









FastText 论文:
Joulin, Armand, et al. “Bag of tricks for efficient text classification.” arXiv preprint arXiv:1607.01759 (2016).
FastText模型原理
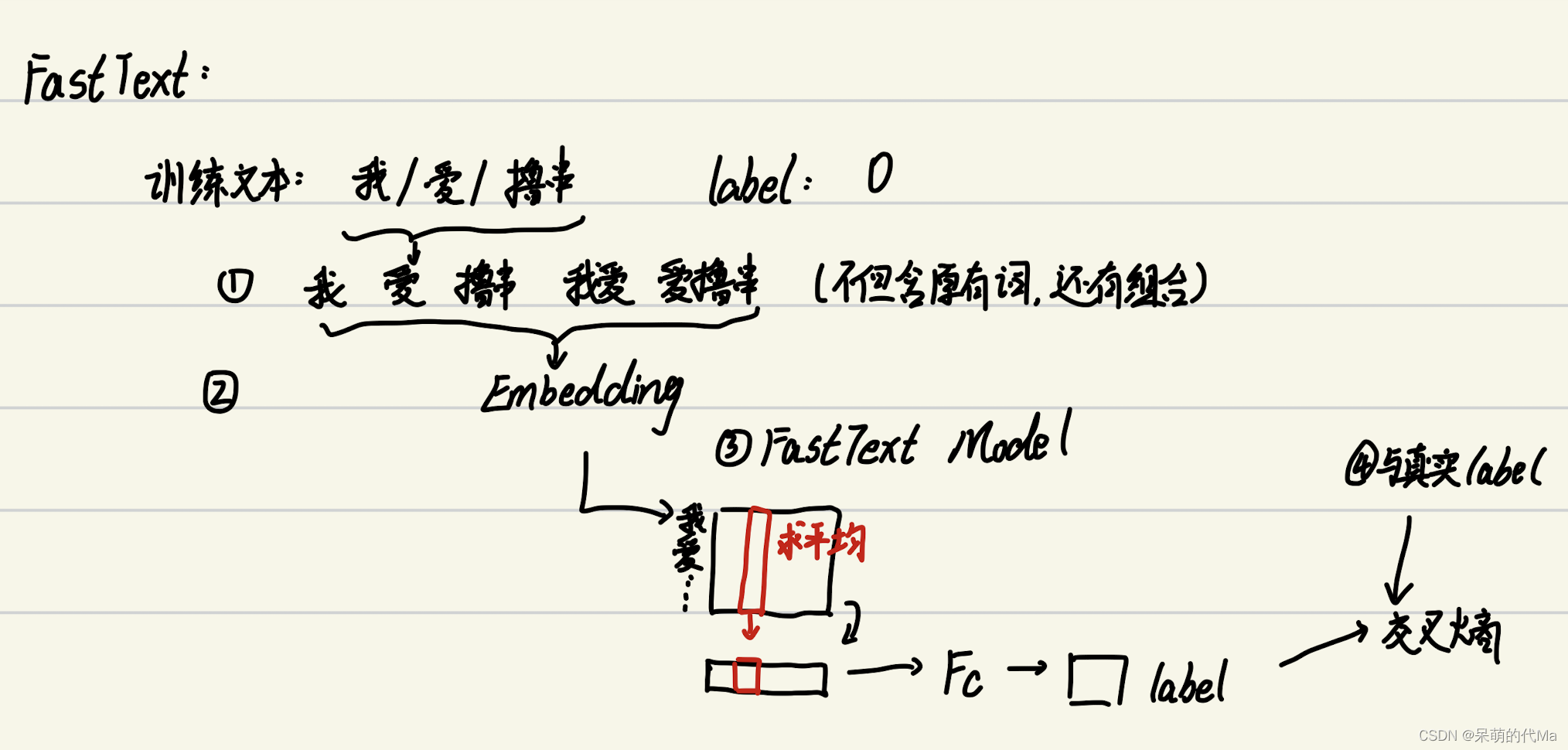
整体流程如下:
- 首先对文本预处理,分词后,对一个句子中的词做Ngram的聚合(比如示例中“我爱撸串”,不但每个词都有独立的token,词与词之间的组合也有专属token)
- 将
词->token->embedding,每个句子都是一个特征图,输入到模型中 - FastText模型也很简单,对每个词的对应位置使用均值做池化操作(就是对应位置相加后求平均),然后这样就得到与词向量相同维度的句向量,最后接一个全连接即可
- FastText在分类问题上,最后全连接会输出一个预测label,与真实的label计算交叉熵并迭代优化
FastText的模型有两个特点:
- 预处理文本的时候使用了Ngram来处理原始文本
- 它在训练的时候是有监督的,最后使用模型的时候,既可以借助embedding来获得词向量,也可以池化后得到句向量,甚至可以直接通过整个FastText得到原始任务的结果
FastText Hash优化
复现代码中没有这部分,这一部分改进也很简单:
由于使用Ngram的聚合会使文本的数据量大量增加,因此为了解决这个问题,就剥夺了每个词或词组的专属token,转而将Ngram得出的词使用hash映射到一个固定的embedding中。意思就是:
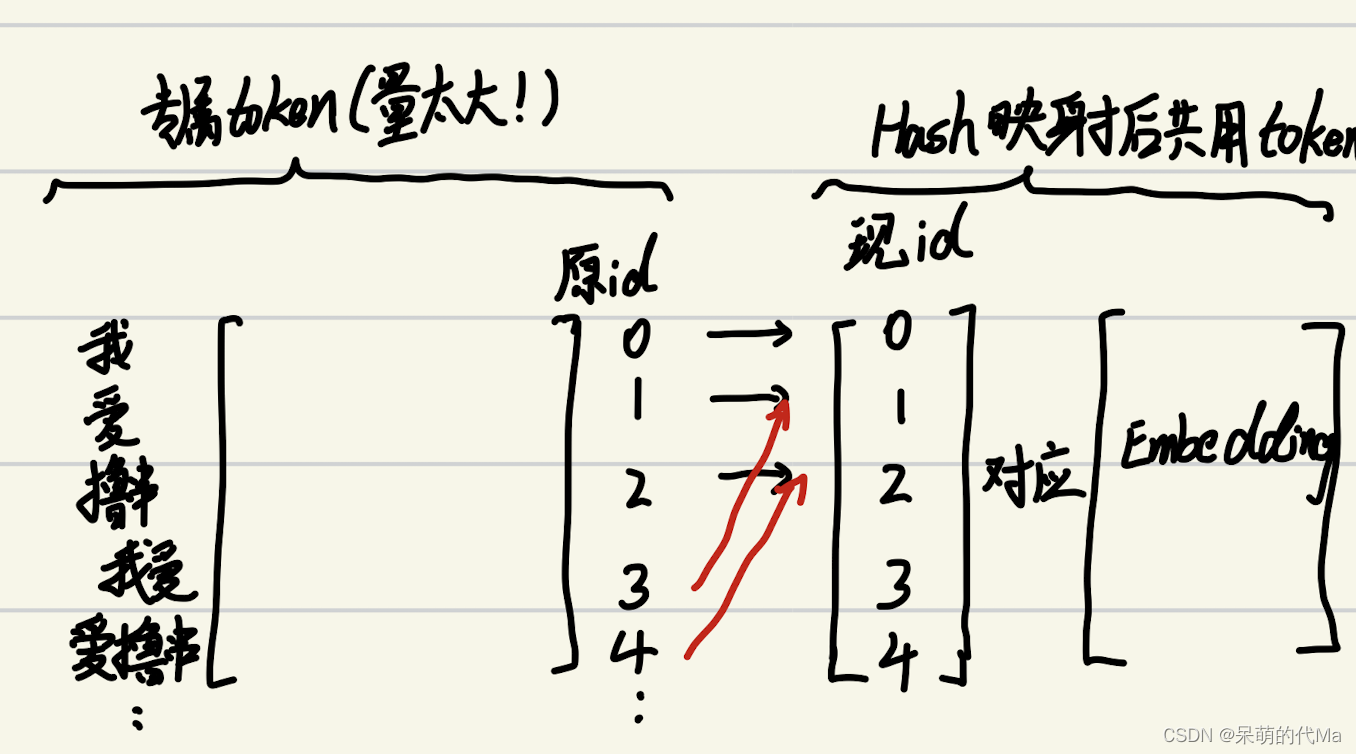
原始论文里优化就到此为止了,但却引申出另一个问题:你不知道跟你共享一个屋子的Ngram是小仙女还是抠脚大汉(可能共享一个token的Ngram与原来的词含义相差甚远),所以这又推出了更多的优化方向(狗头)
Pytorch复现代码
import numpy as np
from torchtext.vocab import vocab
from collections import Counter, OrderedDict
from torch.utils.data import Dataset, DataLoader
from torchtext.transforms import VocabTransform # 注意:torchtext版本0.12+
import torch
from torch import nn
from torch.nn import functional as F
from torchtext.data.utils import ngrams_iterator
def get_text():
# FastText是有监督的构造预训练模型,因此训练数据既有语料,也有label
# 这里复现时我们的label设置为分类问题
sentence_list = [ # 假设这是全部的训练语料
"nlp drives computer programs that translate text from one language to another",
"nlp combines computational linguistics rule based modeling of human language with statistical",
"nlp model respond to text or voice data and respond with text",
"nlp model for sentiment analysis are provided by human",
"nlp drives computer programs that translate text from one language to another",
"nlp combines computational linguistics rule based modeling of human language with statistical",
"nlp model respond to text or voice data and respond with text",
"nlp model for sentiment analysis are provided by human",
]
sentence_label = [0, 1, 1, 0, 0, 1, 1, 0]
return sentence_list, sentence_label
def pad_or_cut(value: np.ndarray, target_length: int):
"""填充或截断一维numpy到固定的长度"""
data_row = None
if len(value) < target_length: # 填充
data_row = np.pad(value, [(0, target_length - len(value))])
elif len(value) > target_length: # 截断
data_row = value[:target_length]
return data_row
class FastTextDataSet(Dataset):
def __init__(self, text_list, text_label, max_length=20):
"""
构造适用于FastText的采样Dataset
:param text_list: 语料文本内容
:param text_label: 语料的标签
:param max_length: 文本的最长长度,超过就截断,不足就补充
"""
super(FastTextDataSet, self).__init__()
text_vocab, vocab_transform = self.reform_vocab(text_list)
self.text_list = text_list # 原始文本
self.text_label = text_label # 有监督的label
self.text_vocab = text_vocab # torchtext的vocab
self.vocab_transform = vocab_transform # torchtext的vocab_transform
self.fast_data = self.generate_fast_text_data()
self.max_length = max_length
def __len__(self):
return len(self.fast_data)
def __getitem__(self, idx):
data_row = self.fast_data[idx]
data_row = pad_or_cut(data_row, self.max_length)
data_label = self.text_label[idx]
return data_row, data_label
def reform_vocab(self, text_list):
"""根据语料构造torchtext的vocab"""
total_word_list = []
for _ in text_list: # 将嵌套的列表([[xx,xx],[xx,xx]...])拉平 ([xx,xx,xx...])
total_word_list += list(ngrams_iterator(_.split(" "), 2)) # 这里使用n-gram处理原始单词
counter = Counter(total_word_list) # 统计计数
sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[1], reverse=True) # 构造成可接受的格式:[(单词,num), ...]
ordered_dict = OrderedDict(sorted_by_freq_tuples)
# 开始构造 vocab
special_token = ["<UNK>", "<SEP>"] # 特殊字符
text_vocab = vocab(ordered_dict, specials=special_token) # 单词转token,specials里是特殊字符,可以为空
text_vocab.set_default_index(0)
vocab_transform = VocabTransform(text_vocab)
return text_vocab, vocab_transform
def generate_fast_text_data(self):
"""生成Fasttext的训练数据"""
fast_data = []
for sentence in self.text_list:
all_sentence_words = list(ngrams_iterator(sentence.split(' '), 2))
sentence_id_list = np.array(self.vocab_transform(all_sentence_words))
fast_data.append(sentence_id_list)
return fast_data
def get_vocab_transform(self):
return self.vocab_transform
def get_vocab_size(self):
return len(self.text_vocab)
class FastTextModel(nn.Module):
def __init__(self, vocab_size, embedding_dim=100, output_dim=2):
"""
FastText 模型
:param vocab_size: 语料大小
:param embedding_dim: 每个词的词向量维度
:param output_dim: 输出的维度,由于咱们是二分类问题,所以输出两个值,后面用交叉熵优化
"""
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim, output_dim)
def forward(self, text_token):
embedded = self.embedding(text_token) # shape:[batch_size, 单词长度, embedding_dim]
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1) # [batch size, embedding_dim]
out_put = self.linear(pooled)
return out_put
def get_embedding(self, token_list: list):
return self.embedding(torch.Tensor(token_list).long())
def main():
batch_size = 3
# ========== 开始处理数据 ==========
sentence_list, sentence_label = get_text()
fasttext_data_set = FastTextDataSet(sentence_list, sentence_label) # 构造 DataSet
data_loader = DataLoader(fasttext_data_set, batch_size=batch_size) # 将DataSet封装成DataLoader
# =========== 开始训练 ==========
model = FastTextModel(fasttext_data_set.get_vocab_size(), output_dim=np.unique(sentence_label).size)
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
for _epoch_i in range(30):
loss_list = []
for text_token, text_label in data_loader:
# 开始训练
optimizer.zero_grad()
model_out = model(text_token)
loss = criterion(model_out, text_label)
loss.backward()
optimizer.step()
loss_list.append(loss.item())
print("训练中:", _epoch_i, "Loss:", np.sum(loss_list))
# ================== 最后测试 =====================
# 得到: nlp can translate text from one language to another 的词向量
sentence = "nlp can translate text from one language to another"
vocab_transform = fasttext_data_set.get_vocab_transform()
# sentence_ids = vocab_transform(sentence.split(' '))
all_sentence_words = list(ngrams_iterator(sentence.split(' '), 2))
sentence_id_list = pad_or_cut(np.array(vocab_transform(all_sentence_words)), target_length=20)
sentence_embedding = model.get_embedding(sentence_id_list)
# 句向量的特征图对应着 sentence_embedding
print("这个是句向量的维度:", sentence_embedding.shape)
# =================== 直接用FastText分类 =====================
text_tensor = torch.Tensor(sentence_id_list).long()
text_tensor = text_tensor.unsqueeze(0) # 整理输入
_, predicted = torch.max(model(text_tensor).data, 1) # 得到预测结果
print("直接用FastText分类:", predicted)
if __name__ == '__main__':
main()
















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











