







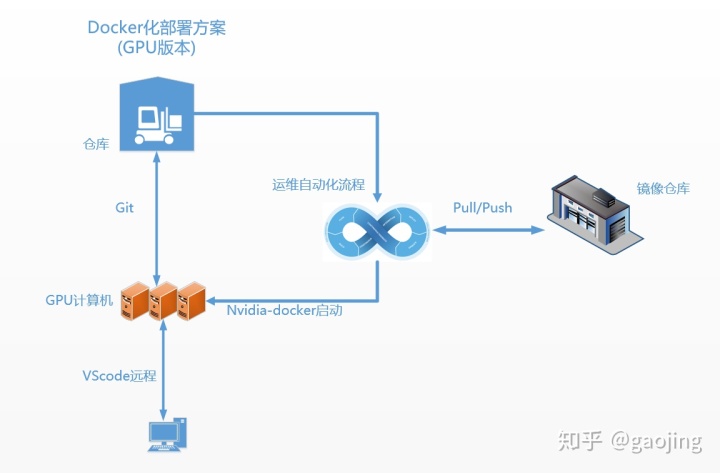
Docker化部署(GPU版本)
一般DL/ML模型需要使用到GPU资源,如何采用一般docker化部署无法部署深度学习模型和机器学习模型,如何使Docker能够使用到宿主机上GPU资源了,Nvidia 提供Nvidia-docker 如何使容器可以访问到宿主机上GPU资源
Nvidia-docker
docker原生并不支持在他生成的容7器中使用Nvidia GP资源。nvidia-docker是对docker的封装,提供一些必要的组件可以很方便的在容器中用GPU资源执行代码。从下面的图中可以很容器看到nvidia-docker共享了宿主机的CUDA Driver。
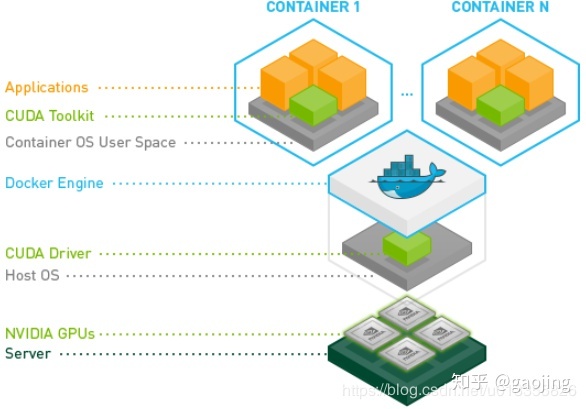
Cuda版本可以不随着宿主机cuda版本而改变
这样有一个好处,不同cuda版本与tf版本匹配就不会受到宿主cuda版本影响了
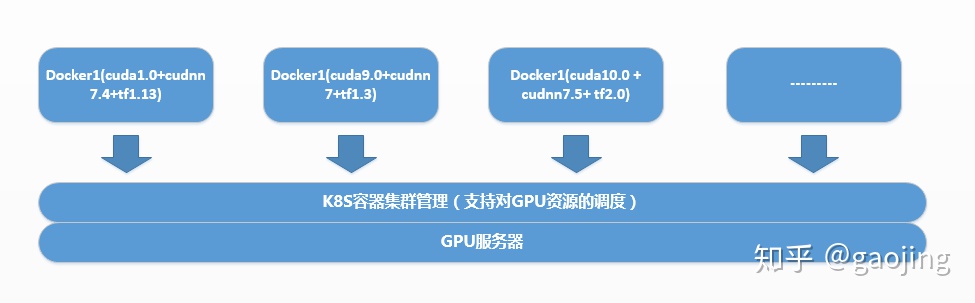
智能算法Docker化部署实践
智能算法是使用BERT优化的文本匹配算法,在API server集成时候做加速,但是如果不适用GPU资源,直接docker化 预测速度较慢,现在采用nvida-docker可以读取GPU资源 方式来
第一步:Dockerhub拉nvidia-cuda基础镜像
选择相应nvidia-cuda版本作为基础镜像

第二步:制作镜像 Dockerfile文件
文本匹配算法Dockerfile文件(这个非常重要)
FROM nvidia/cuda:10.0-cudnn7-runtime-ubuntu18.04
MAINTAINER gaojing
RUN apt update
RUN apt install -y python3-pip
RUN pip3 install --upgrade pip
ADD textmatch /root/textmatch
RUN pip install -r /root/textmatch/requirements.txt
ARG workdir=/root/textmatch
WORKDIR ${workdir}
#CMD ["python","/root/textmatch/text_macth_algor_service.py"]
ENTRYPOINT ["python3", "text_macth_algor_service.py"]
## shell脚本
##执行docker镜像生成命令
docker build -t 名字 dockerfile路径
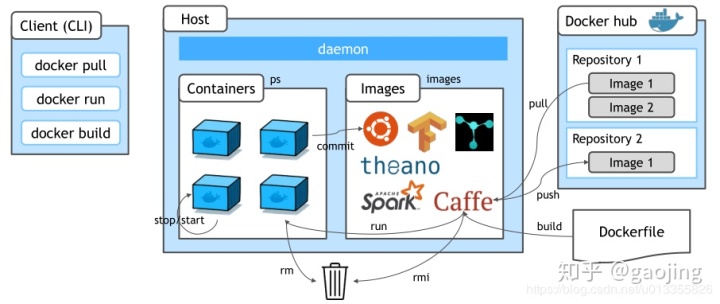
docker build -t name .如下所示,docker镜像容器流程
第三步:执行nvida-docker 命令或者docker run —runtime=nvidia 命令
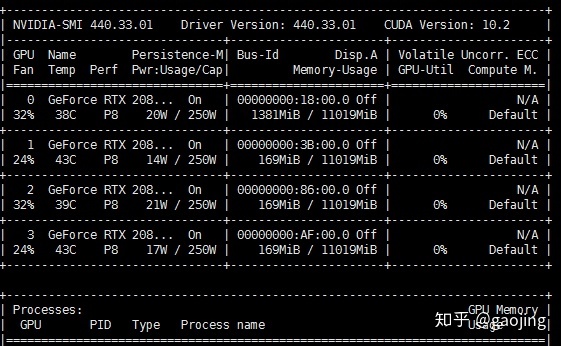
测试是否读取到宿主机上GPU
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
或者
sudo docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi出现下面显卡信息表上docker容器可以读取宿主机上显卡资源
第四步:端口映射与挂载
##docker端口映射与挂载
docker run -d -p 0.0.0.0:9890:9890 -v /home/gaojing/Chatbot_data_models_path/models:/root/textmatch/models chatbot:test02 /bin/bash
##docker gpu端口映射与挂载
nvida-docker run -d -p 0.0.0.0:9890:9890 -v /home/gaojing/Chatbot_data_models_path/models:/root/textmatch/models chatbot:test02 /bin/bash部署整体流程
Docker cache 机制注意事项
采用用户可以使用参数 --no-cache 确保获取最新的外部依赖获取最新的更新特别是在 apt-get update 时候需要重新获取新信息,所以不需要采用cache机制
docker build --no-cache -t registry.uih/library/docker-nvidia-gpu-ubuntu18.04-base:v1.1 .
unable to configure the Docker daemon with file /etc/docker/daemon.json: the following directives are specified both as a flag and in the configuration file: insecure-registries: (from flag: [http://registry.uih], from file: [registry.kubeops.io:8096 registry.apps.feature.mydomain.com registry.uih])
##为什么在daemon.json里面配置这些就有问题了 网上说主要是文本格式问题“”
"insecure-registries":["registry.kubeops.io:8096","registry.apps.feature.mydomain.com"]
##最好执行两行代码
sudo systemctl daemon-reload
sudo systemctl restart dockerNvidia-docker 报错
docker: Error response from daemon: Unknown runtime specified nvidia. See 'docker run --help'.
这是daemon.json文件中是否配置了
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}一般更改daemon.json文件会docker启动失败
参考文献
nvidia-docker
Ubuntu18.04安装nvidia-docker(亲测有效,步骤详尽)
Nvidia-Docker安装使用 -- 可使用GPU的Docker容器
Docker容器和镜像的导入、导出
一文快速入门docker和nvidia-docker
cache 机制注意事项














 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









