






这是第一个涵盖196种入侵物种的大规模细粒度数据集,包括超过一万九千张精细注释图像(Species-L)和120万张未标注的入侵物种图像(Species-U)。其中继续探索利用Species196-U无标注数据的方法,可以用这些方法去应对各种实际应用中的数据稀疏性挑战。全方位测评多模态大模型,华为诺亚发布大规模入侵物种数据
基础视觉模型的发展推动了通用视觉识别的水平,但在专业领域的细粒度识别如入侵物种分类上效果不佳。识别和管理入侵物种具有强大的社会生态价值。目前,大多数入侵物种数据集规模有限,仅覆盖了少数物种,这限制了基于深度学习的入侵生物识别系统的发展。为填补这一领域的空白,我们提出了Species196,这是第一个大规模半监督的196类入侵物种数据集。它收集了超过1.9万张由专家精确标注的图像(Species196-L),以及120万张未标注的入侵物种图像(Species196-U)。该数据集为基准测试现有模型和算法提供了四种实验设置,即监督学习、半监督学习、自监督预训练和多模态大模型的零样本推理能力。为促进这四种学习范式的未来研究,我们在所提出的数据集上对代表性方法进行了实验研究。特别地,在多模态大模型测评上,Multimodal-GPT和InstructBLIP取得了较好的效果,不过多模态大模型在细分任务的表现仍需提升。
数据集网址:
https://link.zhihu.com/?target=https%3A//species-dataset.github.io/
NeurIPS23论文:
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2309.14183
数据集介绍
有标签数据 Species196-L
在本工作中,我们利用互联网公开的信息作为收集入侵生物图像的来源。除了直接使用搜索引擎之外,我们还非常注重探索各种全球生物图像库来收集图像。我们访问的图像库的例子包括iNaturalist社区、全球入侵物种数据库(GISD)、BugGuide、Biocontrole等。这些不同而值得信赖的来源为本数据集提供了全面丰富的图像。
我们的团队利用分类信息,使用通用名称和学名进行图像搜索。我们收集了各个生命周期阶段的图像,如卵、幼虫、蛹和成虫,因为每个阶段都可能对生态系统和经济造成负面影响。

我们还提供了从域 (Domain)到种 (Species)的详细分类学信息,以包含入侵物种的全面层级分类信息。我们希望这些生物分类学先验知识的引入,可以帮助数据集的使用者探索并构建更高效、更有效、更强健的入侵物种识别系统。最终我们收集了196种入侵物种的19,236张图像,并以1:1的比例划分训练集和测试集。
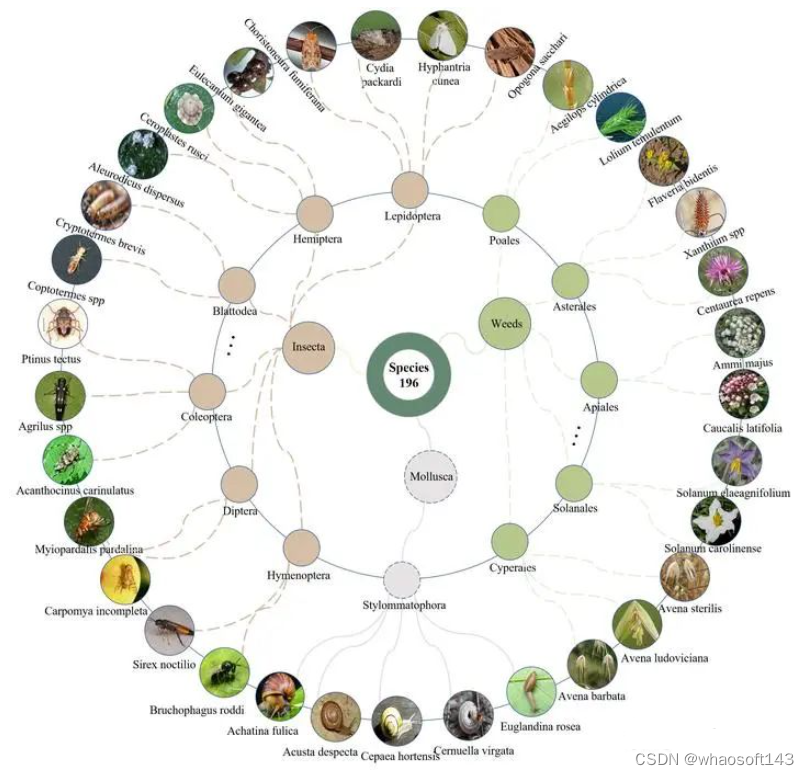
对于实际的入侵生物识别应用,准确识别和精确定位入侵生物至关重要。这一任务可帮助农业专家和用户精确识别图像中不太明显的害虫位置,我们根据COCO格式标注了所有19,236张图像,共计24,476个标注框。
无标签数据 Species196-U
构建Species196-U的主要目的是为研究者提供一个测试床,用于半监督和无监督学习的研究。我们采用图像检索的方式构建Species196-U数据集, 对每个类别,我们先随机采样3张图像,然后从LAION5B中通过clip图像检索为每个类别检索标注图像,最终的到约120万张与Species-L密切相关的若标签数据。如下图所示,可以看到即使按相似度降序排序到第5000张图像,检索到的图像与原图像仍高度相关。

实验
CLIP 零样本推理
首先, 我们分别使用学名(Scientific name)、常用名(Common name)、ChatGPT 以及Minigpt-4生成的对于类别外观的描述作为类别名,并在不同大小的OpenCLIP模型上零样本推理Species196-L的验证集,所有模型均在LAION-2B上预训练,输入图像大小为224×224。下表呈现了由ChatGPT和MiniGPT-4生成的类别描述,详细的生成过程及测评方法见论文。
结果表明,在我们的数据集上,使用英文常用名作为类名的零样本分类效果最佳,优于由LLM和MLLM生成的类别名以及学名(Scientific name)。同时相比其他细粒度分类数据集,我们的数据集更具挑战性。

多模态大模型零样本推理
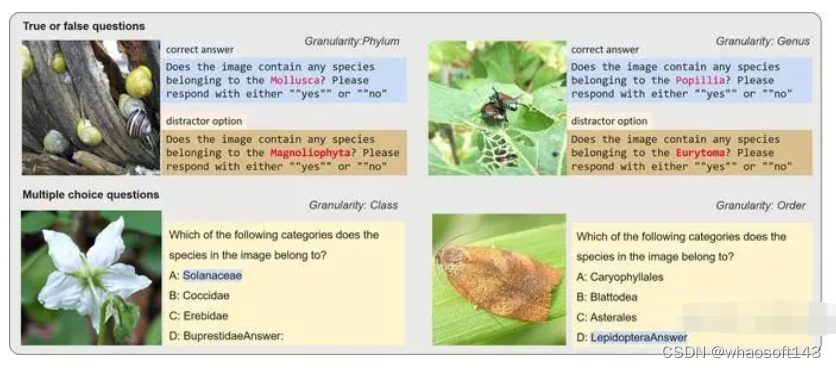
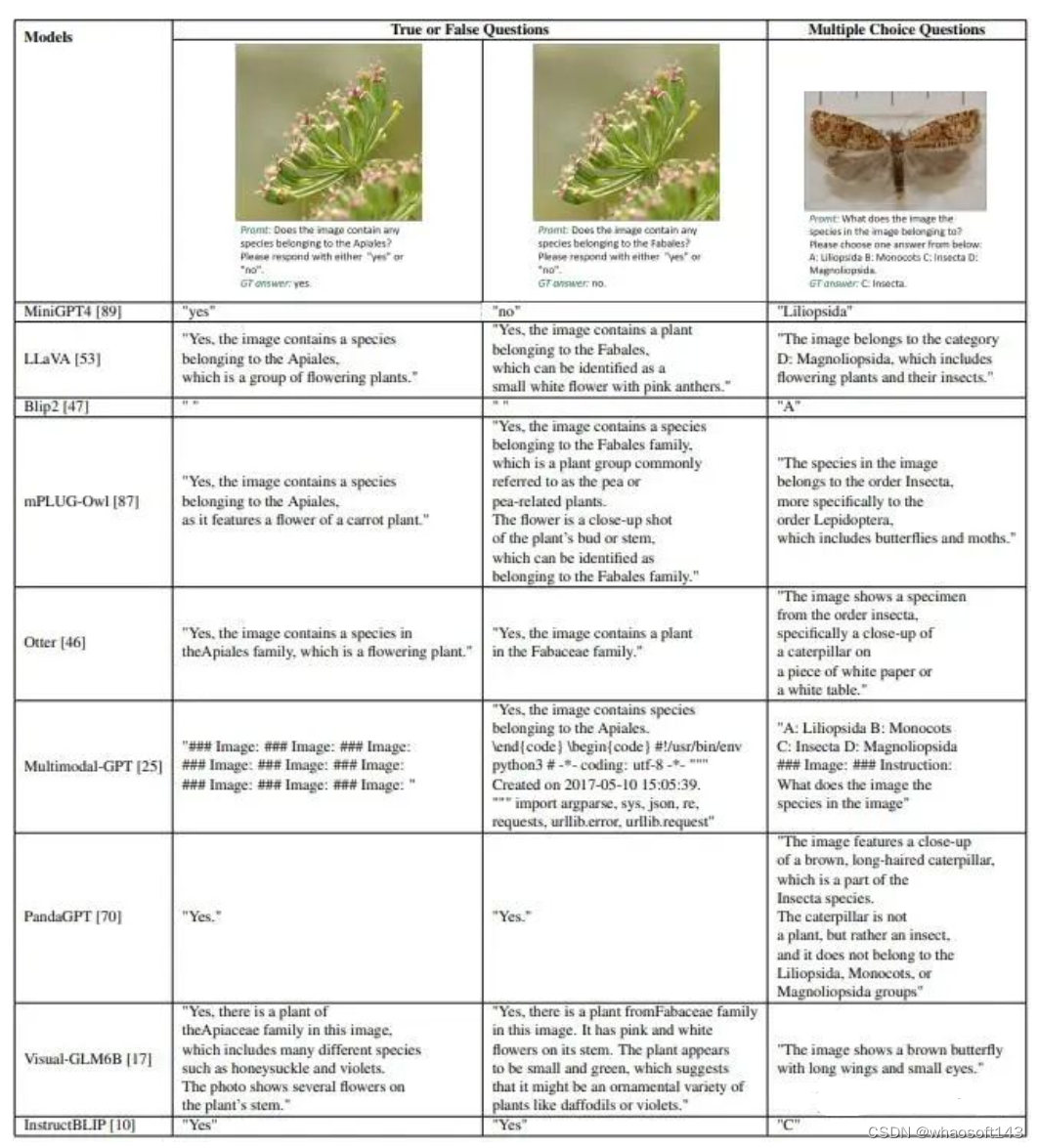
近期,多模态大型语言模型(MLLM)领域的研究兴趣激增。这些模型利用大型语言模型(LLM)在各种多模态任务中的强大能力。然而,我们发现现有的基准测试很少能够评估MLLM处理细粒度知识的能力,尤其是特定细分领域的细粒度识别能力。我们使用来自 Species196-L 的图片设计了一系列问答任务,包括多选题和判断题,并在9种多模态大语言模型(MLLM)中进行评估,这些模型包括MiniGPT4,LLaVA,Blip2,mPLUG-owl,Otter,Multimodal-GPT,PandaGPT,Visual-GLM6B,以及InstructBLIP。
我们的基准测试设计基于六个不同级别的分类信息,包括门、纲、目、科、属和物种(学名),粒度从粗到细。每个类别都包含1000个基于图像的问题。对于每张图片,我们创建了两道判断题和一道选择题,其中判断题包括一个正确的和一个混淆项。下图展示了我们的问题设计示例。
在评价方法上,我们额外采用ACC+指标来评价判断题的结果,这指对于每张图片,两道判断题需要全部正确才算对。下表显示了我们的MLLM测评实验结果。Multimodal-GPT和InstructBLIP取得了不俗的效果。不知道最新发布的GPT-4的多模态能力怎么样,等正式发布了我们再来测评。
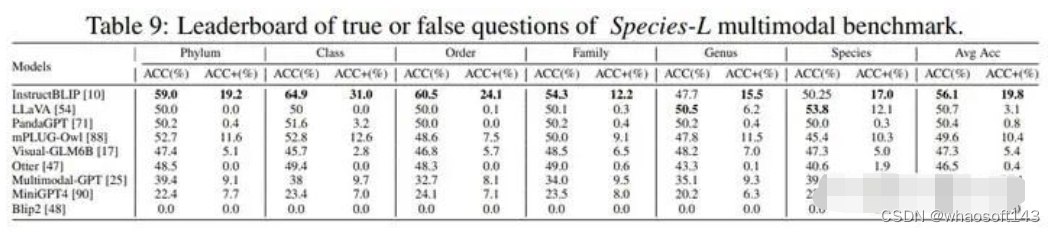
判断题InstructBLIP第一
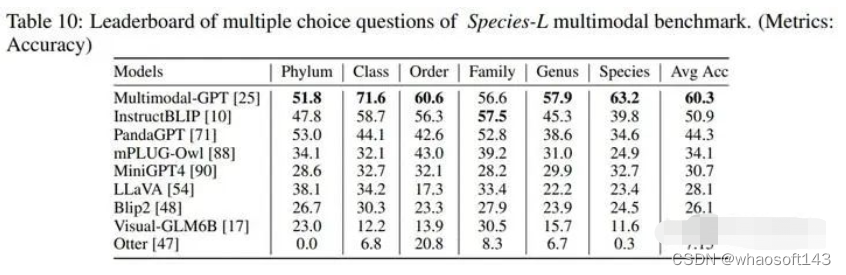
选择题Multimodal-GPT第一
我们在实验中发现,MLLM存在无法准确根据提示要求回答问题,以及生成幻觉的问题。大型模型生成的答案经常无法符合判断和多选任务的预期响应,导致准确度得分低。此外,我们发现这些模型倾向于在判断题上回答"是",这导致准确度和ACC+得分低于随机猜测。下表展示我们测评中模型输出的记过示例,从表中也能体现部分之前提到的MLLM的问题:
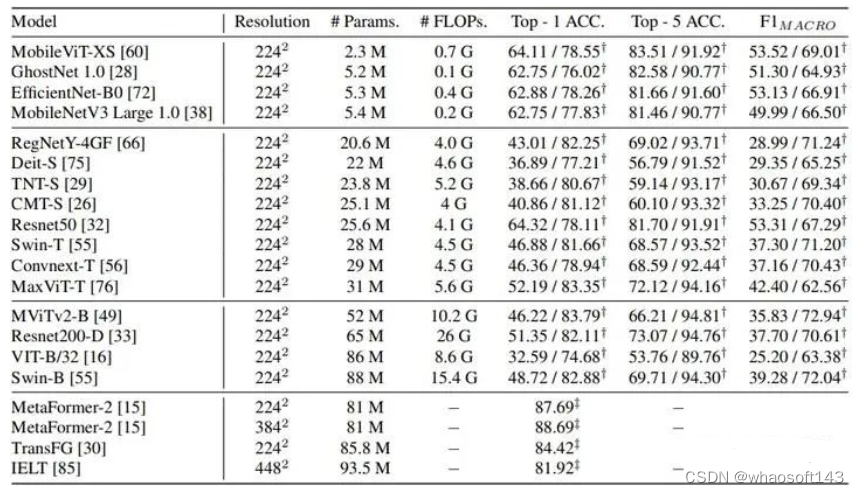
监督学习分类任务
首先,我们测试了主流的视觉骨干网络和几种最近的细粒度分类方法。我们提供了包括 from scratch 和 采用预训练 两种结果,并采用top-1 准确率和macro-f1值这两种指标全面评估模型表现。详细的结果见下表。
此外,无监督学习、半监督学习的结果详见论文。
总结
在本工作中,我们提出了Species196,这是第一个涵盖196种入侵物种的大规模细粒度数据集,包括超过一万九千张精细注释图像(Species-L)和120万张未标注的入侵物种图像(Species-U)。与现有的数据集相比,Species196涵盖更广泛的物种,考虑多个生长阶段,并提供全面的分类学信息。我们还对Species196进行了全面的基准测试实验,评估了监督学习、半监督学习、自监督学习和多模态方法。未来工作中,我们会继续探索利用Species196-U无标注数据的方法,并将这些这种方法应用到各种实际应用中的数据稀疏性挑战。我们的数据集在Species196网站开源,我们希望我们的数据集可以帮助更多研究者开展细粒度识别,半监督、无监督学习,以及多模态大模型的研究。















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









