







为什么将CSV的数据发到kafka
flink做流式计算时,选用kafka消息作为数据源是常用手段,因此在学习和开发flink过程中,也会将数据集文件中的记录发送到kafka,来模拟不间断数据;
整个流程如下:
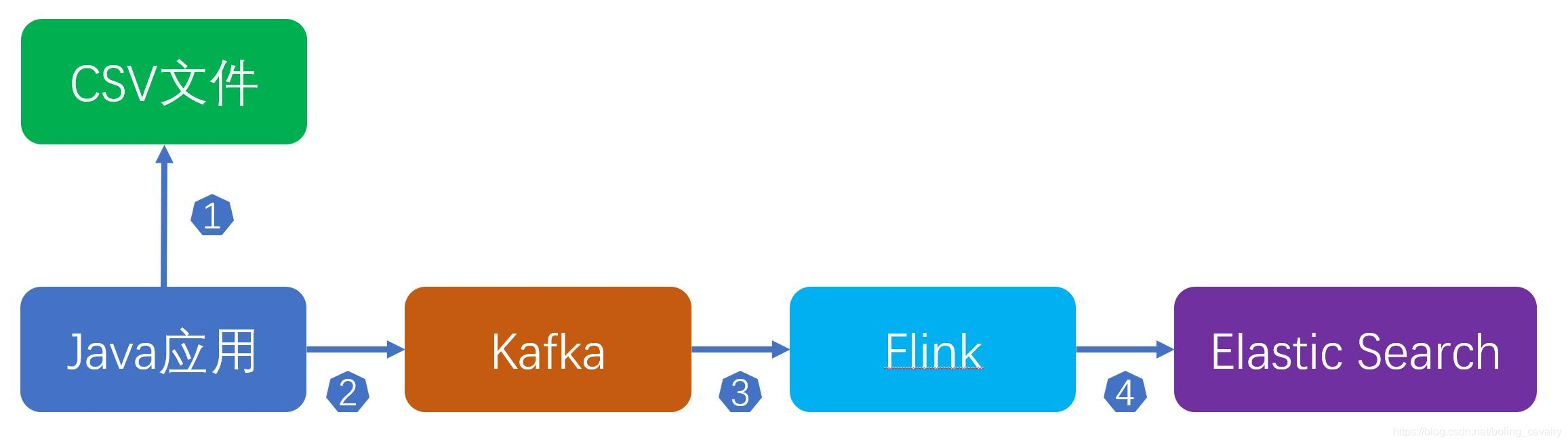
您可能会觉得这样做多此一举:flink直接读取CSV不就行了吗?这样做的原因如下:
首先,这是学习和开发时的做法,数据集是CSV文件,而生产环境的实时数据却是kafka数据源;
其次,Java应用中可以加入一些特殊逻辑,例如数据处理,汇总统计(用来和flink结果对比验证);
另外,如果两条记录实际的间隔时间如果是1分钟,那么Java应用在发送消息时也可以间隔一分钟再发送,这个逻辑在flink社区的demo中有具体的实现,此demo也是将数据集发送到kafka,再由flink消费kafka,地址是:https://github.com/ververica/sql-training
如何将CSV的数据发送到kafka
前面的图可以看出,读取CSV再发送消息到kafka的操作是Java应用所为,因此今天的主要工作就是开发这个Java应用,并验证;
版本信息
JDK:1.8.0_181
开发工具:IntelliJ IDEA 2019.2.1 (Ultimate Edition)
开发环境:Win10
Zookeeper:3.4.13
Kafka:2.4.0(scala:2.12)
关于数据集
列名称
说明
用户ID
整数类型,序列化后的用户ID
商品ID
整数类型,序列化后的商品ID
商品类目ID
整数类型,序列化后的商品所属类目ID
行为类型
字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav')
时间戳
行为发生的时间戳
时间字符串
根据时间戳字段生成的时间字符串
关于该数据集的详情,请参考《准备数据集用于flink学习》
Java应用简介
编码前,先把具体内容列出来,然后再挨个实现:
从CSV读取记录的工具类:UserBehaviorCsvFileReader
每条记录对应的Bean类:UserBehavior
Java对象序列化成JSON的序列化类:JsonSerializer
向kafka发送消息的工具类:KafkaProducer
应用类,程序入口:SendMessageApplication
上述五个类即可完成Java应用的工作,接下来开始编码吧;
直接下载源码
如果您不想写代码,您可以直接从GitHub下载这个工程的源码,地址和链接信息如下表所示:
名称
链
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









