







2.基於空間向量的余弦算法
2.1算法步驟
預處理→文本特征項選擇→加權→生成向量空間模型后計算余弦。
2.2步驟簡介
2.2.1預處理
預處理主要是進行中文分詞和去停用詞,分詞的開源代碼有:ICTCLAS。
然后按照停用詞表中的詞語將語料中對文本內容識別意義不大但出現頻率很高的詞、符號、標點及亂碼等去掉。如“這,的,和,會,為”等詞幾乎出現在任何一篇中文文本中,但是它們對這個文本所表達的意思幾乎沒有任何貢獻。使用停用詞列表來剔除停用詞的過程很簡單,就是一個查詢過程:對每一個詞條,看其是否位於停用詞列表中,如果是則將其從詞條串中刪除。
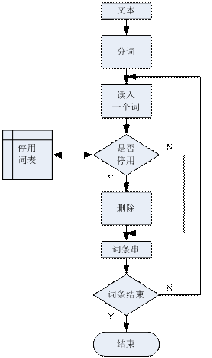
圖2.2.1-1中文文本相似度算法預處理流程
2.2.2文本特征項選擇與加權
過濾掉常用副詞、助詞等頻度高的詞之后,根據剩下詞的頻度確定若干關鍵詞。頻度計算參照TF公式。
加權是針對每個關鍵詞對文本特征的體現效果大小不同而設置的機制,權值計算參照IDF公式。
2.2.3向量空間模型VSM及余弦計算
向量空間模型的基本思想是把文檔簡化為以特征項(關鍵詞)的權重為分量的N維向量表示。
這個模型假設詞與詞間不相關(這個前提造成這個模型無法進行語義相關的判斷,向量空間模型的缺點在於關鍵詞之間的線性無關的假說前提),用向量來表示文本,從而簡化了文本中的關鍵詞之間的復雜關系,文檔用十分簡單的向量表示,使得模型具備了可計算性。
在向量空間模型中,文本泛指各種機器可讀的記錄。
用D(Document)表示文本,特征項(Term,用t表示)指出現在文檔D中且能夠代表該文檔內容的基本語言單位,主要是由詞或者短語構成,文本可以用特征項集表示為D(T1,T2,…,Tn),其中Tk是特征項,要求滿足1<=k<=N。
下面是向量空間模型(特指權值向量空間)的解釋。
假設一篇文檔中有a、b、c、d四個特征項
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









