







今天介绍一篇 CVPR 2019论文:
ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
域适应在语义分割中的应用,主要方法是最小化熵
概览
问题:在语义分割领域,利用源域有标签的数据,解决目标域无标签的问题。
方法:引入熵loss,降低目标域的熵。
动机
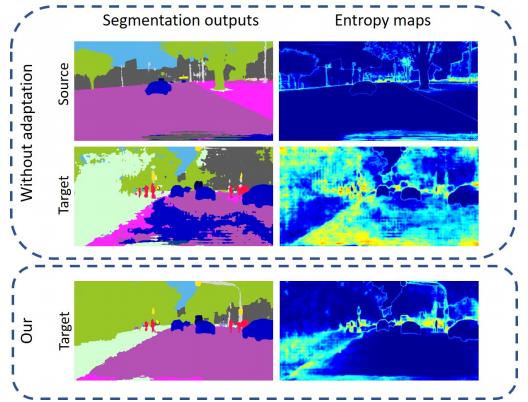
左上角是源域的语义分割图。我们利用源域的数据(有充足的标记好的数据)可以训练一个准确率很高的语义分割网络。但是目标域没有标签,我们如果直接将目标域的图片输入到源域的网络中,会得到第2行第1列的图像。我们可以看到路这个类分得很不好。
作者观察到:源域上的监督学习训练出来的卷积神经网络模型,在与源域相似的图片上预测出来的语义分割图是低熵。而在目标域上的预测图则是高熵。如下图所示。左边是语义分割图,右边计算整个图熵值结果的可视化。
源域中的预测熵图(prediction entropy maps)像是边缘检测:在边缘部分有很高的响应值。
而在目标域,预测熵图并不是这么明显。语义分割图中有很多噪声,会造成额外的熵增。
由此,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









