






import json
import numpy as np# 计算皮尔逊系数
def pearson_score(dataset, user1, user2):
if user1 not in dataset:
raise TypeError('User ' + user1 + ' not present in the dataset') if user2 not in dataset:
raise TypeError('User ' + user2 + ' not present in the dataset') # 提取两个用户都评分过的电影
rated_by_both = {} for item in dataset[user1]:
if item in dataset[user2]:
rated_by_both[item] = 1 num_ratings = len(rated_by_both)
# 都没有评分则是 0
if num_ratings == 0:
return 0 # 计算相同评分的平方值和
user1_sum = np.sum([dataset[user1][item] for item in rated_by_both])
user2_sum = np.sum([dataset[user2][item] for item in rated_by_both]) # 计算所有相同评分电影的评分的平方和
user1_squared_sum = np.sum([np.square(dataset[user1][item]) for item in rated_by_both])
user2_squared_sum = np.sum([np.square(dataset[user2][item]) for item in rated_by_both]) # 计算数据集乘积之和
product_sum = np.sum([dataset[user1][item] * dataset[user2][item] for item in rated_by_both]) # 计算皮尔逊相关度
Sxy = product_sum - (user1_sum * user2_sum / num_ratings)
Sxx = user1_squared_sum - np.square(user1_sum) / num_ratings
Syy = user2_squared_sum - np.square(user2_sum) / num_ratings
# 分母为0的处理
if Sxx * Syy == 0:
return 0 return Sxy / np.sqrt(Sxx * Syy)
if __name__=='__main__':
data_file = 'movie_ratings.json' with open(data_file, 'r') as f:
data = json.loads(f.read()) user1 = 'John Carson'
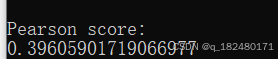
user2 = 'Michelle Peterson' print "\nPearson score:"
print pearson_score(data, user1, user2)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









