







生成器表达式
语法
- (返回值 for 元素 in 可迭代对象 if 条件)
- 将列表解析式的 [] 换成 () 即可。
- 使用(),内部是for循环,,if条件语句可选
- 返回一个生成器
和列表解析式的区别
- 生成器表达式是按需要计算(或称惰性求值 、延迟计算),需要的时候才计算值
- 列表解析式是立即返回值
生成器
- 可迭代对象
- 迭代器
- 例1使用生成器表达式:
g =("{:04}".format(i) for i in range(1,5))
next(g)
for x in g:
print(x)
print('-----------')
for x in g:
print(x)
1234567
输出结果
0002
0003
0004
-----------
1234
解析:1.延迟计算;2.返回迭代器,可以迭代;3.从前到后走完一遍后,不能回头
- 例2:将例1改成列表解析式:
g =["{:04}".format(i) for i in range(1,5)]
for x in g:
print(x)
print('-----------')
for x in g:
print(x)
123456
- 输出结果
0001
0002
0003
0004
-----------
0001
0002
0003
0004
123456789
- 解析:1.立即计算;2.返回的不是迭代,返回可迭代对象列表;3.从前到后走完一遍,可以重新回头迭代
生成器和列表解析式对比
计算方法
- 生成器表达式延时计算,列表解析式立即计算
内存占用
- 单从返回值本身来说,生成器表达式省内存,列表解析式返回新的列表
- 生成器没有数据,内存占用极少,它是使用时一个个返回数据。如果将这些返回的数据合起来占用的内存和列表解析式差不多。但是它不需要立即占用这么多内存
- 列表解析式构造性的列表需要立即占用内存,不管你是否需要立即使用这么多数据
计算速度
- 单从计算时间看,生成器表达式耗时非常短,列表解析式耗时长
- 但是生成器本身并没有返回任何值,只返回了一个生成器对象
- 列表解析式构造并返回了一个新的列表,所以看起来耗时了
递归Recursion
- 函数直接或者间接调用自身就是 递归
- 递归需要有边界条件、递归前进段(计算的过程)、递归返回段(拿到返回值的过程)
- 递归一定要有边界条件
- 当边界条件不满足的时候,递归前进
- 当边界条件满足的时候,递归返回
递归要求
- 递归一定要有退出条件,递归调用一定要执行到这个退出条件。没有退出条件的递归调用,就是无限调用
- 递归调用的深度不宜过深
- Python对递归条用的深度做了限制,以保护解释器
- 超过递归深度限制,抛出RecursionReeor:maxinum recursion depth exceeded 超出最大深度
- 使用sys.getrecursionlimit()可查看递归层次限制,CPython 限制1000
import sys
print(sys.getrecursionlimit()) #输出结果 1000
123
递归的性能fib 35项比较
- for循环
import datetime
start = datetime.datetime.now()
a = 0
b = 1
n = 35
#循环实现
for i in range(n-1):
a, b = b, a + b
else:
pass # print(b) 9227465
delte
123456789101112
- 循环稍微复杂一些,但是只要不是死循环,可以多次迭代直至算出结果
- fib函数代码极简易懂,但是只能获取取到最外层的函数调用,内部递归结果都是中间结果。而且给定一个n都要进行近2n次递归,深度越深
递归总结
- 递归是一种很自然的表达,符合逻辑思维
- 递归相对运行效率低,每一次调用函数都要开辟栈帧
- 递归有深度限制,如果递归层次太深,函数反复压栈,栈内存很快就溢出了
- 如果是有限次数的递归,可以使用递归调用,或者使用循环代替,循环代码稍微复杂一些,但是只要不是死循环,可以多次迭代直至算出结果
- 绝大多数递归,都可以使用循环实现
- 即使递归代码很简洁,但是能不用则不用递归
高阶函数
一等公民
- 函数在Python是一等公民(First-Class Object)
- 函数也是对象,是可调用对象
- 函数可以作为普通变量,也可以作为函数的参数、返回值
高阶函数
高阶函数(High-order Function)
- 数学概念 y = f(g(x))
- 在数学和计算机科学中,高阶函数应当是至少满足下面一个条件的函数
- 接受一个或多个函数作为参数
- 输出一个函数
练习:自定义sort函数
仿照内建函数sorted,请自行实现一个sort函数(不用使用内建函数),能够为列表元素排序
思考:通过练习,思考sorted函数的实现原理,map、filter函数的实现原理
思路:
- 内建函数sorted函数,它返回一个新的列表,可以设置升序或者降序,可以设置一个用于比较的函数(自定义函数也要实现这些功能)
- 新建一个列表,遍历原列表,和新列表中的当前值依次比较,决定带插入数插入到新列表的什么位置
实现
def sort(iterable, *, key=None, reverse=False): # key指定类型
newlist = []
for x in iterable:
cx = key(x) if key else x # cs 只参与比较,如果有key,则key(x),如果为None,则 x
for i, y in enumerate(newlist):
cy = key(y) if key else y # 同理cx
comp = cx > cy if reverse else cx < cy # 实现reverse参数
if comp:
newlist.insert(i, x)
break #找到了合适的插入位置并插入成功
else: # 不大于,尾部追加
newlist.append(x)
return newlist
12345678910111213
内建高阶函数
排序sorted
- 定义:sorted*iterable, *, key=None, reverse=False) ->list
sorted(lst, key=lambda x: 6 -x) # 返回新列表
list.sort(key=lambda x: 6-x) # 就地修改
12
过滤filter
- 定义:filter(function, iterable)
- 过滤惰性对象,把元素一个个拿来判断是否需要输出,元素只是个数有变化,本身没有变化
- 对可迭代对象进行遍历,返回一个迭代器
- function参数是一个参数的函数,且返回值应当是bool类型,或其返回值等效布尔值。
- function参数如果是None,可迭代对象的每一个元素自身等效布尔值
print(list(filter(lambda x: x%3==0, [1, 9, 55, 150, -2, 3, 123 ]))) # [9, 150, 3, 123]
print(list(filter(None, range(5)))) # [1, 2, 3, 4],None拿元素本身等效,判断是否为True
print(list(filter(None, range(-5, 5)))) # [-5, -4, -3, -2, -1, 1, 2, 3, 4]
123
- 恒定为True

- 恒定为False
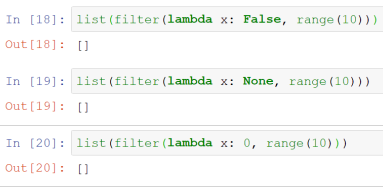
map
- 定义:map(function, *iterables) -> map ibject
- 对多个可迭代对象的元素,按照指定的函数进行映射
- 返回一个迭代器
- map实现字典

- 木桶原理 dict会将[x, y]这个二元结构拆分为kv
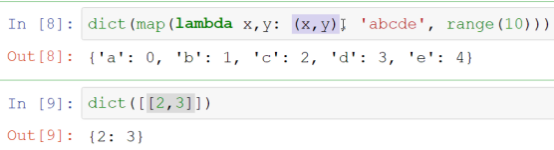
- 如果是传入set,无序的,kv会随机排序

- dict在3.6中按输入顺序排序,{x:1, y:2}相当于吧keys拿出来构造字典

柯里化
- 指的是将原来就接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数为参数的函数
- z = f(x, y) 转换成 z = f(x)(y)的形式
- 例如:
def add(x, y):
return x + y
12
柯里化后:
def add(x):
def _add(y):
return x + y
return _add
1234
通过嵌套函数就可以把函数转换成柯里化函数
- 三层柯里化
def add(x):
def _add(y,z):
return x + y + z
return _add
print(add(4)(5,6)) #15
def add1(x,y):
def _add1(z):
return x + y + z
return _add1
print(add1(4, 5)(6)) #15
def add2(x):
def _add2(y):
def _add3(z):
return x + y + z
return _add3
return _add2
print(add2(4)(5)(6)) #15
装饰器
装饰器(无参)
- 它是一个函数
- 函数作为它的形参。无参装饰器实际上就是一个单形参函数
- 返回值也是一个函数
- 可以使用@functionname方式,简化调用
装饰器和高阶函数
- 装饰器可以是高阶函数,但装饰器是对传入函数的功能的装饰(功能增强)
打印日志装饰器写法
def logger(fn): # fn = (lambada x,y:x+y) # logger 记录
def wrapper(*args,**kwargs): # (4, 5) # wrapper 包装
print('before') # 函数之前功能增强
print("add function:{}|{}".format(args,kwargs))
ret = fn(*args,**kwargs) #(lambda x,y:x+y)(4, 5)
print('after',ret) # 函数之后功能增强
return ret
return wrapper
@logger # add = logger(add)
def add(x,y): # 完成加法功能的函数 add = lambda x,y:x + y
return x + y
add(4,5)
1234567891011121314
- 打印结果
before
add function:(4, 5)|{}
after 9
123
获取函数的执行时长
import datetime
import time
def logger(fn):
def wrapper(*args,**kwargs):
print('begin to work')
start = datetime.datetime.now() # 开始时间
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds() # add代码运行总时长
print('{} took {:.2f}s'.format(fn.__name__,delta)) # 打印时长,{:.2f}保留小数点后两位
return ret
return wrapper
@logger
def add(x,y):
time.sleep(2) # 使函数运行时休眠两秒
return x + y
add(40,50)
123456789101112131415161718
- 打印结果
begin to work
add took 2.00s
12
获取函数时长,对时长超过阀值的函数记录一下
import datetime
import time
def copy_properties(src):
def _copy(dst):
dst.__name__ = src.__name__
dst.__doc__ = src.__doc__
return dst
return _copy
def logger(duration):
def _logger(fn):
@copy_properties(fn) # wrapper = wrapper(fn)(wrapper)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print('so slow') if delta > duration else print('so fast')
return ret
return wrapper
return _logger
@logger(5) # add = logger(5)(add)
def add(x,y):
time.sleep(3)
return x + y
print(add(5,6))
12345678910111213141516171819202122232425262728
- 打印结果
so fast
11
12
文档字符串
Python的文档
- Python文档字符串Documentation Strings
- 在函数语句块的第一行,且习惯是多行的文本,所以多使用三引号
- 惯例是首字母大写,第一行写概述,空一行,第三行写详细描述
- 可以使用特殊属性__doc__访问这个文档
def add(x,y):
"""This is a function of addition"""
return x + y
print("name={}\ndoc={}".format(add.__name__,add.__doc__))
print(help(add))
123456
- 打印结果
name=add
doc=This is a function of addition
Help on function add in module __main__:
add(x, y)
This is a function of addition
None
12345678
还原函数名称与属性
- 通过copy_properties函数将被包装函数的属性覆盖掉包装函数
- 凡是被装饰的函数都需要复制这些属性,这个函数很通用
- 可以将复制属性的函数构建成装饰器函数,带参装饰器
def copy_properties(src): # src = fn
def _copy(dst): # dst = wrapper
dst.__name__ = src.__name__
dst.doc__ = src.__doc__
return dst # 相当于返回的 wrapper
return _copy
def logger(fn):
@copy_properties(fn) # wrapper = copy_properties(fn)(wrapper)
def wrapper(*args,**kwargs):
"""I am wrapper"""
print('begin')
x = fn(*args,**kwargs)
print('end')
return x
return wrapper
@logger
def add(x,y): # add = logger(add)
"""This is a function for add"""
return x + y
print("name={},doc={}".format(add.__name__,add.__doc__))
12345678910111213141516171819202122
- 打印结果,因调用了@copy_properties,所以add的名称和属性还是原来的
name=add,doc=I am wrapper
1
带参装饰器
- 它是一个函数
- 函数作为它的形参
- 返回值是一个不带参的装饰器函数
- 使用@funtionname(参数列表)方式调用
- 可以看做在装饰器外层又加了一层函数,这个函数可以多参数
functools模块
functools.update_wrapper(wrapper,wrapped,assigned=WRAPPER_ASSIGNMENTS,updated=WRAPPER_UPDATES)
- 类似copy_properties功能
- wrapper 包装函数、被更新者,wrapped被包装函数、数据源
- 元祖WRAPPER_ASSIGNMENTS中是要被覆盖的属性
- 模块名__module__,名称__name__,限定名__qualname__,文档__doc__,参数注解__annotations__
- 元祖WRAPPER_UPDATES中要是被更新的属性,__dict__属性字典
- 增加一个__wrapped__属性,保留着wrapped函数
from functools import update_wrapper,wraps
import datetime
import time
import functools
from functools import update_wrapper,wraps
def logger(durantion):
def _logger(fn):
@wraps(fn) # wrapper = upadte_wrapper(fn)(wrapper)
def wrapper(*args,**kwargs):
'''My name is wrapper'''
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print('so slow') if delta > durantion else print('so fast')
return ret
# update_wrapper(wrapper, fn) # 等同上面 @wraps
return wrapper
return _logger
@logger(5)
def add(x,y):
'''This is a function of addition'''
time.sleep(1)
return x + y
print(add.__name__,add.__doc__)
写一个命令分发器
- 程序员可以方便的注册函数到某一个命令,用户输入命令时,路由到注册的函数
- 如果此命令没有对应的注册函数,执行默认函数
- 用户输入用input(">>")
分析
- 输入命令映射到一个函数,并执行这个函数。应该是cmd_tbl[cmd] = fn的形式,字典正好合适
- 如果输入了某一个cmd命令后,没有找到函数,就要调用缺省的函数执行,这正好是字典缺省参数
- cmd是字符串
# 构建全局字典
cmd_table = {}
# 注册函数
def reg(cmd, fn):
cmd_table[cmd] = fn
# 缺省函数
def default_func():
print('Unknown command')
# 分发器,调度
def dispatcher():
while True:
cmd = input(">>")
# 退出条件
if cmd.strip() == '':
return
cmd_table.get(cmd, default_func)() # get,当cmd不存在时,使用缺省值defaul_func
# 自定义函数
def foo1():
print('hello')
def foo2():
print('python')
# 注册
reg('hi', foo1)
reg('py', foo2)
# 循环
dispatcher()
1234567891011121314151617181920212223242526272829303132
- 分析:
- 代码函数的注册不好看
- 所有的函数和字典都在全局中定义,不好
- 改进办法
封装
- 将reg函数封装成装饰器,并用它来注册函数
def command_dispatcher():
# 构建全局字典
cmd_table = {}
# 注册函数
def reg(cmd):
def _reg(fn):
cmd_table[cmd] = fn
return fn
return _reg
# 缺省函数
def default_func():
print('Unknown command')
# 分发器,调度
def dispatcher():
while True:
cmd = input(">>")
# 退出条件
if cmd.strip() == '':
return
cmd_table.get(cmd, default_func)()
# get,当cmd不存在时,使用缺省值defaul_func
return reg,dispatcher # 把两个函数标识符(分别对应函数)封装到元组中
reg, dispatcher = command_dispatcher() # 将两个函数解构
# 自定义函数
@reg('hi')
def foo1():
print('hello')
@reg('py')
def foo2():
print('python')
# 循环
dispatcher()
123456789101112131415161718192021222324252627282930313233343536373839
完善命令分发器
- 完善命令分发器,实现函数可以带任意参数(可变参数除外),解析参数并要求用户输入
- 即解决下面的问题
# 自定义函数
@reg('hi')
def foo1(x,y):
print('hello', x, y)
@reg('py')
def foo2(a,=100):
print('python', a, b)
12345678
思路
- 可以有2中方式
- 注册的时候,固定死,@reg(‘py’,200,100)
可以认为@reg(‘py’,200,100)和@reg(‘py’,300,100)是不同的函数,可以用partial函数 - 运行时,在输入cmd的时候,逗号或空格分割,获取参数
- 一般用户都喜欢使用单纯一个命令如hi,然后直接显示想要的结构,就采用方式一实现
方式一实现
# 自定义函数可以有任意参数,可变参数、keyword-only除外
def command_dispatcher():
# 构建全局字典
cmd_tbl = {}
# 注册函数
def reg(cmd, *args, **kwargs):
def _reg(fn):
cmd_tbl[cmd] = fn, args, kwargs
return fn
return _reg
# 缺省函数
def default_func():
print('Uknown command')
# 调度器
def dispatcher():
while True:
cmd = input('please input cmd>>')
# 退出条件
if cmd.strip() == '':
return
fn, args, kwargs = cmd_tbl.get(cmd, (default_func, (), {}))
# get,当cmd不存在时,使用缺省值(defaul_func, (), {}) ,并将其解构,fn对应default_func...
fn(*args,**kwargs) # 调用cmd[0]或default_func函数
return reg,dispatcher
reg, dispatcher = command_dispatcher()
# 自定义函数
@reg('hi', z=200, y=300, x=100)
@reg('hi1', z=300, y=300, x=300)
@reg('hi2', 1, 2, 3)
def foo1(x, y, z):
print('hello',x, y, z)
@reg('py', 300, b=400)
def foo2(a, b=100):
print('python', a, b)
# 调度循环
dispatcher()
```python
## 方法二实现
12345678910111213141516171819202122232425262728293031323334353637383940414243444546
自定义函数可以有任意参数,可变参数、keyword-only除外
def command_dispatcher():
# 构建全局字典
commands = {}
# 注册函数
def reg(cmd):
def _reg(fn):
commands[cmd] = fn
return fn
return _reg
# 缺省函数
def default_fn(*args,**kwargs):
print('Uknown command')
# 调度器
def dispatcher():
while True:
cmd = input('>>')
# 退出条件
if cmd.strip() == '':
break
else:
fname, *params = cmd.replace(',', ' ').split() #list
#print(params) # ['1', 'y=5']
args = []
kwargs = {}
for param in params:
x = param.split('=', maxsplit=1) # 按'='切,最大切一刀
if len(x) == 1: # 顺序传参
args.append(int(x[0]))
elif len(x) == 2: # a=1 [a,1]
kwargs[x[0]] = int(x[1])
#print(args, kwargs)
commands.get(fname, default_fn)(*args, **kwargs)
return reg, dispatcher
reg, dispatcher = command_dispatcher()
# 自定义函数
@reg('hi')
def foo1(x, y):
print('hello', x, y, x+y)
@reg('py')
def foo2(a, b=100):
print('python', a, b, a+b)
# 调度循环
dispatcher()
# >> py 200 300
# >> py 200
# >> py 200,y=200
数据类型的选择
- 缓存的应用场景,是有数据需要频繁查询,且每次查询都需要大量计算或者等待时间之后才能返回结果的情况,使用缓存来提高查询速度,用内存空间换取查询、加载的时间
cache应该选用什么数据结构?
- 便于查询的,且能快速获得数据的数据结构
- 每次查询的时候,只需要输入一致,就应该得到同样的结果(顺序也一致,例如减法函数,参数顺序不一致,结果不一样)
- 基于上面的分析,此数据结构应该是字典
- 通过一个key,对应一个value
- key是参数列表组成的结构,value是函数返回值。难点在于key如何处理
key的存储
- key必须是hashable
- key能接受到位置参数和关键字参数传参
- 位置参数是被收集在一个tuple中的,本身就有顺序
- 关键字参数被收集在一个字典中,本身无序,这会带来一个问题,传参的顺序未必是字典中保存的顺序。
OrderedDict,它可以记录顺序。
不用OrderedDict,用一个tuple保存排过序的字典的item的kv对。
key要求
- key必须是hashable
- 由于key是所有实参组合而成,而且最好要作为key的,key一定要可以hash,但是如果key有不可hash类型数据,就无法完成,因为lru_cache就不可以
def add1(x,y):
return y
>>>add1([],5)
5
@functools.lru_cache()
def add(x,y=5):
time.sleep(3)
return y
>>>add(4)
5
>>>add([],5)
------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-46-a6b43c6e78a2> in <module>()
----> 1 add([],5)
TypeError: unhashable type: 'list'
123456789101112131415161718192021
- 缓存必须使用key,但是key必须可hash,所以只能使用可hash的实参的函数调用
key算法设计
- inspect模块获取函数签名后,取parameters,这是一个有序字典,会保存所有参数的信息。
- 构建一个字典params_dict,按照位置顺序从args中依次对应参数名和传入的实参,组成kv对,存入params_dict中。
- kwargs所有值update到params_dict中。
- 如果使用了缺省值的参数,不会出现在实参params_dict中,会出现在签名的parameters中,缺省值也在函数定义中。
调用的方式
- 普通的函数调用可以,但是过于明显,最好类似lru_cache的方式,让调用者无察觉的使用缓存。
构建装饰器函数。
代码模板如下:
from functools import wraps
import inspect
def py_cache(fn):
local_cache = {} # 对不同函数名是不同的cache
@wraps(fn)
def wrapper(*args, **kwargs): # 接收各种参数
# 参数处理,构建key
ret = fn(*args, **kwargs)
return ret
return wrapper
@py_cache
def add(x,y,z=6):
return x + y + z
12345678910111213
目标
def add(x, y, z=6):
return x + y + z
add(4, 5)
add(4, 5, 6)
add(4, z=6, y=5)
add(4, y=6, z=6)
add(x=4, y=5, z=6)
add(z=6, x=4, y=5)
123456789
上面几种都等价,也就是key一样,这样都可以缓存。
代码实现
- 完成了key的生成:本次使用了普通的字典params_dict,先把位置参数的对应好,再填充关键字参数,最后补充缺省值,然后再排序生成key。
from functools import wraps
import inspect
def py_cache(fn):
local_cache = {} # 对不同函数名是不同的cache
@wraps(fn)
def wrapper(*args, **kwargs):
# 参数处理, 构建key
sig = inspect.signature(fn)
params = sig.parameters # 只读有序字典
param_names = [key for key in params.keys()] # list(params.keys())
param_dict = {} # 目标参数字典
# 有序字典
# for i, v in enumerate(args):
# k = param_names[i]
# param_dict[k] = v
param_dict.update(zip(params.keys(), args))
# 关键字参数
# for k, v in kwargs.items():
# param_dict[k] = v
param_dict.update(kwargs)
# 缺省值处理
for k in (params.keys() - param_dict.keys()):
param_dict[k] = params[k].default
# for k, v in params.items():
# if k not in param_dict.keys():
# param_dict[k] = v.default
key = tuple(sorted(param_dict.items()))
# 判断是否需要缓存
if key not in local_cache.keys():
local_cache[key] = fn(*args, **kwargs)
return key, local_cache[key]
return wrapper
import time
@py_cache
def add(x, y, z=6):
time.sleep(2)
return x + y +z
result = []
result.append(add(4, 5))
result.append(add(4, 5, 6))
result.append(add(4, z=6, y=5))
result.append(add(4, y=5, z=6))
result.append(add(x=4, y=5, z=6))
result.append(add(z=6, x=4, y=5))
for x in result:
print(x)
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758
- 增加logger装饰器查看执行时间
from functools import wraps
import datetime
def logger(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
start = datetime.datetime.now()
ret = fn(*args, **kwargs)
delta =(datetime.datetime.now() - start).total_seconds()
print(fn.__name__, delta)
return ret
return wrapper
@logger
@py_cache
def add(x, z, y=6):
time.sleep(3)
return x + y + z
123456789101112131415161718
过期功能
- 一般缓存系统都有过期功能。
- 它是某一个key过期。可以对每一个key单独设置过期时间,也可以对这些key统一设定过期时间
- 本次的实现简单点,统一设定key的过期时间,当key生存超过了这个时间,就自动被清除
- 注意:这里并没有考虑多线程等问题。而且这种过期机制,每一次都要遍历所有数据,大量数据的时候,遍历可能有效率问题
- 在上面的装饰器中增加一个参数,需要用到了带参装饰器了
- @py_cache(5) 代表key生存5秒钟后过期
- 带参装饰等于在原来的装饰器外面在嵌套一层
清除的时机
- 何时清除过期key?
1、用到某个key之前,先判断是否过期,如果过期重新调用函数生成新的key对应value值。
2、一个线程负责清除过期的key.本次在创建key之前,清除所有过期的key。 - value的设计
1、key => (v, createtimestamp)
适合key过期时间都是统一的设定。
2、key => (v, createtimestamp, duration)
duration是过期时间,这样每一个key就可以单独控制过期时间。在这种设计中,-1可以表示永不过期,0可以表示
立即过期,正整数表示持续一段时间过期。
本次采用第一种实现。
#简化设计,函数的形参定义不包括可变位置参数,可变关键字参数和keyword-only参数
#可以不考虑缓存大小,也不用考虑存满了之后的换出问题
from functools import wraps
import inspect
import datetime
import time
def logger(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
start = datetime.datetime.now()
ret = fn(*args, **kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print(fn.__name__, delta)
return ret
return wrapper
def py_cache(duration):
def _cache(fn):
local_cache = {} # 对不同函数名是不同的cache
@wraps(fn)
def wrapper(*args, **kwargs):
def clear_expire(cache):
# 使用缓存时才清楚过期的key
expire_keys = []
for k ,(_, stamp) in cache.items():
now = datetime.datetime.now().timestamp()
if now - stamp > duration:
expire_keys.append(k)
for k in expire_keys:
cache.pop(k)
clear_expire(local_cache)
def make_key():
# 参数处理,构建key
sig = inspect.signature(fn)
params = sig.parameters # 只读有序字典
param_names = [key for key in params.keys()] # list(params.keys())
param_dict = {} # 目标参数字典
# 有序参数
# for i, v in enumerate(args):
# k = param_names[i]
# param_dict[k] = v
param_dict.update(zip(params.keys(), args))
# 关键字参数
# for k, v in kwargs.items():
# param_dict[k] = v
param_dict.update(kwargs)
# 缺省值处理
for k in (params.keys() - param_dict.keys()):
param_dict[k] = params[k].default
# for k, v in params.items():
# if k not in param_dict.keys():
# param_dict[k] = v.default
return tuple(sorted(param_dict.items()))
key = make_key()
# 待补充, 增加判断是否需要缓存
if key not in local_cache.keys():
local_cache[key] = (fn(*args, **kwargs))
datetime.datetime.now().timestamp() # 时间戳
return key, local_cache[key]
return wrapper
return _cache
@logger
@py_cache(10)
def add(x, z, y=6):
time.sleep(3)
return x,y
result = []
result.append(add(4, 5))
result.append(add(4, 5, 6))
result.append(add(4, z=6, y=5))
result.append(add(4, y=5, z=6))
result.append(add(x=4, y=5, z=6))
result.append(add(z=6, x=4, y=5))
for x in result:
print(x)
time.sleep(10)
result = []
result.append(add(4, 5))
result.append(add(4, z=5))
result.append(add(4, y=6, z=5))
result.append(add(4, 6))
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596
- 如果要使用OrderedDict,要注意,顺序要以签名声明的顺序为准
def make_key():
# 参数处理,构建key
sig = inspect.signature(fn)
params = sig.parameters # 只读有序字典
params_dict = OrderedDict() # {}
params_dict.update(zip(params.keys(), args))
# 缺省值和关键字参数处理
# 如果在params_dict中,说明是位置参数
# 如果不在params_dict中,如果在kwargs中,使用kwargs的值,如果也不在kwargs中,就使用缺省值
for k,v in params.items(): # 顺序由前面的顺序定
if k not in params_dict.keys():
if k in kwargs.keys():
params_dict[k] = kwargs[k]
else:
params_dict[k] = v.default
return tuple(params_dict.items())
12345678910111213141516171819
装饰器的用途
- 装饰器是AOP面向切面编程 Aspect Oriented Programming的思想的体现。
- 面向对象往往需要通过继承或者组合依赖等方式调用一些功能,这些功能的代码往往可能在多个类中出现,例如
- logger功能代码。这样造成代码的重复,增加了耦合。logger的改变影响所有使用它的类或方法。
- 而AOP在需要的类或方法上切下,前后的切入点可以加入增强的功能。让调用者和被调用者解耦。
- 这是一种不修改原来的业务代码,给程序动态添加功能的技术。例如logger函数就是对业务函数增加日志的功能,
- 而业务函数中应该把与业务无关的日志功能剥离干净。
装饰器应用场景
- 日志、监控、权限、审计、参数检查、路由等处理。
- 这些功能与业务功能无关,是很多业务都需要的公有的功能,所以适合独立出来,需要的时候,对目标对象进行增强。
函数定义的弊端
- Python是动态语言 ,变量随时可以被赋值,且能赋值为不同的类型
- Python不是静态编译语言,变量类型是在运行期决定的
- 动态语言很灵活,但是这种特性也是弊端
函数注解
- Python 3.5 引入
- 对函数的参数进行类型注解
- 对函数的返回值进行类型注解
- 只对函数参数做一个辅助的说明,并不对函数参数进行类型检查
- 提供给第三方工具,做代码分析,发现隐藏的bug
- 函数注解的信息,保存在__annotations__属性中
def add(x:int , y:int) -> int:
'''
:param x:
:param y:
:return:
'''
return x + y
print(help(add))
print(add.__annotations__)
123456789
打印结果
add(x:int, y:int) -> int
:param x:
:param y:
:return:
None
{'x': <class 'int'>, 'y': <class 'int'>, 'return': <class 'int'>}
1234567
变量注解
- Python 3.6引入。它也只是一种对变量的说明,非强制
- i:int = 3
函数参数类型检查
思路
- 函数参数的检查,一定是在函数外,如果把检查代码侵入到函数中
- 函数应该作为参数,传入到检查函数中
- 检查函数拿到函数传入的实际参数,与形参声明对比
- __annotations__属性是一个字典,其中包括返回值类型的声明。假设要做位置参数的判断,无法和字典中的声明对应。使用inspect模块
inspect模块
- 提供获取对象信息的函数,可以检查函数的类、类型检查
- signature(callable),获取前面(函数签名包括了一个函数的信息,包括函数、它的参数类型、它所在的类和名称空间及其他信息)
import inspect
def add(x:int, y:int, *args, **kwargs) -> int:
return x + y
sig = inspect.signature(add)
print(sig,type(sig)) # 函数签名
print('params:',sig.parameters) #OrderedDict
print('return:',sig.return_annotation)
print(sig.parameters['y'],type(sig.parameters['y']))
print(sig.parameters['x'].annotation)
print(sig.parameters['args'])
print(sig.parameters['args'].annotation)
print(sig.parameters['kwargs'])
print(sig.parameters['kwargs'].annotation)
1234567891011121314
打印结果
(x:int, y:int, *args, **kwargs) -> int <class 'inspect.Signature'>
params: OrderedDict([('x', <Parameter "x:int">), ('y', <Parameter "y:int">), ('args', <Parameter "*args">), ('kwargs', <Parameter "**kwargs">)])
return: <class 'int'>
y:int <class 'inspect.Parameter'>
<class 'int'>
*args
<class 'inspect._empty'>
**kwargs
<class 'inspect._empty'>
123456789
inspect用法
- inspect.isfunction(add),是否是函数
- inspect.ismethod(add),是否是类的方法
- inspect.isgenerator(add),是否是生成器对象
- inspect.isgeneratorfunction(add),是否是生成器函数
- inspect.isclass(add),是否是类
- inspect.ismodule(inspect),是否是模块
- inspect.isbuiltin(print),是否是内建对象
- 还有很多is函数,可通过inspect模块帮助查阅
Parameter对象
- 保存在元组中,是只读的
- name,参数的名字
- annotation,参数的注解,可能没有定义
- default,参数的缺省值,可能没有定义
- empty,特殊的类,用来标记default属性或者注释annotation属性的空值
- kind,实参如何绑定到形参,就是形参的类型
- POSITIONAL_ONLY,值必须是位置参数提供
- POSITIONAL_OR_KEYWORD,值必须作为关键字或者位置参数提供
- VAR_POSITIONAL,可变位置参数,对应*args
- KEYWORD_ONLY,keyword-only参数,对应或者args之后的出现的非可变关键字参数
- VAR_KEYWORD,可变关键字参数,对应**kwargs
例:
import inspect
def add(x, y:int=7, *rangs, z, t=10, **kwargs) ->int:
return x + y
sig = inspect.signature(add)
print(sig)
print('params:', sig.parameters)# 有序字典
print('return:', sig.return_annotation)
print('~~~~~~~~~~~~~~~~~~~')
for i ,item in enumerate(sig.parameters.items()):
name, param = item
print(i+1, name, param.annotation, param.kind, param.default)
print(param.default is param.empty, end='\n\n')
12345678910111213
打印结果:
(x, y:int=7, *rangs, z, t=10, **kwargs) -> int
params: OrderedDict([('x', <Parameter "x">), ('y', <Parameter "y:int=7">), ('rangs', <Parameter "*rangs">), ('z', <Parameter "z">), ('t', <Parameter "t=10">), ('kwargs', <Parameter "**kwargs">)])
return: <class 'int'>
~~~~~~~~~~~~~~~~~~~
1 x <class 'inspect._empty'> POSITIONAL_OR_KEYWORD <class 'inspect._empty'>
True
2 y <class 'int'> POSITIONAL_OR_KEYWORD 7
False
3 rangs <class 'inspect._empty'> VAR_POSITIONAL <class 'inspect._empty'>
True
4 z <class 'inspect._empty'> KEYWORD_ONLY <class 'inspect._empty'>
True
5 t <class 'inspect._empty'> KEYWORD_ONLY 10
False
6 kwargs <class 'inspect._empty'> VAR_KEYWORD <class 'inspect._empty'>
True
123456789101112131415161718192021
业务应用
- 有函数如下
def add(x, y:int=7) -> int:
return x + y
12
- 检查用户输入是否符合参数注解的要求
思路
- 调用时,判断用户输入的实参是否符合要求
- 调用时,用户感觉上还是在调用add函数
- 对用户输入的数据和声明的类型进行对比,如果不符合,提示用户
import inspect
def check(fn):
def wrapper(*args,**kwargs):
sig = inspect.signature(fn)
params = sig.parameters
values = list(params.values())
for i,p in enumerate(args):
param = values[i]
if param.annotation is not param.empty and not isinstance(p, param.annotation):
print(p,'!= =',values[i].annotation)
for k,v in kwargs.items():
if params[k].annotation is not inspect._empty and not isinstance(v, params[k].annotation):
print(k,v,'! = = =',params[k].annotation)
return fn(*args, **kwargs)
return wrapper
@check
def add(x, y:int=7) -> int:
return x + y
print(add(20,0)) # 20
functools模块
reduce方法
- reduce方法,顾名思义就是减少
- ruduce(function, sequence,[, initial]) -> value
- 可迭代对象不能为空;初始值没提供就在可迭代对象中取一个元素
reduce方法举例
from functools import reduce
nums = [6, 5, 8, 5, 10, 6, 9, 4]
print(sum(nums)) # 53
print(reduce(lambda val, x: val + x,nums)) # 53
12345
partial方法
- 偏函数,把函数部分的参数固定下来,相当于为部分的参数添加了一个固定的默认值,形成一个新的函数并返回
- 从partial生成的新函数,是对原函数的封装
partial方法举例1
import functools
import inspect
def add(x,y) -> int:
return x + y
newadd = functools.partial(add, y=5)
print(newadd(7)) # 12
print(newadd(7,y=6)) # 13
print(newadd(y=9, x =5)) # 14
print(inspect.signature(newadd)) # (x, *, y=5) -> int 获取函数签名
1234567891011
partial方法举例2
import functools
import inspect
def add(x, y, *args) -> int:
# print(args) # 返回值为元组 (6, 5, 7) ;(6, 5, 7, 10);(6, 5)
return x + y
newadd = functools.partial(add, 1,3,6,5)
print(newadd(7)) # 4
print(newadd(7, 10)) # 4
print(newadd(9, 10, y=20,x=26)) # 错误传参
print(newadd()) #4
print(inspect.signature(newadd)) # (*args) -> int
12345678910111213
partial函数本质
def parial(func, *args, **keywords):
def newfunc(*fargs, **fkeywords): # 包装函数
newkeywords = keywords.copy()
newkeywords.update(fkeywords)
return func(*(args + fargs), **newkeywords)
newfunc.func = func # 保留原函数
newfunc.args = args # 保留原函数的位置参数
newfunc.keywords = keywords #保留原函数的关键字参数
return newfunc
def add(x,y):
return x + y
foo = parial(add,4)
print(foo(5)) # 9
123456789101112131415
lre_cache方法
- @functools.lru_cache(maxsize=128,typed=False)
- Least-recently-used装饰器。lru,最近最少使用。cache缓存
- 如果maxsize设置为None,则禁用LRU功能,并且缓存可以无限制增长。当maxsize是二的幂时,LRU功能执行得最好
- 如果typed设置为True,则不同类型的函数参数将单独缓存。例如,f(3)和f(3.0)将被视为具有不同结果的不同调用
举例
import functools
import time
@functools.lru_cache()
def add(x,y,z=3):
time.sleep(z) # 停止z秒
return x + y
print(add(4, 5))
print(add(4.0, 5))
print(add(4, 6 ))
print(add(4, 6, 3))
print(add(4, y=6))
print(add(x=4, y=6))
print(add(y=6, x=4))
123456789101112131415
lru_cache装饰器
- 通过一个字典缓存被装饰函数的调用和返回值
- 斐波那契数列递归方法的改造
import functools
@functools.lru_cache() # maxsize=None
def fib(n):
return 1 if n<3 else fib(n-1) + fib(n-2)
print([fib(i+1) for i in range(5)]) # [1, 1, 2, 3, 5]
1234567
lru_cache装饰器应用
- 使用提前
同样的函数参数一定得到同样的结果
函数执行时间很长,且要多次执行 - 本质是函数调用的参数 => 返回值
- 缺点
不支持缓存过期,key无法过期、失效
不支持清除操作
不支持分布式,是一个单机的缓存 - 适用场景,单机上需要空间换时间的地方,可以用缓存来将计算变成快速的查询














 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









