






最近要做一个自动补全搜索的项目,很久没看了,都生疏了,过年的时候也写过好几篇相关文章(见文末),相比以前的自动补全,本次增加了两个新功能:
支持拼音全拼、拼音prefix补全
支持模糊自动补全
对于拼音,主要就是使用pinyin分词插件,具体的原理后续分享,本文的目的是说明如何进行拼音补全。
首先就是建模,如下图:


可以看出full_pinyin、prefix_pinyin这两个filter就是支持全拼、拼音prefix,加上standard标准分词的搜索,原理很简单,相当于一个词可以通过三种类型的分词进行匹配,增大了匹配范围。
其次如何补全呢?见下图:
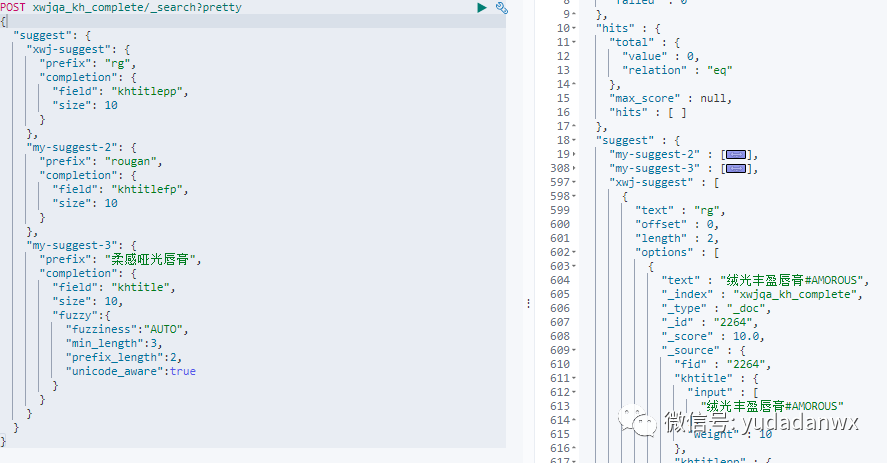
可以看出最多会匹配三个suggest,虽然同时匹配的几率很小,但从程序的角度看,还是要处理排序问题,在本次项目中weight都相同的,排序完全基于匹配度。
这个排序已经不是ELK的问题了,只能应用去处理,每个suggest下的item有优先级,不同suggest又有优先级。目前想到的方法就是只要每种suggest存在,就先取top3,然后组合在一起,standard优先级>全拼>拼音prefix,接下去就是每个suggest的剩余部分组合在一起,最后排重相同ID的数据。
为什么这样排列优先级呢?主要考虑到补全精确性的情况,谁都希望standard的能先补全,而拼音prefix筛选出不相干的数据可能相对较多。
另外这图中也可以看出,这个例子支持一定的模糊匹配。
《elasticsearch自动补全优化》
《再论elasticsearch自动补全在实战中的优化》














 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









