






对象的深拷贝和浅拷贝是编程中经常讨论到的一个话题。拷贝(copy),通常也可称作复制或克隆(clone),在Python语言中是指基于一个已有的对象通过复制内存的方式创建新对象的过程。我们可以先看看下面的代码,再来为大家解释什么是深拷贝和浅拷贝。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def eat(self, food_name):
print(f'{self.name}正在吃{food_name}.')
def __repr__(self):
return f'{self.name}: {self.age}.'
p1 = Person('王大锤', 18)
p2 = p1上面对的代码中,我们通过调用Person类的构造器创建了Person对象,并将其赋值为变量p1。通过变量p1,我们可以访问Person对象的属性并向该对象发出消息(如eat),这一点相信大家是非常清楚的。变量p1的值被保存在内存的“栈”空间中,而Person对象则被保存在内存的“堆”空间中,p1并不是真正的Person对象,而是堆空间上的Person对象的引用。关于“引用”这个词,如果你有C或者C++的基础,你可以将引用理解为指针或者地址,这是一种间接访问内存的方式。在Python或Java这样的语言中,引用就是一个指针,只不过是一个无法像C/C++那样进行运算的指针。
很显然,上面代码的最后一行,p2 = p1并没有创建新的Person对象,而只是让变量p2获得了变量p1的值,相当于给刚才创建的Person对象增加了一个新的引用,但是对象并没有增加。Python语言是通过引用计数再辅以标记清理和分代收集的机制来进行自动化的内存管理,引用计数不为0的对象,不会被垃圾回收。言归正传,如果上面的代码希望基于p1引用的Person对象创建出新的Person对象并赋值给p2,应该对代码做出如下所示的修改。
import copy
p1 = Person('王大锤', 18)
p2 = copy.copy(p1)上面的代码中,我们通过copy模块的copy函数实现了对p1所引用的Person对象的复制,相当于内存中又多了一个Person对象。我们可以用下面的方式来验证p1和p2引用的是两个不同的对象。
p1 == p2 # False
p2.name = '骆昊'
p2.age = 39
print(p1, p2) # 王大锤: 18. 骆昊: 39.那么,深拷贝跟浅拷贝的区别何在呢,我们对上面的代码稍加修改来加以说明。
import copy
class Car:
def __init__(self, brand, max_speed):
self.brand = brand
self.max_speed = max_speed
def __repr__(self):
return f'{self.brand}: {self.max_speed}'
class Person:
def __init__(self, name, age, car):
self.name = name
self.age = age
self.car = car
def __repr__(self):
return f'{self.name}: {self.age}'
p1 = Person('王大锤', 18, Car('QQ', 120))
p2 = copy.copy(p1)
p2.name = '骆昊'
p2.car.brand = 'Benz'
p2.car.max_speed = 280
print(p1, p1.car)
print(p2, p2.car)大家可以先花两分钟时间思考一下上面代码的执行结果,然后再看下面的讲解。
所谓的浅拷贝就是在拷贝对象时仅拷贝对象本身,并不拷贝对象所关联的其他对象。上面的代码中,我们对p1所引用的学生对象进行浅拷贝复制出一个新的Person对象并复制给p2。但是,Person对象关联的Car对象并没有被拷贝,所以内存中只有一个Car对象。当通过p2.car.brand和p2.car.max_speed修改了Car对象的属性时,我们发现p1.car也发生了变化,因为Car对象有且只有一个,所以无论p1.car还是p2.car访问的是内存中的同一个对象。
如果需要实现深拷贝,需要把上面的代码中给变量p2赋值的语句修改为p2 = copy.deepcopy(p1)。利用copy模块的deepcopy函数我们可以比较容易的实现深拷贝操作,这是Python标准库中封装好的函数,这一点相较于其他编程语言来说是比较方便的。类似的操作在Java中需要自己封装或者借助于三方库来实现。再次运行程序,看看输出的结果有什么变化。
到这里我来问大家一个问题,列表的切片操作是浅拷贝还是深拷贝?大家可以把自己的想法写到留言评论区一起讨论一下。给大家推荐一个叫Python Tutor的网站,它能够以可视化的方式执行我们的Python代码,让我们看到程序执行的过程中内存中发生了什么变化。下图就是刚才的程序在使用浅拷贝和深拷贝时内存的状况。
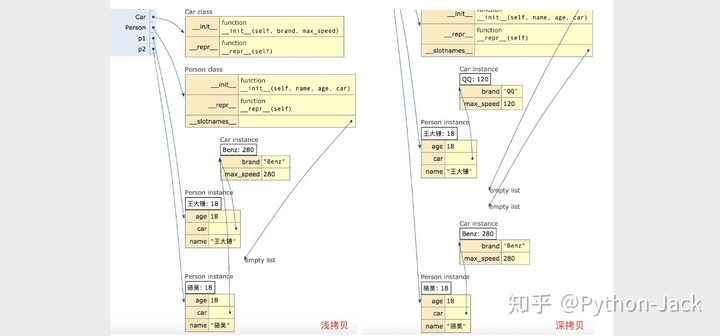
还有一个小技巧分享给大家。如果程序中需要创建大量对象,建议大家通过对象拷贝的方式来完成,因为对象的拷贝其实就是内存中数据的复制,它比调用构造器创建对象要快得多。我们可以先创建一个对象作为原型,再通过拷贝原型对象的方式创建更多的对象,这个做法就是设计模式中原型模式的践行。在Python中,如果希望给对象直接添加一个实现对象拷贝的方法(就像Java中每个对象都有一个clone方法),可以通过元类来实现,这样的话创建类的时候只要通过metaclass指定该元类就可以获得拷贝对象的方法,而且还可以通过一个参数来控制到底需要的是深拷贝还是浅拷贝,完整的代码如下所示。
import copy
class PrototypeMeta(type):
def __init__(cls, *args, **kwargs):
super().__init__(*args, **kwargs)
cls.clone = lambda self, is_deep=True:
copy.deepcopy(self) if is_deep else copy.copy(self)
class Car:
def __init__(self, brand, max_speed):
self.brand = brand
self.max_speed = max_speed
def __repr__(self):
return f'{self.brand}: {self.max_speed}'
class Person(metaclass=PrototypeMeta):
def __init__(self, name, age, car):
self.name = name
self.age = age
self.car = car
def __repr__(self):
return f'{self.name}: {self.age}'
p1 = Person('王大锤', 18, Car('QQ', 120))
p2 = p1.clone(is_deep=True) # 深拷贝
p3 = p1.clone(is_deep=False) # 浅拷贝关于深拷贝和浅拷贝的问题在面试的时候也经常出现,如果觉得这篇文章对你还是有那么点帮助的话,记得点赞或收藏哟!















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









