








1,目标:
爬取贴吧每一贴,楼主图,并保存。
由于图片大多是楼主发的,如果全部查找会浪费很多时间。
2,分析
我选择爬取的贴吧为图吧,你们可以选择自己想要爬取的贴吧。
2.1,获取页面
我们将爬取页面的代码写成一个get_html()方法,给他传入url参数
代码如图:
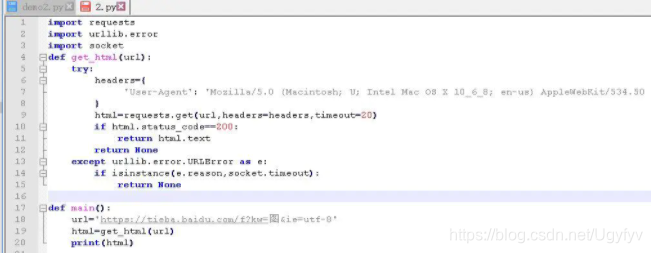
获取正常,没问题。
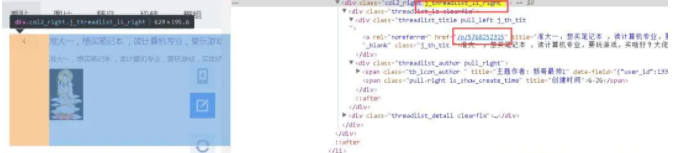
我们用chrome的开发者模式来分析每个贴的连接,用定位定位一个帖子,这样方便我们快速的去查找我们想要的信息。
如图:
2.2利用正则表达式找出我们想要的连接
通过查找,我们发现每个贴都是在class=“col2_right j_threalist_li/_right”下
我们可以让他成为一个标志位,通过它继续往下找,他有两个类名,我们选择后者即可。
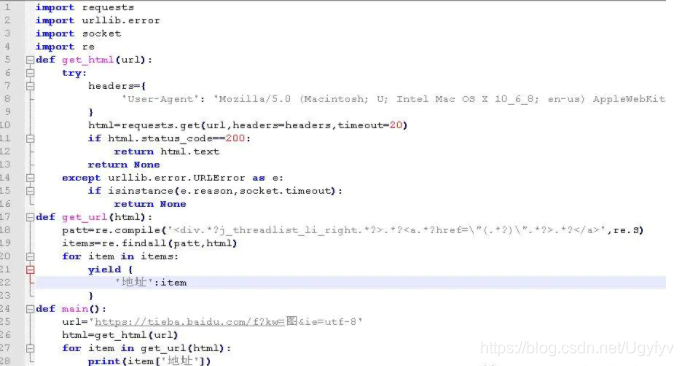
<div.*?j_threadlist_li_right.*?>.*?<a.*?href="(.*?)".*?>(.*?)</a>
返回的是一个数组,为了好看我们以字典的方式返回,用yield我们可以理解为返回值,在python基础里会讲,我们将获取的页面作为参数传进去,实现get_url方法。
如图:
我们来打印一下,看一下获取的是什么?
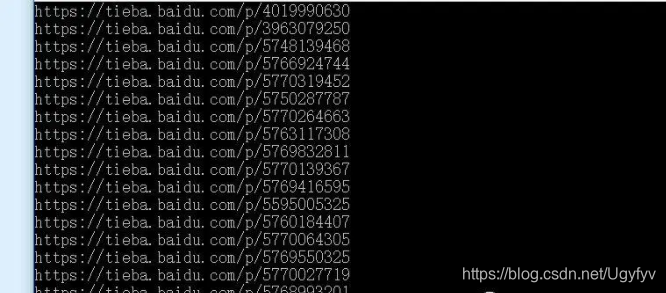
结果如图:

很明显,我们需要来拼接一下,获取完整的url,我们点击一个进入,可以发现,url是这样的:贴吧404
得到链接后,我们需要再次发送请求,获取到每个贴的内容,即调用我们上面写好的get_html()方法即可。
2.3找到每个帖子楼主发的图片链接
同样的方式,打开开发者模式,找的图片,找出标志位,写出正则,这里就不详细说了,正则为:
实现get_img_url()方法:

结果图为:
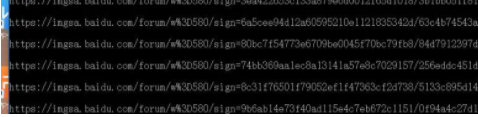
2.4获取到图片地址后,自然是要下载下来实现write_to_file()方法
下载图片,在上篇文章上已经有实例,
连接:python第二大神器requests
这里直接上代码图:

里面的正则是用来作为图片名字的,time.sleep(2)是为了爬取慢点
太快会无响应或者报错。
下面我们试一下效果:

我们来修改一下,来爬取第一页贴种的所有贴,获取楼主贴的总页数
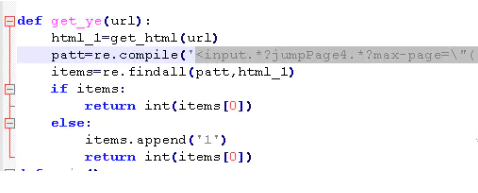
和上面同样的方式找到总页数,并写出获取总页数的正则:
实现get_ye方法,同时点击只看楼主,url会多出see_lz=1
如图:
2.5由于有些贴吧的贴子很多,我们就选择获取前十页内容,当然你也可以写个方法换取所有页
这里就不实例了,在贴吧里点击下一页我们发现url多出pn=50,由此我们知道50为偏移量,即一页有50个帖子pn=n 是n+1到n+50帖子
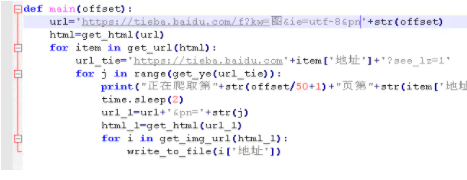
2.6整合一下代码,我们用main()方法来调用上面的方法。
如图:
















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









