







简介:《Sed与Awk第二版》是关于Linux和Unix文本处理工具Sed和Awk的权威指南。该书高清版提供深入理解及运用这两种命令行工具的教程,适用于程序员和系统管理员。Sed擅长流编辑、替换、删除、插入和打印操作,适用于非交互式文本数据处理。Awk则是一种特殊设计的编程语言,用于结构化文本数据处理,提供变量、条件表达式、循环及函数等。读者将学习Sed的基础操作和脚本编写,以及Awk的语法和程序设计,以解决实际问题。书中详细介绍了Sed和Awk的核心概念和操作,帮助读者提升在Linux或Unix系统中的文本处理能力。 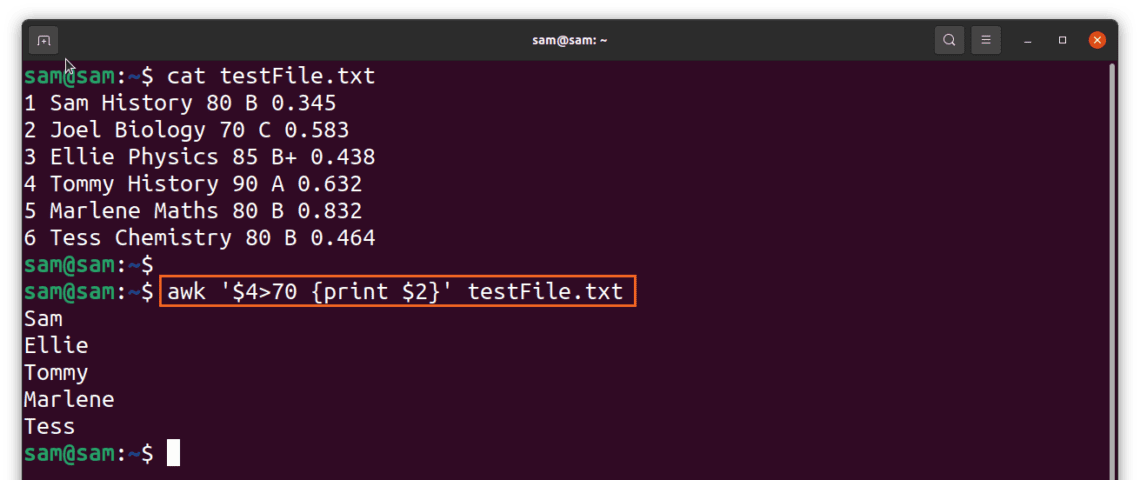
1. Linux和Unix文本处理概述
Linux和Unix系统由于其强大的文本处理能力而受到程序员和管理员的喜爱。文本处理通常涉及读取、过滤和转换文件中的数据。在多种文本处理工具中,Sed和Awk因其强大的功能、简洁的语法和强大的脚本编写能力而脱颖而出。
Sed是一个流编辑器,可以执行基于脚本的文本转换。它非常适合于快速编辑大量文本,例如文件替换、插入和删除操作。Sed通过使用正则表达式作为搜索模式来定位和转换文本,让复杂的文本处理任务变得简单化。
Awk则是一种编程语言,用于对文本文件进行模式扫描和处理。它能够处理结构化数据,并提供了完整的编程构造,例如条件语句、循环和数组。Awk的设计理念是让用户能够编写简短的程序来自动化处理和报告生成,这使得它在日志分析和报告任务中非常有用。
这两个工具都可以在Shell脚本中使用,以实现复杂的文本处理任务。在接下来的章节中,我们将深入探讨Sed和Awk的具体应用,它们的操作方法和高级应用技巧。通过阅读本文,您将能够掌握如何在Linux和Unix环境中高效处理文本数据。
2. Sed命令行工具详解
2.1 Sed的基本使用方法
2.1.1 Sed的模式空间概念
Sed(Stream Editor)是一个流编辑器,它能够执行文本转换。在Sed处理文本时,首先会将文本读入一个称为“模式空间”(pattern space)的临时缓冲区,然后在该空间中执行用户指定的命令,并将结果输出到标准输出。
一个重要的概念是Sed处理的是单行文本,即它每次处理一个模式空间。当一行文本被读入模式空间,Sed会对这个模式空间执行一系列命令,然后将结果输出,模式空间被清空,并继续处理下一行。模式空间的这个特性使得Sed非常适合用来进行单行文本的变换。
sed 's/old/new/' file
上面的命令使用了Sed的替换功能,它会读取 file 中的文本,将每一行中的第一个 old 替换为 new 。
2.1.2 Sed的地址选择
Sed支持地址选择,它允许你指定命令应用于哪些行。地址可以是行号、正则表达式或范围。
例如,如果你想只替换第三行中的某个文本,可以这样操作:
sed '3s/old/new/' file
如果你想替换从第三行到第五行的内容,可以使用:
sed '3,5s/old/new/' file
如果你想要基于正则表达式选择行,可以使用:
sed '/pattern/s/old/new/' file
这里, pattern 是要匹配的正则表达式,Sed将只对匹配该模式的行执行替换操作。
2.2 Sed的高级功能
2.2.1 替换与插入文本
Sed的替换命令( s )是处理文本的强有力工具。除了基本替换,还可以指定要替换的文本的出现次数,或者使用不同的分隔符,以避免分隔符在替换文本中出现的冲突。
sed 's/old/new/2' file # 只替换第二处出现的old
sed 's|old|new|' file # 使用不同的分隔符
sed 's/old/new/g' file # 全局替换,全文每处出现的old都会被替换
插入文本是Sed的另一个有用功能。你可以使用 i 命令插入文本到指定行的前面,使用 a 命令插入文本到指定行的后面。
sed '3i\
This is an inserted line.
' file
sed '3a\
This is an appended line.
' file
2.2.2 删除与打印指定行
删除行使用 d 命令,并可以指定行号或模式。
sed '3d' file # 删除第三行
sed '/pattern/d' file # 删除包含模式的行
打印行使用 p 命令,这个命令可以用来输出修改后的模式空间。
sed -n '3p' file # 打印第三行内容,-n选项抑制默认的打印行为
2.3 Sed脚本的编写与调试
2.3.1 编写Sed脚本的技巧
编写Sed脚本时,应考虑以下技巧: - 分步处理 :先测试单个命令,再逐步添加复杂性。 - 注释脚本 :使用 # 字符在脚本中添加注释,以方便理解。 - 合理使用分隔符 :使用不易在模式或替换文本中出现的字符作为分隔符。
一个简单的Sed脚本示例:
# Sed script to replace 'foo' with 'bar'
s/foo/bar/g
2.3.2 调试Sed脚本的方法
调试Sed脚本时可以使用以下方法: - 逐行输出 :使用 -n 和 p 来逐行查看处理结果。 - 单独测试命令 :将命令写成单独的行,在不同数据集上测试。 - 添加打印命令 :在需要观察的位置插入 p 命令,检查模式空间内容。
如果Sed脚本行为不符合预期,可以通过逐行执行脚本和逐步添加命令来查看和定位问题。
3. Awk编程语言精要
Awk是一种用于数据提取、报告生成和文本转换的编程语言。它的名字来源于它的创始人Alfred Aho、Peter Weinberger和Brian Kernighan的姓氏的首字母。Awk程序设计语言在处理文本和数据流方面非常强大,广泛应用于文本处理和数据挖掘任务中。其编程模型基于模式和动作的组合,让程序员能够以简洁和富有表达力的方式处理文本文件。
3.1 Awk的基本语法和结构
3.1.1 Awk的记录和字段概念
Awk程序将输入的数据视为一系列记录,而每个记录又被进一步划分为多个字段。默认情况下,记录是以换行符为分隔符,字段则是通过空白字符进行分隔。Awk的记录通常对应输入文本中的一行,而字段则对应于行中的一个或多个单词或字符串。
Awk程序通过操作这些记录和字段来完成任务,比如打印特定字段、计算统计数据等。Awk语言的一个重要特点是自动处理输入的记录分隔符和字段分隔符。程序员可以自行设置这些分隔符,来适应不同格式的文本数据。
awk 'NR==5 {print $3}' filename
上面的代码示例打印了文件名为 filename 中第五行的第三个字段。 NR 是一个内置变量,表示当前记录的编号(行号), $3 指的是当前行的第三个字段。
3.1.2 Awk的模式匹配基础
Awk提供了多种模式匹配机制,允许程序员定义在特定条件下执行动作。模式可以是正则表达式、比较表达式、复合表达式等。当输入记录与某个模式匹配时,Awk会执行该模式后定义的动作。
以下是一个简单的模式匹配的例子:
awk '/^ERROR/ {print "Found an error: "$0}' filename
这段代码会查找所有以"ERROR"开头的行,并打印一条消息"Found an error:",随后是匹配的整行文本。这是一个正则表达式模式匹配的例子,它演示了如何用Awk检测并报告日志文件中的错误信息。
3.2 Awk的模式与动作
3.2.1 模式的应用实例
Awk中的模式是匹配输入记录的条件,当一个记录满足给定的模式时,相关的动作就会执行。Awk内置了大量的模式类型,最常见的包括:
-
/pattern/:正则表达式模式匹配 -
BEGIN:在处理任何输入之前执行的动作块 -
END:在处理完所有输入后执行的动作块 -
condition:条件表达式,例如$1 > 10
例如,以下代码使用了一个条件表达式模式来检查文件中的每一行,如果第一字段大于10,则打印该行:
awk '$1 > 10' filename
3.2.2 动作的编写与应用
Awk程序中的动作是一系列由大括号 {} 括起来的语句。如果模式匹配成功,Awk将执行与之关联的动作。默认动作是打印当前记录,但可以自定义为任何有效的Awk语句。
例如,下面的代码将对文件中第一字段的数值进行累加,并在处理完所有记录后打印总和:
awk '{sum+=$1} END {print sum}' filename
这段代码中, sum+=$1 定义了一个动作,它在每个匹配的记录上执行。 END 块定义了当所有输入记录都已处理完毕后执行的动作。 sum 是用于存储累加和的变量,它在 BEGIN 块中可以初始化为零。
3.3 Awk的内置函数与数组
3.3.1 字符串和数学函数的应用
Awk内置了许多有用的函数,包括字符串处理函数和数学函数,它们可以简化复杂的文本操作。例如, length() 函数用于获取字符串的长度, substr() 函数用于提取字符串的一部分, sin() , cos() 等数学函数用于进行数值计算。
awk '{print length($0)}' filename
上面的代码会打印输入文件的每一行的长度。
3.3.2 数组的使用与管理
数组是Awk中处理数据的强大工具,尤其是在处理复杂数据结构和需要索引集合时。Awk数组以字符串为索引,可以存储任意类型的值。索引可以是数字或字符串。
awk '{array[$1]++} END {for (item in array) print item, array[item]}'
这个例子创建了一个数组,以每个记录的第一字段作为索引,并对每个索引出现的次数进行计数。 END 块则遍历数组,打印出每个索引和对应的计数。
Awk数组的管理包括遍历数组的元素,常用的方法是使用 for 循环遍历数组的键(索引),然后访问对应的值。Awk语言还提供了 delete 语句来从数组中移除元素。
以上是第三章关于Awk编程语言精要的介绍,我们会继续详细讲解Awk的高级用法和场景应用。接下来,我们将进入第四章,学习如何使用Sed和Awk进行数据提取、格式化和转换。
4. 数据提取、格式化和转换
在处理日常的IT任务时,数据提取、格式化和转换是核心操作,尤其在文本处理和日志分析工作中显得尤为关键。Linux和Unix系统提供了Sed和Awk这样的强大工具来执行这些任务。本章将深入探讨如何使用Sed和Awk来提取、格式化和转换数据,同时将提供一系列技巧和策略,以优化这些工具在数据处理中的应用。
4.1 数据提取技巧
4.1.1 使用Sed和Awk进行数据抓取
Sed和Awk都是基于流的文本处理工具,它们通过读取输入流中的数据,然后根据指定的命令或脚本来处理这些数据,最后输出处理的结果。我们可以利用Sed和Awk来抓取所需的数据部分。
Sed
Sed可以通过正则表达式来匹配特定模式,并执行相应的替换、插入或删除操作。例如,假设我们有一个日志文件 access.log ,其中记录了网站的访问情况,我们想提取所有请求成功(HTTP状态码为200)的行。
sed -n '/^.* 200 .*$/p' access.log
这里的 -n 选项告诉Sed不打印所有行,而 /^.* 200 .*$/ 是一个正则表达式,它匹配包含"200"状态码的每一行,并且 p 命令指示Sed打印这些行。
Awk
Awk将输入的每一行视为由记录分隔符(默认为空格或制表符)分隔的多个字段。我们可以利用这一点来提取特定字段。例如,提取 /etc/passwd 文件中用户名和登录shell的信息。
awk -F':' '{ print $1, $7 }' /etc/passwd
这里 -F':' 设置字段分隔符为冒号, '{ print $1, $7 }' 指示Awk打印每行的第1个和第7个字段,通常是用户名和登录shell。
4.1.2 复杂数据的提取策略
在面对复杂的数据提取任务时,如需要处理嵌套的结构或从非标准格式的数据中提取信息,Sed和Awk也提供了强大的策略。
Sed
对于嵌套结构,如HTML或XML文档,Sed通常用于提取特定标签内的内容。但是,Sed在处理嵌套结构时能力有限,对于更复杂的情况,可能需要结合其他工具或编写更复杂的脚本。
sed -n '/<a href="[^"]*"/,/<\/a>/p' webpage.html
这个命令会打印出所有包含 <a href="..."> 和 </a> 标签的行。注意,这种方法在处理嵌套标签时可能不够稳健。
Awk
对于更复杂的数据提取任务,Awk提供了数组、内置函数和自定义函数等强大功能,可用来处理非线性数据。例如,从CSV文件中提取符合特定条件的所有记录。
BEGIN {
FS=","; # 设置字段分隔符为逗号
}
{
if ($3 >= 10) {
print $1, $2, $3; # 打印第三个字段值大于等于10的记录
}
}
4.2 数据的格式化与美化
文本数据的格式化是指以某种特定的样式来展示数据,使其更易于阅读和理解。Sed和Awk提供了多种格式化输出的选项。
4.2.1 格式化输出的技巧
Sed
使用Sed进行格式化输出相对简单,可以通过替换命令来美化输出。例如,将连续的空行替换为单个空行。
sed '/./,/^$/!d' access.log
这个命令使用了地址选择 '/./,/^$/' ,它匹配从包含至少一个字符的行到空行之间的所有行,然后使用 !d 删除这些行之间的空行。
Awk
Awk提供了多种格式化输出的选项。例如,可以使用 printf 函数来格式化数字和字符串。
BEGIN {
printf("%-10s %-20s %s\n", "ID", "Name", "Email");
}
{
printf("%-10d %-20s %s\n", $1, $2, $3);
}
这段代码会打印出具有对齐的列标题,每个字段都按照指定的宽度进行格式化。
4.2.2 使用Sed和Awk美化文本
Sed和Awk都可以用来美化文本,比如,可以对文件中的文本进行统一的缩进处理。
Sed
使用Sed来美化文本,比如对整个文档进行缩进处理。
sed 's/^/ /' unindented.txt
这个命令在每行的开始添加4个空格,从而实现缩进效果。
Awk
Awk同样可以用来美化文本。例如,可以给文本的每一行添加特定的前缀和后缀。
BEGIN {
print "/* Start of File */";
}
{
print "-- " $0 " --";
}
END {
print "/* End of File */";
}
该脚本在文件的开始和结束以及每行数据的前后添加了注释,用于标记文件内容的开始和结束。
4.3 数据转换与处理
在数据处理过程中,经常需要将数据从一种类型转换成另一种类型,例如,将字符串转换为日期格式或整数。
4.3.1 转换数据类型的技巧
Sed
Sed并不支持复杂的数据类型转换,但可以利用正则表达式来提取和格式化特定类型的数据。例如,提取一个数字字段。
sed -n 's/.*Score: \([0-9]*\).*/\1/p' result.txt
这里,我们提取了以"Score: "开头,后接数字的行中的数字部分。
Awk
Awk内部支持多种数据类型,包括字符串、数字和日期类型。Awk可以执行类型转换,例如,将字符串转换为整数。
{
print int($1); # 将第一个字段转换为整数并打印
}
4.3.2 数据转换中的常见问题及其解决方法
在进行数据转换时,可能会遇到格式不一致、丢失数据或数据类型不匹配等问题。处理这些问题时,可以采用如下策略:
- 对于格式不一致的问题,可以编写预处理脚本来统一输入格式;
- 对于丢失数据的问题,可以增加检查和错误处理逻辑,以确保所有必要的数据都已提供;
- 对于数据类型不匹配的问题,可以编写条件语句来处理不同类型的数据,例如,对字符串类型的数字执行算术运算之前先进行类型转换。
利用这些策略,我们可以有效地解决在数据提取、格式化和转换过程中遇到的问题。
在本章中,我们深入了解了Sed和Awk在数据提取、格式化和转换方面的用法和技巧。Sed和Awk是Linux/Unix系统中强大的文本处理工具,熟练掌握它们可以大大简化和加速数据处理任务。通过本章节的介绍,您应该能够利用Sed和Awk来解决复杂的数据处理问题,并优化数据的展示。在下一章节中,我们将继续探索日志文件分析与报告生成的高级技巧。
5. 日志文件分析与报告生成
5.1 日志文件的基本分析
日志文件是系统运行状态和事件的详细记录,它们对于系统监控、问题诊断和性能优化至关重要。理解日志文件的结构与特点是进行有效分析的第一步。
5.1.1 日志文件的结构与特点
日志文件通常包含时间戳、事件级别、消息和来源等信息。不同系统和服务的日志格式各异,但大多数遵循标准化的格式,例如Syslog和Apache日志格式。它们通常有固定或可预测的字段,以及一个可读的文本描述。例如,Apache日志文件通常包含如下字段:
***.*.*.* - - [25/May/2023:14:22:14 -0400] "GET /index.html HTTP/1.1" 200 1234
这个日志条目包含客户端IP地址、认证信息、日期和时间、请求详情、HTTP响应状态码和传输字节数。
5.1.2 利用Sed和Awk进行日志分析的策略
Sed和Awk是日志分析中不可或缺的工具。通过它们可以实现以下常见操作:
- 过滤日志条目,例如提取特定时间范围内的日志。
- 统计特定类型的事件或错误,这可以帮助快速定位问题。
- 提取关键信息,如用户IP地址、响应时间等,进行进一步的数据分析。
下面是一个使用Awk过滤Apache日志并提取每个请求的HTTP状态码的示例:
awk '{print $9}' access.log | sort | uniq -c | sort -nr
这里 $9 表示第九个字段,即HTTP响应状态码。 sort 和 uniq -c 用于统计每个状态码的出现次数。 sort -nr 是将结果以数值形式降序排列。
5.2 数据转换为报告的过程
5.2.1 从数据分析到报告生成
将数据转换为报告涉及到从原始日志中提取信息,处理这些信息并生成清晰的报告。这可能涉及到多种工具和技术。例如,可以将Sed和Awk用于数据提取和初步处理,然后使用像Python这样的脚本语言来生成格式化的报告。
5.2.2 实现自动化报告的脚本编写
自动化报告需要将日志分析脚本和报告生成脚本结合起来。这里是一个非常简单的Python脚本示例,它读取一个文本文件,计算每个状态码的出现次数,并打印出一个简单的报告:
import collections
# 假设status_codes.txt包含从日志文件中提取的状态码列表
with open('status_codes.txt', 'r') as ***
***
***'Status Code: {status.strip()} - Count: {count}')
该脚本使用Python的collections.Counter类自动计算每个状态码的出现次数,并打印出一个简单的报告。这个例子仅用于说明,实际应用中报告会更加复杂和详细,并且可能会包括图表和其他视觉元素。
在实际操作中,可以将Sed和Awk脚本集成到Python脚本中,或使用shell脚本将各个部分串联起来,实现一个完整的自动化报告流水线。这不仅节省了时间,而且提高了报告的准确性和可靠性。通过定期运行这样的脚本,可以保持对系统运行状态的持续监控和快速响应。
6. 非交互式操作与脚本编写
在现代的IT操作中,非交互式操作已成为自动化处理任务和提高效率的关键。本章节将深入探讨非交互式操作的原理以及脚本编写的最佳实践,从而帮助读者有效提升工作效率,实现自动化管理。
6.1 非交互式操作的原理
非交互式操作是指在没有任何人工干预的情况下,通过脚本、程序或命令行工具执行任务的过程。相较于交互式操作,它能够确保任务按照预定的方式和顺序执行,减少人为错误,提高操作的可重复性。
6.1.1 交互式与非交互式操作的区别
在交互式操作中,用户需要对命令行的提示进行响应,这在处理简单的命令或故障排查时非常有用。然而,在进行日常重复的任务时,交互式操作效率较低且易出错。非交互式操作通过预设的脚本或命令行指令来执行任务,无需人工干预,大大提高了操作的效率和一致性。
6.1.2 实现非交互式操作的场景分析
非交互式操作在多个场景中非常有用,例如:
- 批量文件操作 :对服务器上的多个文件执行一致的命令,如重命名、移动或修改权限。
- 系统监控和报告 :通过定期运行的脚本收集系统信息,并生成报告。
- 自动化部署 :部署应用程序时自动执行配置和环境设置。
- 日志文件分析 :定期分析日志文件,自动检测和响应异常。
6.2 脚本编写的最佳实践
编写有效的脚本是实现非交互式操作的关键。良好的脚本结构、清晰的逻辑以及优化和重构的能力,都是脚本编写者需要掌握的技能。
6.2.1 脚本的结构化设计
脚本的结构化设计是提高脚本可读性和可维护性的核心。下面是一些结构化设计的最佳实践:
- 模块化 :将脚本分解为可重复使用的函数,以便于维护和测试。
- 条件判断 :合理利用条件语句处理不同的情况,确保脚本在各种环境下都能稳定运行。
- 错误处理 :实现错误检测机制,确保在出错时脚本能给予反馈,并按预定方案恢复或退出。
6.2.2 脚本的优化与重构技巧
脚本优化不仅是为了提高性能,也包括提高代码的可读性和可维护性。以下是脚本优化和重构的一些技巧:
- 使用变量 :合理使用变量,避免重复代码,并方便后续的维护和修改。
- 避免全局变量 :尽可能限制变量的作用域,以减少潜在的冲突。
- 代码注释 :为复杂的逻辑和不易理解的代码块添加注释,使他人或未来的自己易于理解。
- 代码审查 :定期进行代码审查,可以与同行交流,获取反馈,并持续改进脚本。
下面是一个使用Bash编写的简单示例脚本,用于批量修改文件名:
#!/bin/bash
# 批量修改目录下的所有文件名,添加前缀"new_"
# 定义文件夹路径
folder_path="/path/to/your/folder"
# 进入目录
cd $folder_path
# 遍历文件并添加前缀
for file in *; do
if [ -f "$file" ]; then
mv "$file" "new_$file"
fi
done
逻辑分析:
这个脚本使用了几个基本的Bash命令来实现其功能:
-
#!/bin/bash声明脚本使用Bash shell执行。 - 变量
folder_path被定义为需要操作的文件夹路径。 -
cd $folder_path命令进入目标目录。 - 循环
for file in *遍历目录中的所有文件。 -
if [ -f "$file" ]判断当前遍历到的项是否为文件。 -
mv "$file" "new_$file"使用mv命令重命名文件,添加前缀"new_"。
参数说明:
-
folder_path:需要提前定义的目标文件夹路径。 -
*:表示匹配当前目录下的所有项。 -
-f:用于测试文件是否存在,确保脚本不会误操作目录。
通过此示例脚本,我们可以看到脚本编写的一些基本原则:清晰的注释、合理的变量使用和简洁的逻辑结构。按照这些原则,即使是非常复杂的任务也可以被有效地封装在一个可维护的脚本中。
脚本编写是一个不断学习和改进的过程。通过实践、优化和重构,我们可以持续提升脚本的质量,实现更高水平的自动化任务处理。
7. Sed与Awk的高级应用
7.1 模式匹配的高级技巧
7.1.1 正则表达式在Sed和Awk中的应用
Sed和Awk工具的强大之处在于它们对正则表达式的支持,允许用户进行复杂的文本搜索和处理。例如,Sed可以使用正则表达式快速替换模式,而Awk则可以通过正则表达式对输入记录进行筛选。
在Sed中,你可以使用如下命令来匹配所有以“error”开头的行,并将其替换为“ERROR”:
sed -e 's/^error/ERROR/' filename
而在Awk中,你可以定义一个模式来只处理包含特定模式的记录,如下:
awk '/error/ { print }' filename
7.1.2 复杂文本的模式匹配策略
在处理复杂文本数据时,可能需要使用到更高级的正则表达式特性。例如,利用正则表达式的捕获组功能,可以从文本中提取特定的数据:
sed -e 's/Date: \(.*\)/\1/' filename
上述命令将匹配以“Date:”开头的行,并将该行中的日期提取出来。在Awk中,你可以使用类似的捕获组来分割记录:
awk -F '[:]' '{ print $2 }' filename
这段代码会将每行以冒号为分隔符,并打印出第二个字段,也就是日期部分。
7.2 字段操作与控制流程
7.2.1 字段的提取与操作技术
在文本处理中,字段是基本的数据单元。使用Sed和Awk,我们可以轻松地提取和操作这些字段。Sed并不直接支持字段的概念,但是可以通过正则表达式匹配特定字段。而Awk则直接以字段为操作对象。
例如,在Awk中,你可以通过内置变量 $1 、 $2 等来访问第1个、第2个字段等,如下:
awk '{ print $1 }' filename
这段代码将会打印每行的第一个字段。
7.2.2 控制流程在文本处理中的应用
控制流程,如条件判断和循环,在文本处理中也十分有用。使用Awk可以实现复杂的控制流程,例如:
awk 'NR == 1 || NR == 10 { print "This is a special line" }' filename
此代码段将会在处理到第1行和第10行时,输出“这是一个特殊的行”。
7.3 高级内置变量与函数应用
7.3.1 字段分隔符与记录分隔符的定制
Awk允许你自定义字段分隔符(FS)和记录分隔符(RS),这让你可以按照自己定义的格式来解析文本。例如:
awk 'BEGIN { FS="," } { print $2 }' filename.csv
这段代码设置了字段分隔符为逗号,因此 $2 指的是每行中的第二个逗号分隔的字段。
而记录分隔符可以通过RS变量来设置:
awk 'BEGIN { RS="\n\n" } { print "Record:" $0 }' filename
这里,两个换行符作为记录分隔符,意味着每一组连续的空行代表一个记录。
7.3.2 length()、split()和printf()函数的高级用法
Awk内置的 length() 函数可以返回字符串的长度,而 split() 函数则可以将字符串分割到数组中。
例如,使用 length() 来获取每行的长度:
awk '{ print length($0) }' filename
使用 split() 将一个字符串分割为数组:
awk 'BEGIN { str="1,2,3,4,5"; split(str, arr, ",") } { print arr[1] }' filename
最后, printf() 函数可以提供更高级的格式化输出功能,类似于C语言中的printf函数:
awk '{ printf "%-10s %-5d\n", $1, $2 }' filename
这将把每行的第1个字段左对齐,占据10个字符宽度,第2个字段占据5个字符宽度,并换行输出。
通过这些高级技巧,你可以更加灵活地使用Sed和Awk处理复杂的文本数据和执行强大的自动化脚本任务。
简介:《Sed与Awk第二版》是关于Linux和Unix文本处理工具Sed和Awk的权威指南。该书高清版提供深入理解及运用这两种命令行工具的教程,适用于程序员和系统管理员。Sed擅长流编辑、替换、删除、插入和打印操作,适用于非交互式文本数据处理。Awk则是一种特殊设计的编程语言,用于结构化文本数据处理,提供变量、条件表达式、循环及函数等。读者将学习Sed的基础操作和脚本编写,以及Awk的语法和程序设计,以解决实际问题。书中详细介绍了Sed和Awk的核心概念和操作,帮助读者提升在Linux或Unix系统中的文本处理能力。















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









