






本系列内容:
- Kafka环境搭建与测试
- Python生产者/消费者测试
- Spark接收Kafka消息处理,然后回传到Kafka
- Flask引入消费者
- WebSocket实时显示
版本:
spark-2.4.3-bin-hadoop2.7.tgz
kafka_2.11-2.1.0.tgz
------------------第3小节:Spark接收Kafka消息处理,然后回传到Kafka--------------------
import sys
from pyspark.sql.types import IntegerType
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, concat, array_join, concat_ws
from pyspark.sql.functions import split
from pyspark.sql.functions import window
if __name__ == "__main__":
# broker地址
bootstrapServers = "192.168.147.128:9092"
# subscribe:订阅
subscribeType = "subscribe"
# 主题
topics = "bigdata"
# 窗口大小:30秒
windowSize = 30
# 滑动窗口大小:15秒
slideSize = 15
windowDuration = '{} seconds'.format(windowSize)
slideDuration = '{} seconds'.format(slideSize)
spark = SparkSession.builder.appName("KafkaWordCount").getOrCreate()
# 读取流数据,并生成dataframe
# spark获取到的流数据,将放到这个dataframe中的value列
# dataframe包含:key、value、topic、partition、offset、timestamp、timestampType
# 这些列成为dataframe元素数据
# value:是二进制的字节数组,在使用时需要转为字符串
lines = spark.readStream.format("kafka").
option("kafka.bootstrap.servers", bootstrapServers).
option("subscribe", topics).
option('includeTimestamp', 'true').load()
# lines:中value列收到的数据格式如下:
# value = b'火车北站,11,25,47,56,70,83,84'
# 现在需要将这些数据进行分割,每一个数据作为一个单独的列
# 这里构造的words 也是一个dataframe,并且包含时间戳
# words结构转换为:["che_zhan","zhou1","zhou2"。。。。。] ===> ["车站","周一","周二"。。。。。]
words = lines.select(
split(lines.value, ',').getItem(0).alias('che_zhan'),
split(lines.value, ',').getItem(1).cast("int").alias('zhou1'),
split(lines.value, ',').getItem(2).cast("int").alias('zhou2'),
split(lines.value, ',').getItem(3).cast("int").alias('zhou3'),
split(lines.value, ',').getItem(4).cast("int").alias('zhou4'),
split(lines.value, ',').getItem(5).cast("int").alias('zhou5'),
split(lines.value, ',').getItem(6).cast("int").alias('zhou6'),
split(lines.value, ',').getItem(7).cast("int").alias('zhou7'),
lines.timestamp
)
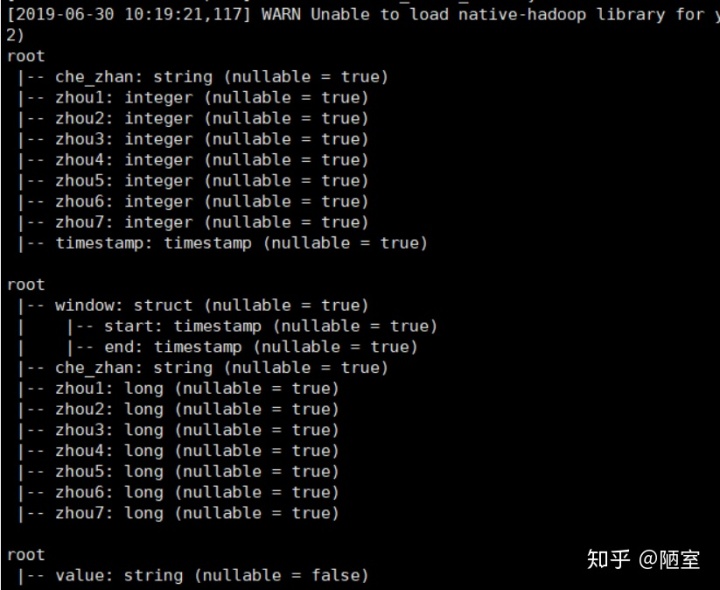
words.printSchema()
# 根据时间窗口的数据,按车站名称进行分组,统计每天的客流量
# windowedCounts结构转换为:["che_zhan","sum(zhou1)","sum(zhou2)"。。。。。]
windowedCounts = words.groupBy(
window(words.timestamp, windowDuration, slideDuration),
words.che_zhan
).sum('zhou1', 'zhou2', 'zhou3', 'zhou4', 'zhou5', 'zhou6', 'zhou7')
# windowedCounts中的列sum(zhou1),sum(zhou2)等列进行重命名
windowedCounts = windowedCounts.withColumnRenamed('sum(zhou1)', 'zhou1').
withColumnRenamed('sum(zhou2)', 'zhou2').
withColumnRenamed('sum(zhou3)', 'zhou3').
withColumnRenamed('sum(zhou4)', 'zhou4').
withColumnRenamed('sum(zhou5)', 'zhou5').
withColumnRenamed('sum(zhou6)', 'zhou6').
withColumnRenamed('sum(zhou7)', 'zhou7')
windowedCounts.printSchema()
# 将数据输出到控制台。这种方式不支持在dataframe中使用聚合函数。这里做个备注
# query = windowedCounts.writeStream.outputMode('append').format('console').start()
# query.awaitTermination()
# 注意:这里是重点,将数据写回kafka
# windowedCounts的所有列组合在一起,作为一个新的列value
# 为什么要这么做,以及注意事项见下图
last_df = windowedCounts.select(concat_ws(",", windowedCounts.che_zhan, windowedCounts.zhou1,
windowedCounts.zhou2, windowedCounts.zhou3,
windowedCounts.zhou4, windowedCounts.zhou5,
windowedCounts.zhou6, windowedCounts.zhou7).alias("value"))
last_df.printSchema()
# 将df输出到kafka
# outputMode:取值有 complete、update、Append
# complete:当dataframe结果表有更新时,全部输出到外部设备
# update:当dataframe结果表有更新时,受影响的行输出到外部设备
# Append:当dataframe结果表有更新时,把新加入的行输出到外部设备
# 操作中不存在聚合函数,那么受影响的只有新行,这时update和Append效果一样
# checkpointLocation:在流式处理中,在某一时刻出现故障、掉电等意外情况,流式计算就被中断。
# 当修复故障重新启动计算时,流式处理引擎可以从中断的位置继续计算。这是使用检查点和预写日志
# 的方式搞定的。这个检查点必须是HDFS兼容文件系统中的路径。为什么必须设计检查点,参见官方文档:
# http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#starting-streaming-queries
# Starting Streaming Queries 这一小节
# topic: 将生成的结果输出到 result 主题
query = last_df
.writeStream
.outputMode("update")
.format("kafka")
.option("checkpointLocation", "hdfs://localhost:9000/struct_streaming/checkpoint4")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("topic", "result")
.start()
query.awaitTermination()

程序编写完成,放到centos系统,使用如下命令运行:
步骤01:启动hdfs,因为检查点在hdfs上
./sbin/start-dfs.sh
步骤02:提交Spark应用
bin/spark-submit /tools/structured_kafka_wordcount.py 192.168.147.128:9092 subscribe bigdata
出现错误如下:
py4j.protocol.Py4JJavaError: An error occurred while calling o117.start.
: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot create directory /struct_streaming/checkpoint4. Name node is in safe mode.
The reported blocks 23169 needs additional 824 blocks to reach the threshold 0.9990 of total blocks 24018.退出安全模式
hdfs dfsadmin -safemode leave
重新提交,其中:
第1个root:words的结构,此时已经构造好了列
第2个root:windowedCounts的结构,这是滑动窗口调用聚合函数构造的列
第3个root:last_df的结构,这是合并列后,将要放入kafka的dataframe
注意,日志打印到这里,若是不包错就不会继续打印了。这种状态就是正确的,这个spark算子将作为一个常住服务运行,直到你终止。














 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









