在Marquardt法的第k次迭代中,令:
${d^{(k)}} = - {(A_k^T{A_k} + {\alpha _k}I)^{ - 1}}A_k^T{f^{(k)}}$
(10)
其中,I为单位矩阵,ak为一个正实数.显然,当ak=0时,δ(k)就是高斯-牛顿方向.后继点为
x(k+1)=x(k)+δ(k)
(11)
公式(10)包含f(k)与Ak,其计算公式分别为
f(k)=(f1(x(k)),…,fm(x(k)),fm+1(x(k)),….,fm+n(x(k)))T
(12)
${A_k} = \left[ {\begin{array}{*{20}{c}}
{\frac{{\partial {f_1}({x^{(k)}})}}{{\partial {x_1}}}} \cdots {\frac{{\partial {f_1}({x^{(k)}})}}{{\partial {x_m}}}}{\frac{{\partial {f_1}({x^{(k)}})}}{{\partial {x_{m + 1}}}}} \cdots {\frac{{\partial {f_1}({x^{(k)}})}}{{\partial {x_{m + n}}}}}\\
\vdots {} \vdots \vdots {} \vdots \\
{\frac{{\partial {f_{m + n}}({x^{(k)}})}}{{\partial {x_1}}}} \cdots {\frac{{\partial {f_{m + n}}({x^{(k)}})}}{{\partial {x_m}}}}{\frac{{\partial {f_{m + n}}({x^{(k)}})}}{{\partial {x_{m + 1}}}}} \cdots {\frac{{\partial {f_{m + n}}({x^{(k)}})}}{{\partial {x_{m + n}}}}}
\end{array}} \right]$
(13)
f(k)是[m+n,1]的列向量,Ak是[m+n,m+n]的矩阵.分布式计算环境下,站点A与站点B共享目标函数f(X)、参数(e,δ)以及每次迭代中的${X^k} = (x_1^k,...,x_m^k),{W^k} = (w_1^k,...,w_n^k)$.由于数据集D的分布式垂直划分,导致向量f(k)与矩阵Ak也被划分为两部分,分布在站点A与站点B中.为安全求解公式(10),需要分析f(k)与Ak的分布.首先,分析前m个方程组公式(8)的计算需要站点A与站点B协作进行,常数项1不涉及隐私信息,可由任意站点计算.将公式(8)分解为如下两部分:
${h_{[1,{m_1}]}}({P_A}) = 1 + \sum\limits_{i = 1}^n {\left( {\frac{{{w_i} \cdot D[i,j]}}{{X[j] - C[j]}}} \right)} ,j = 1,...,{m_1}$
(14-A)
${h_{[{m_1} + 1,m]}}({P_B}) = \sum\limits_{i = 1}^n {\left( {\frac{{{w_i} \cdot D[i,j]}}{{X[j] - C[j]}}} \right)} ,j = {m_1} + 1,...,m$
(14-B)
令$H({P_A}) = {[{h_1}({P_A})...{h_{{m_1}}}({P_A})]^T},H({P_B}) = {[{h_{{m_1} + 1}}({P_B})...{h_m}({P_B})]^T}$,公式(8)可统一表示为
H=[H(PA) H(PB)]T=0
(15)
同理,后n个方程组公式(9)可分解为两部分,常数q全局共享,可由任意一方计算:
${l_{[1,n]}}({P_A}) = {w_i} \cdot \sum\limits_{j = 1}^{{m_1}} {\left( {\ln \left( {1 - \frac{{X[j]}}{{C[j]}}} \right) \times D[i,j]} \right)} ,i = 1,...,n$
(16-A)
${l_{[1,n]}}({P_B}) = {w_i} \cdot \sum\limits_{j = {m_1} + 1}^m {\left( {\ln \left( {1 - \frac{{X[j]}}{{C[j]}}} \right) \times D[i,j]} \right)} ,i = 1,...,n$
(16-B)
令L(PA)=[l1(PA)…ln(PA)]T,L(PB)=[l1(PB)…ln(PB)]T,Q=[Ω1q…wnq]T,公式(9)可统一表示为
G=L(PA)+L(PB)-Q=0
(17)
结合公式(15)与公式(17),得到f(k)为
${f^{\left( k \right)}} = [{[H{({P_A})^{({x_k})}}]_{[{m_1},1]}}{\rm{ }}{[H{({P_B})^{({x_k})}}]_{[m - {m_1},1]}}{\rm{ }}{[L{({P_A})^{({x_k})}} + L{({P_B})^{({x_k})}} - \Theta ]_{[n,1]}}]_{[1,m + n]}^T$
(18)
公式(18)表明,f(k)由3大部分构成,分布在站点A与站点B中.令:
$f_A^{(k)} = [{[H{({P_A})^{({x_k})}}]_{[{m_1},1]}}{\rm{ }}{[O]_{[m - {m_1},1]}}{\rm{ }}{[L{({P_A})^{({x_k})}}]_{[n,1]}}]_{[1,m + n]}^T,f_B^{(k)} = [{[O]_{[{m_1},1]}}{\rm{ }}{[H{({P_B})^{({x_k})}}]_{[m - {m_1},1]}}{\rm{ }}{[L{({P_B})^{({x_k})}} \\- \Theta ]_{[n,1]}}]_{[1,m + n]}^T$
f(k)最终可表示为两方的和:
${f^{(k)}} = f_A^{(k)} + f_B^{(k)}$
(19)
对公式(15)与公式(17)求导,得到Ak为
${A_k} = {\left[ {\begin{array}{*{20}{c}}
{\left[ {\frac{{\partial H({P_A})}}{{\partial {x_{[{m_1},m]}}}}{\rm{ }}\frac{{\partial H({P_A})}}{{\partial {w_{[{m_1},n]}}}}} \right]}\\
{\left[ {\frac{{\partial H({P_B})}}{{\partial {x_{[m - {m_1},m]}}}}{\rm{ }}\frac{{\partial H({P_B})}}{{\partial {w_{[m - {m_1},n]}}}}} \right]}\\
{\left[ {\frac{{\partial L({P_A})}}{{\partial {x_{[n,{m_1}]}}}}} \right]{\rm{ }}\left[ {\frac{{\partial L({P_B})}}{{\partial {x_{[n,m - {m_1}]}}}}} \right]{\rm{ }}\left[ {\frac{{\partial L({P_A})}}{{\partial {w_{[n,n]}}}} + \frac{{\partial L({P_B})}}{{\partial {w_{[n,n]}}}} - \theta } \right]}
\end{array}} \right]_{[m + n,m + n]}}$
(20)
公式(20)表明,Ak由5大部分构成,分布在站点A与站点B中.令:
$A_k^A = {\left[ {\begin{array}{*{20}{c}}
{\left[ {\frac{{\partial H({P_A})}}{{\partial {x_{[{m_1},m]}}}}{\rm{ }}\frac{{\partial H({P_A})}}{{\partial {w_{[{m_1},n]}}}}} \right]}\\
{[{0_{[m - {m_1},m]}}{\rm{ }}{0_{[m - {m_1},n]}}]}\\
{\left[ {\frac{{\partial L({P_A})}}{{\partial {x_{[n,{m_1}]}}}}} \right]{\rm{ }}[{0_{[n,m - {m_1}]}}]{\rm{ }}\left[ {\frac{{\partial L({P_A})}}{{\partial {w_{[n,n]}}}}} \right]}
\end{array}} \right]_{[m + n,m + n]}},A_k^B = {\left[ {\begin{array}{*{20}{c}}
{[{0_{[{m_1},m]}}{\rm{ }}{0_{[{m_1},n]}}]}\\
{\left[ {\frac{{\partial H({P_B})}}{{\partial {x_{[m - {m_1},m]}}}}{\rm{ }}\frac{{\partial H({P_B})}}{{\partial {w_{[m - {m_1},n]}}}}} \right]}\\
{[{0_{[n,{m_1}]}}]{\rm{ }}\left[ {\frac{{\partial L({P_B})}}{{\partial {x_{[n,m - {m_1}]}}}}} \right]{\rm{ }}\left[ {\frac{{\partial L({P_B})}}{{\partial {w_{[n,n]}}}} - \theta } \right]}
\end{array}} \right]_{[m + n,m + n]}}$,
Ak最终可表示为两方的和:
${A_k} = A_k^A + A_k^B$
(21)
上述分析表明,f(k)与Ak在站点A与站点B的分布情况如图 2所示.
图 2(Fig.2)
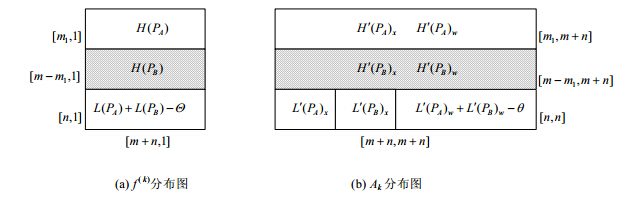
Fig.2
Distribution of f(k) and Ak图 2
f(k)与Ak的分布情况
考虑Marquardt算法中${d^{(k)}} = - {(A_k^T{A_k} + {\alpha _k}I)^{ - 1}}A_k^T{f^{(k)}}$,分布式结构下,为保护各站点不泄露隐私信息,需要进行加密操作的计算有$A_k^T{f^{(k)}}$与$A_k^T{A_k}$.根据公式(19)、公式(21)可得到:
$\begin{array}{l}
A_k^T{f^k} = (A_k^{AT} + A_k^{BT}) \cdot (f_k^A + f_k^B)\\
{\rm{ }} = (A_k^{AT} \cdot f_A^{(k)} + A_k^{BT} \cdot A_B^{(k)}) + (A_k^{AT} \cdot A_B^{(k)} + A_k^{BT} \cdot f_A^{(k)})
\end{array}$
(22)
同理,
$\begin{array}{l}
A_k^T{A_k} = (A_k^{AT} + A_k^{BT}) \cdot (A_k^A + A_k^B)\\
{\rm{ }} = (A_k^{AT} \cdot A_k^A + A_k^{BT} \cdot A_k^B) + (A_k^{AT} \cdot A_k^B + A_k^{BT} \cdot A_k^A)
\end{array}$
(23)
3.4.1.1 数量积和协议
输入:假设站点A拥有向量a[1,n],b[1,m],站点B拥有向量c[1,n],d[1,m];
输出:R=a×c+b×d.
(1) 根据已有数量积协议,站点A与站点B安全计算数量积a×c,站点A得到a×c+v1,站点B得到随机数v1;
(2) 同理,站点A与站点B计算数量积b×d,站点A得到b×d+v2,站点B得到随机数v2;
(3) 站点A计算第(1)步与第(2)步结果的和:r1=a×c+b×d+v1+v2,站点B计算第(1)步与第(2)步结果的和:
r2=v1+v2.
(4) 站点B将计算结果r2发给站点A,站点A计算R=r1-r2.
(5) 站点A将计算结果R发给站点B.
公式(22)与公式(23)的前半部分可在本地进行而无需进行任何加密操作;后半部分的计算涉及到站点A与站点B的信息,为防止计算过程中站点A与站点B的信息泄露,必须加密处理.公式(22)与公式(23)的后半部分均为矩阵与向量或矩阵与矩阵的乘积,涉及到的操作仅有数量积和,为安全执行数量积和操作,本文提出一种安全两方数量积和协议.
3.4.1.2 数量积和协议的安全性分析
数量积和协议安全地计算两个数量积的和a×c+b×d,计算过程中,各站点无法得到a×c与b×d的值.数量积和协议基于已有的高效安全的数量积协议A与站点B分别执行数量积操作,各站点并不共享得到的结果,a×c与b×d的值是安全的;第(3)步,站点A与站点B分别对第(1)步与第(2)步的结果求和;第(4)步,站点B将随机数的和发给站点A,站点A计算数量积和为:R=r1-r2,该步骤中,由于站点A从站点B得到的是两个随机数的和,并不知道v1与v2的值,因此,站点A无法知道a×c与b×d的值,从而推断不出站点B的信息;第(5)步中,站点B得到数量积和a×c+b×d,同样无法知道a×c与b×d的值,从而推断不出站点A的信息.总之,本文提出的数量积和协议是安全的.
3.4.1.3 全局解决方案(GS)
全局共享:目标函数f(X)、参数(e,δ)、每次迭代中的Xk,Wk.
输入:站点A:DA;站点B:DB;
输出:各项最优支持计数X.
(1) 非线性规划问题(5)的K-T条件等价写为方程组(7)
(2) 设A为主站点,使用Marquardt法求方程组(7)
(3) Marquardt法每次迭代:
(4) 站点A计算$f_A^{(k)}$与$A_k^A$,站点B计算$f_B^{(k)}$与$A_k^B$.f(k)与Ak均由两部分组成:
${f^{(k)}} = f_A^{(k)} + f_B^{(k)},{A_k} = A_k^A + A_k^B$.
(5) 站点A使用数量积和协议计算$A_k^T{f^{(k)}}$与$A_k^T{A_k}$.
(6) 站点A计算:${d^{(k)}} = - {(A_k^T{A_k} + {\alpha _k}I)^{ - 1}}A_k^T{f^{(k)}}$
(7) 站点A计算: x(k+1)=x(k)+δ(k)
(8) 直到Marquardt收敛
基于数量积和协议,本文提出全局解决方案安全地求解非线性规划问题(5):第(1)步与第(2)步首先将非线性规划问题(5)的K-T条件等价写为方程组(7);其次,从第(3)步开始,采用Marquardt法求解方程组,分布式结构下,每次迭代过程为安全计算x(k+1),第(5)步中使用数量积和协议进行加密计算.全局解决方案基于全局数据求解分布式非线性规划问题,为保证各站点在计算过程中不泄露各自的机密信息,如,项的真实支持计数等,采用两
方数量积和协议有效地保证了通信与计算安全.
3.4.2 局部解决方案
全局解决方案同时考虑所有站点拥有项的条件,而局部解决方案中,各站点基于本地所拥有项,首先独立求解优化问题,得到本地所拥有项的最优计数;然后,各站点抽样得到本地事务数据集;最后,通过事务ID连接得到集成数据集.定理2表明,局部解决方案满足差分隐私要求.
定理2. 事务数据集X被垂直划分为两个部分:X1,X2,分别拥有项集U1,U2,全局项集U=U1ÈU2.存在两个随机抽样算法M1(X1)与M2(X2),分别满足(e1,δ1)与(e2,δ2)-概率差分隐私,则M1(X1)与M2(X2)的组合M(X)满足(e1+e2,δ1+δ2-δ1×δ2)-概率差分隐私.
证明:
(1) 第1种情况,"OÎΩ1:
因为M1满足(e1,δ1)-概率差分隐私约束,则必然满足Pr[M1(X1)ÎΩ1]≤δ1,所以:
$\prod\limits_{\forall ite{m_j} \in {U_1}} {\left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} \ge 1 - {\delta _1}$
(24)
同理,M2满足(e2,δ2)-概率差分隐私约束,则必然满足Pr[M2(X2)ÎΩ2]≤δ2,得到:
$\prod\limits_{\forall ite{m_j} \in {U_2}} {\left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} \ge 1 - {\delta _2}$
(25)
公式(24)与公式(25)左右两端相乘:
$\begin{array}{l}
\prod\limits_{\forall ite{m_j} \in {U_1}} {\left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} \cdot \prod\limits_{\forall ite{m_j} \in {U_2}} {\left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} = \prod\limits_{\forall ite{m_j} \in {U_1} \cup {U_2}} {\left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} \\
{\rm{ }} \ge (1 - {\delta _1}) \cdot (1 - {\delta _2})\\
{\rm{ }} = 1 - ({\delta _1} + {\delta _2}) + {\delta _1} \cdot {\delta _2}
\end{array}$
(26)
最终得到:
$\Pr [M(X) \in {\Omega _1}] = 1 - \prod\limits_{\forall ite{m_j} \in {I_1} \cup {I_2}} {\left( {1 - \frac{{ite{m_j}.x}}{{ite{m_j}.count}}} \right)} \le ({\delta _1} + {\delta _2}) - {\delta _1} \cdot {\delta _2}$
(27)
(2) 第2种情况,"OÎΩ2:
$\begin{array}{l}
\Pr [M(X) = O] = \Pr [{M_1}({X_1}) = O] \times \Pr [{M_2}({X_2}) = O]\\
{\rm{ }} \le \Pr [{M_1}({{X'}_1}) = O] \times \Pr [{M_2}({{X'}_2}) = O] \times {e^{{\varepsilon _1} + {\varepsilon _2}}}\\
{\rm{ }} = \Pr [M(X') = O] \times {e^{{\varepsilon _1} + {\varepsilon _2}}}
\end{array}$
(28)
3.4.3 GS与LS对比
LS中,各点独立完成整个发布策略.然而需要注意的是,本地非线性规划问题(5)的求解过程并不满足差分隐私要求.因为任意事务的改变都会影响最终的结果,导致隐私的泄露.文献[存在同样的问题,并提出合理的解决方案.本文可采用相同的方法,对结果添加服从拉普拉斯分布的噪音,具体方法见文献[.本文主要讨论抽样过程及分布式结构下非线性规划求解,不详细讨论噪音的添加量.
但GS中,各站点协作完成发布过程,非线性规划问题(5)的求解不会存在该问题.从全局来看,任意事务中,任意项的改变都会影响结果.分布式结构下,各站点拥有项的支持计数为隐私信息,求解过程中不会泄露给对方,即使知道项的改变发生在哪个事务,也推断不出发生改变的项.因此,基于GS的整个发布过程满足差分隐私要求.
4 实验结果与分析
本节我们在实验环境中评价本文提出的差分隐私发布策略.首先考查了在不同参数设置的情况下,(e,δ)的不同值对GS与LS结果数据量的影响;其次,对比GS与LS对Top-K项的保留百分比;然后,分析事务数与项集数对LS执行时间的影响;最后,从理论上分析GS的计算复杂度与通信代价.
4.1 实验设置
· 数据集
本文使用公共基准事务数据集:T40I10D100K,该数据集是人造数据集.由于低支持计数的项在频繁项集挖掘或分类等数据挖掘任务中意义不大,通常会在剪枝步骤中被删除,因此在预处理阶段,移除所有支持计数小于等于0.1%|T|的项,|T|为事务数.然后,从预处理后的数据集中随机抽取20 000个事务、50个项作为最终的实验数据集,事务数为|T|=20000,项集数|U|=50,数据量为|D|=195913.将事务数据集表示为关系表,站点A拥有前25个项,站点B拥有后25个项.表 2描述实验数据集的基本信息.
表 2(Table 2)
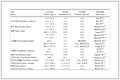
Table 2 Experiment data set表 2 实验数据集
Dataset
#Transactions |D|
Average length
# Items |U|
# Items occurrences
Data size (KB)
T40I10D100K
Original
100 000
39.595 4
924
3 959 538
4 902
Selected
20 000
9.80
50
195 913
133
Table 2 Experiment data set表 2 实验数据集
· 运行环境与参数设置
运行环境为2.50GHz Core™ i5-2450M CPU,6.00GB内存,64位Win7操作系统.
实验环境为MATLAB 7.11.0(R2010b).为观察不同参数值对结果的影响,实验过程中参数设置为
δ={0.1,0.2,0.5,0.6,0.8},eε={1.01,1.1,1.4,1.7,2.0}.
4.2 项支持计数
项支持计数优化问题保证结果数据集的数据量|D¢|尽可能大,以保留更多数据信息.根据不同的参数设置,对T40I10D100K数据集进行实验.令ratio=|D¢|/|δ|x100%,表示结果数据量占原数据量的百分比.图 3给出站点A与站点B采用GS与LS求解非线性规划问题的结果.
图 3(Fig.3)
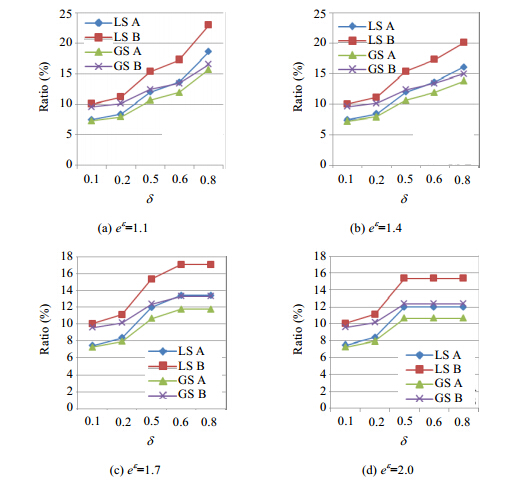
Fig.3
Size of the result data of LS and GS vs. eε, δ图 3
LS与GS对不同参数的结果数据量
图 3表明,结果数据量比较小.主要是因为约束条件与未知变量太多,共有|δ|=195913个约束条件,|U|=50个变量;又由于事务数据的稀疏性,导致结果数据量较小.这是合理的,与理论分析相符,为差分隐私约束下的最优解.具体来说,对于站点A,LS的结果范围是7.45%~18.58%,GS的结果范围是7.24%~15.72%;对于站点B,LS的结果范围10.04%~23.03%,GS的结果范围是9.57%~16.58%.从整体来看,LS所得的结果比GS要好.这是由于GS所处理的变量总比LS要多.图 3还表明:当δ增大时,结果数据量会增大,与理论分析相符,δ越大时,隐私强度越小,个人隐私越容易泄露,因此结果数据量越大是合理的;而当eε增大时,结果数据量反而会随之减小,这也与理论分析相符,eε越大,隐私强度越大,个人隐私越不容易泄露,因此结果数据量越小是合理的.最后,站点B的结果数据量总比站点A的结果数据量大,这与站点所拥有事务的平均事务长度有关,站点A的事务平均长度为5.66,站点B的事务平均长度为4.13,因此站点B的每个约束条件所含项数平均来说比站点A的要少,站点B的结果数据量总会比站点A的多是合理的.
图 4给出了当参数eε与δ指定时,事务数|T|与项集数|U|对GS执行结果的影响.实验令eε=1.1,δ=0.8.图 4表明:事务数|T|较小时对结果数据量有一定的影响,而|T|到一定值时不再是影响结果的主要因素;项集数|U|对结果影响较大,随着项集数|U|的增大,得到的结果数据量减少.因为|U|越大,约束条件越复杂,最优解越小,与理论分析相符,是合理的.
图 4(Fig.4)
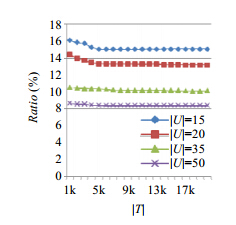
Fig.4
Result of GS vs. |T|,|U|图 4
事务数|T|、项集数|U|对GS执行结果的影响
4.3 Top-K项
图 5给出了全局解决方案与局部解决方案输出数据集的效用性.考查指标为Top-K项的保留百分比,即p=|FIÇFI¢|/k,其中,FI为原事务数据集支持计数排在前k位的项的集合,FI¢为输出数据集支持计数排在前k位的项的集合.图 5表明,GS的执行效果比LS要好.这是因为GS基于全局的项集,对项的支持计数的顺序保持良好.而LS基于局部的项集,尽管局部项的顺序能有很好的保持,但组合后这种保持被打破,因此,GS的Top-K项保持效果比LS好是合理的.
图 5(Fig.5)
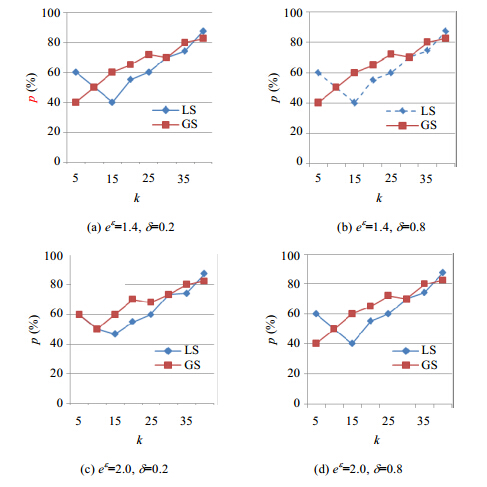
Fig.5
Retention Top-K items of LS and GS图 5
LS与GS对Top-K项的保持性
4.4 LS执行时间分析
图 6显示了LS求解优化问题的执行时间,实验令eε=1.4,δ=0.5.图 6表明:当项集数|U|较小时,LS的执行时间随着事务数|T|的增加而增长,但增长速率较缓慢,导致曲线较平缓;而当项集数|U|较大时,执行时间的增长速率较大,导致曲线较陡峭.可见,项集数|U|是影响LS执行时间的主要因素.另有实验表明:当|U|>60时,在预设定时间内没有执行完成.
图 6(Fig.6)
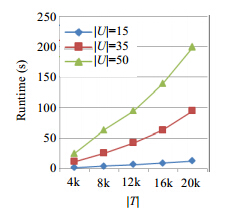
Fig.6
Runtime of LS vs. |T|,|U|图 6
事务数|T|、项集数|U|对LS执行时间的影响
4.5 GS复杂度分析
GS的计算与通信代价发生在Marquardt算法的每次迭代中,因此只要分析GS第(4)步~第(7)步的通信代价与计算复杂度.表 3中假设数量积和协议的通信代价为O(t¢(z)),其中,z为向量长度,t¢(z)为所使用的安全数量积协议的复杂度表达式;假设数量积和协议的计算复杂度为O(t(z)),其中,z为向量长度,t(z)为所使用的安全数量积协议的复杂度表达式.
表 3(Table 3)
Table 3 Communication cost and computational complexity of GS表 3 GS的通信代价与计算复杂度
通信代价
计算复杂度
第(4)步
0
O((m+n)2)
第(5)步
O((m+n)xt¢(m+n))
O((m+n)xt(m+n))
第(6)步
0
O((m+n)2)
第(7)步
0
O(m+n)
Marquardt迭代N次
O(Nx(m+n)xt¢(m+n))
O(Nx((m+n)xt(m+n)+O((m+n)2)))
Table 3 Communication cost and computational complexity of GS表 3 GS的通信代价与计算复杂度
5 结束语
本文针对分布式结构下事务数据发布的隐私保护问题,提出一种差分隐私发布策略.基于差分隐私,构造分布式非线性规划模型,最优化目标函数使结果效用性最大化.设计两种解决方案求解该模型:第1种是基于安全数量积协议的全局解决方案;第2种是基于组合定理的局部解决方案.理论分析与实验结果证明:本文提出的发布策略在保护隐私的同时最大化结果效用,且计算与通信是安全的.下一步工作中,将讨论水平分布环境下事务数据发布问题,以及针对不同的应用场景提出更多的效用性目标函数.
参考文献
[1]
Zhou SG, Li F, Tao YF, Xiao XK. Privacy preservation in database applications: A survey. Chinese Journal of Computers, 2009, 32(5):847-861 (in Chinese with English abstract).
[2]
Savasere A, Omiecinski ER, Navathe SB. An efficient algorithm for mining association rules in large databases. In: Proc. of the 21th Int'l Conf. on Very Large Data Bases (VLDB). San Francisco: Morgan Kaufmann Publishers, 1995. 432-444.
[3]
Agrawal R, Srikant R. Fast algorithms for mining association rules. In: Proc. of the 20th Int'l Conf. on Very Large Data Bases (VLDB). San Mateo: Morgan Kaufmann Publishers, 1994. 487-499.
[4]
Adar E, Weld DS, Bershad BN, Gribble SD. Why we search: Visualizing and predicting user behavior. In: Proc. of the 16th Int'l Conf. on World Wide Web. Banff: ACM Press, 2007. 161-170.
[6]
Machanavajjhala A, Gehrke J, Kifer D, Venkitasubramaniam M. L-Diversity: Privacy beyond k-anonymity.ACM Trans. on Knowledge Discovery from Data (TKDD), 2007,1(1):3.
[7]
Fung BCM, Wang K, Chen R, Yu PS. Privacy preserving data publishing: A survey of recent developments.ACM Computing Surveys, 2010,42(4):1-53.
[8]
Hong Y, Vaidya J, Lu HB, Wu MR. Differentially private search log sanitization with optimal output utility. In: Proc. of the 15th Int'l Conf. on Extending Database Technology. Berlin: ACM Press, 2012. 50-61.
[9]
He Y, Naughton JF. Anonymization of set-valued data via top-down, local generalization. Proc. of the VLDB Endowment, 2009, 2(1):934-945.
[10]
Xu YB, Wang K, Fu AWC, Yu PS. Anonymizing transaction databases for publication. In: Proc. of the ACM SIGKDD Int'l Conf. on Knowledge Discovery and Data Mining (KDD). New York: ACM Press, 2008. 767-775.
[11]
Ghinita G, Kalnis P, Tao YF. Anonymous publication of sensitive transactional data. IEEE Trans. on Knowledge and Data Engineering, 2011,23(2):161-174.
[12]
Loukides G, Gkoulalas-Divanis A, Malin B. COAT: COnstraint-Based anonymization of transactions. . Knowledge and Information Systems, 2011,28(2):251-282
[13]
Terrovitis M, Mamoulis N, Kalnis P. Local and global recoding methods for anonymizing set-valued data. The VLDB Journal, 2011,20(1):83-106.
[14]
Terrovitis M, Mamoulis N, Kalnis P. Privacy-Preserving anonymization of set-valued data. Proc. of the VLDB Endowment, 2008, 1(1):115-125.
[15]
Xu YB, Fung BCM, Wang K, Fu AWC, Pei J. Publishing sensitive transactions for itemset utility. In: Proc. of the IEEE Int'l Conf. on Data Mining (ICDM). Piscataway: IEEE, 2008. 1109-1114.
[16]
Gkoulalas Divanis A, Loukides G. Utility-Guided clustering-based transaction data anonymization. Trans. on Data Privacy, 2012, 5(1):223-251.
[17]
Cao J, Karras P, Raïssi C, Tan KL. r-Uncertainty: Inference-proof transaction anonymization. Proc. of the VLDB Endowment, 2010, 3(1-2):1033-1044.
[18]
Kifer D. Attacks on privacy and deFinetti's theorem. In: Proc. of the 35th SIGMOD Int'l Conf. on Management of Data. New York: ACM Press, 2009. 127-138.
[19]
Narayanan A, Shmatikov V. Robust de-anonymization of large sparse datasets. In: Proc. of the IEEE Symp. on Security and Privacy.New York: IEEE, 2008. 111-125.
[20]
Ghinita G, Tao Y, Kalnis P. On the anonymization of sparse high-dimensional data. In: Proc. of the Int'l Conf. on Data Engineering (ICDM). Piscataway: IEEE, 2008. 715-724.
[21]
Dwork C. Differential privacy in new settings. In: Proc. of the Annual ACM-SIAM Symp. on Discrete Algorithms. New York: ACM Press, 2010. 174-183.
[22]
Dwork C. Differential privacy: A survey of results. Lecture Notes in Computer Science, Heidelberg: Springer-Verlag, 2008: 1-19.
[23]
Dwork C, Mcsherry F, Nissim K, Smith A. Calibrating noise to sensitivity in private data analysis. Lecture Notes in Computer Science, Heidelberg: Springer-Verlag, 2006. 265-284.
[24]
Xiao X, Wang G, Gehrke J. Differential privacy via wavelet transforms. IEEE Trans. on Knowledge and Data Engineering (ICDE), 2011,23(8):1200-1214.
[25]
Hay M, Li C, Miklau G, Jensen D. Accurate estimation of the degree distribution of private networks. In: Proc. of the IEEE Int'l Conf. on Data Mining (ICDM). Piscataway: IEEE, 2009. 169-178.
[26]
Mcsherry F, Mironov I. Differentially private recommender systems: Building privacy into the net. In: Proc. of the 15th ACM SIGKDD Int'l Conf. on Knowledge Discovery and Data Mining.New York: ACM Press, 2009. 627-636.
[27]
Chen R, Mohammed N, Fung BCM, Desai BC, Xiong L. Publishing set-valued data via differential privacy. Proc. of the VLDB Endowment, 2011, 4(11):1087-1089.
[28]
Bayardo RJ, Agrawal R. Data privacy through optimal k-anonymization. In: Proc. of the Int'l Conf. on Data Engineering. Piscataway: IEEE, 2005. 217-228.
[29]
Lefevre K, Dewitt DJ, Ramakrishnan R. Mondrian multidimensional k-anonymity. In: Proc. of the Int'l Conf. on Data Engineering (ICDE). Piscataway: IEEE, 2006. 25
[30]
Ghosh A, Roughgarden T, Sundararajan M. Universally utility-maximizing privacy mechanisms. In: Proc. of the Annual ACM Symp. on Theory of Computing. ACM Press, 2009. 351-360.
[31]
Jiang W, Clifton C. A secure distributed framework for achieving k-anonymity. The VLDB Journal, 2006,15(4):316-333.
[32]
Mohammed N, Fung BC, Debbabi M. Anonymity meets game theory: Secure data integration with malicious participants. The VLDB Journal, 2011,20(4):567-588.
[33]
Jurczyk P, Xiong L. Distributed anonymization: Achieving privacy for both data subjects and data providers. In: Lecture Notes in Computer Science, Canada: Springer-Verlag, 2009. 191-207.
[34]
Mohammed N, Fung BCM, Hung PCK, Lee CK. Centralized and distributed anonymization for high-dimensional healthcare data. ACM Trans. on Knowledge Discovery from Data (TKDD), 2010,4(4):18.
[35]
Alhadidi D, Mohammed N, Fung BCM, Debbabi M. Secure distributed framework for achieving e-differential privacy. [doi: 10.1007/978-3-642-31680-7_7]
[36]
Machanavajjhala A, Kifer D, Abowd J, Vilhuber L. Privacy: Theory meets practice on the map. In: Proc. of the Int'l Conf. on Data Engineering. Piscataway: IEEE, 2008. 277-286.
[37]
Goldreich O. Foundations of Cryptography: Vol.2, Basic Applications. New York: Cambridge University Press, 2004. 615-626.
[38]
Yao AC. Protocols for secure computations. In: Proc. of the 23rd Annual Symp. on Foundations of Computer Science. New York: IEEE, 1982. 160-164.
[39]
Du W, Atallah MJ. Privacy-Preserving cooperative statistical analysis. In: Proc. of the Annual Computer Security Applications Conf.Piscataway: IEEE, 2001. 102-110.
[40]
Goethals B, Laur S, Lipmaa H, Mielikainen T. On private scalar product computation for privacy-preserving data mining. In: Proc. of the Information Security and Cryptology (ICISC 2004). Springer-Verlag, 2005. 23-25.
[41]
Vaidya J, Clifton C. Privacy preserving association rule mining in vertically partitioned data. In: Proc. of the ACM SIGKDD Int'l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2002. 639-644.
[42]
Rao SS. Engineering Optimization: Theory and Practice. Hoboken: Wiley, 2009. 422-425.
[43]
周水庚,李丰,陶宇飞,肖小奎.面向数据库应用的隐私保护研究综述.计算机学报,2009,32(5):847−861.















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









