







 现在很多行业,都离不开Excel:
做财务的,要用Excel做报表;
做物流的,会用Excel来跟踪订单情况;
做HR的,会用Excel算工资;
做运营的,会用Excel记录数据做分析。
不知道你有没有这样的经历,每次你用Excel做数据分析时,往往都要生成好多张工作簿,做中间计算的时候,
鼠标要一路移到最后一页,
才出现最终结果。
如果其中某个数据出了些问题,你可能要从头开始,排查错误,
很容易看花眼,错上加错。
现在很多行业,都离不开Excel:
做财务的,要用Excel做报表;
做物流的,会用Excel来跟踪订单情况;
做HR的,会用Excel算工资;
做运营的,会用Excel记录数据做分析。
不知道你有没有这样的经历,每次你用Excel做数据分析时,往往都要生成好多张工作簿,做中间计算的时候,
鼠标要一路移到最后一页,
才出现最终结果。
如果其中某个数据出了些问题,你可能要从头开始,排查错误,
很容易看花眼,错上加错。
 为了避免这种情况,很多人开始学
Excel的高级技能 - VBA
。
但其实,VBA并不容易学,而且在数据量大的情况下,VBA运行很耗时。
那么我们应该怎么解决呢?用
Python呀!
相比VBA,Python非常容易入门,而且用途广泛。
别人用Excel花2天做的事情,Python
1ge 小时就能搞定。
下面就用几个常见的操作带你感受一下:
为了避免这种情况,很多人开始学
Excel的高级技能 - VBA
。
但其实,VBA并不容易学,而且在数据量大的情况下,VBA运行很耗时。
那么我们应该怎么解决呢?用
Python呀!
相比VBA,Python非常容易入门,而且用途广泛。
别人用Excel花2天做的事情,Python
1ge 小时就能搞定。
下面就用几个常见的操作带你感受一下:
数据读取、生成、存储
Excel读取本地数据需要打开目标文件夹选中该文件并打开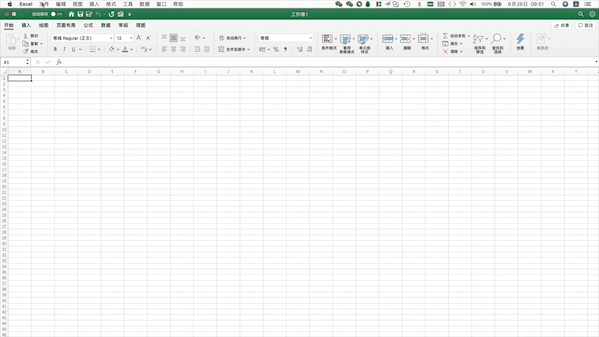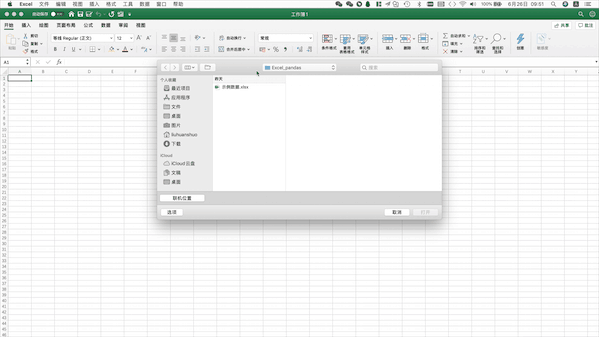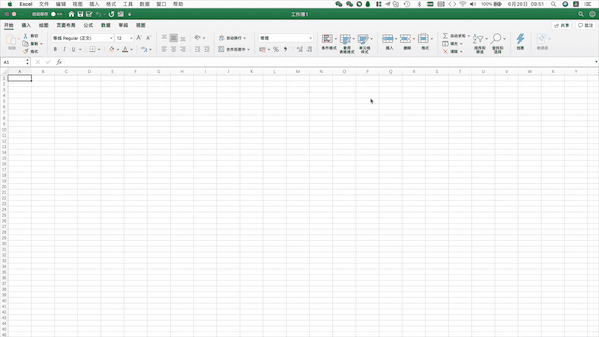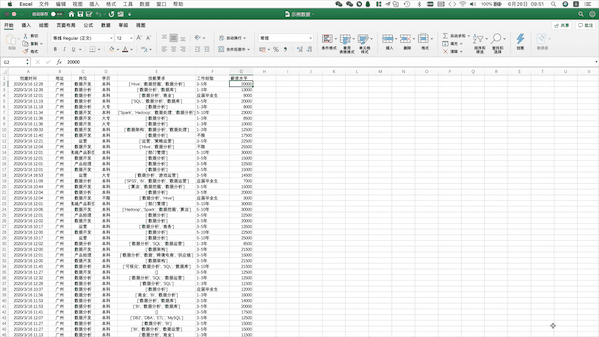 Pandas支持读取本地Excel、txt文件,也支持从网页直接读取表格数据,只用一行代码即可,例如读取上述本地Excel数据可以使用pd.read_excel("示例数据.xlsx")
Pandas支持读取本地Excel、txt文件,也支持从网页直接读取表格数据,只用一行代码即可,例如读取上述本地Excel数据可以使用pd.read_excel("示例数据.xlsx")
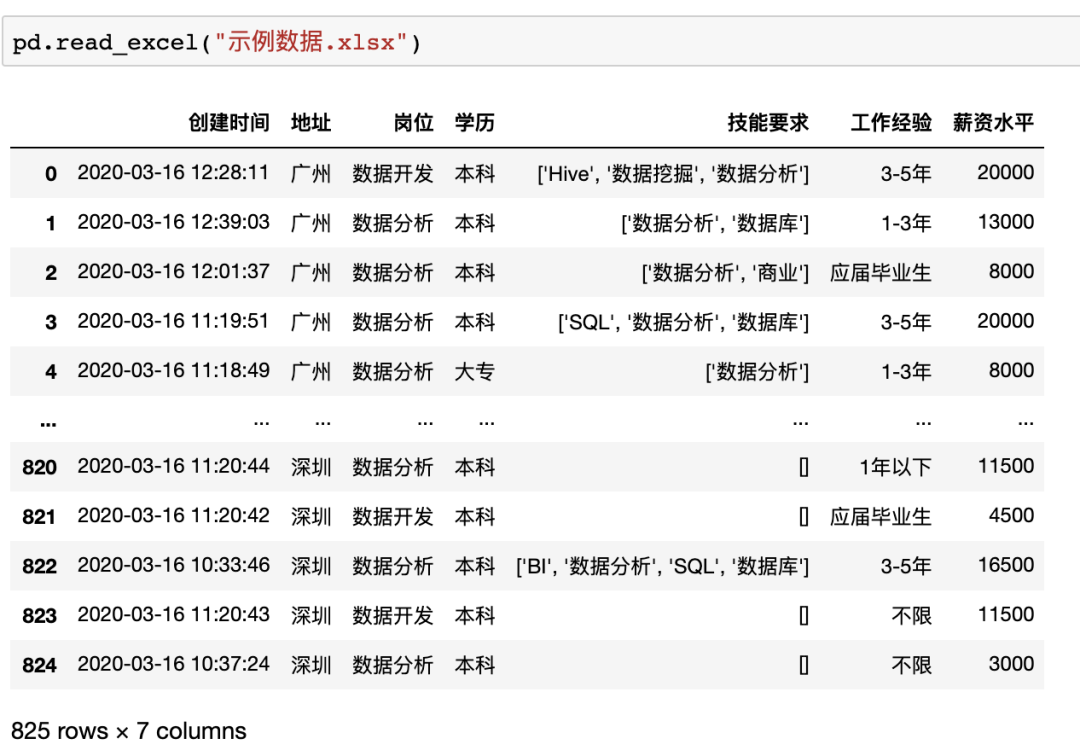 以生成10*2的0—1均匀分布随机数矩阵为例,在Excel中需要使用rand()函数生成随机数,并手动拉取指定范围
以生成10*2的0—1均匀分布随机数矩阵为例,在Excel中需要使用rand()函数生成随机数,并手动拉取指定范围
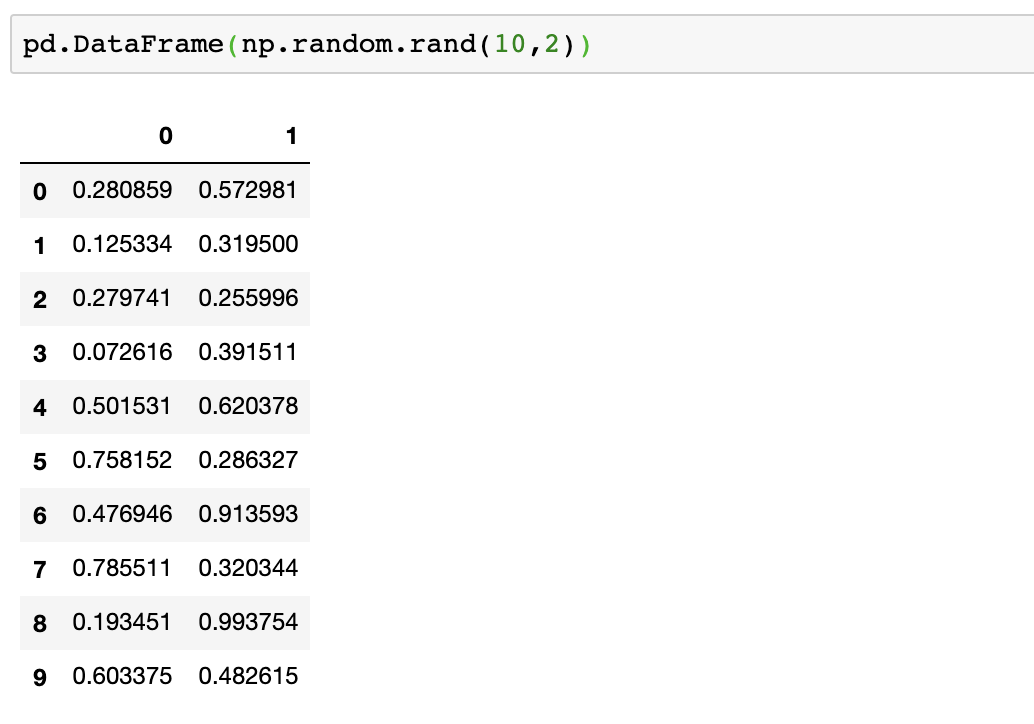
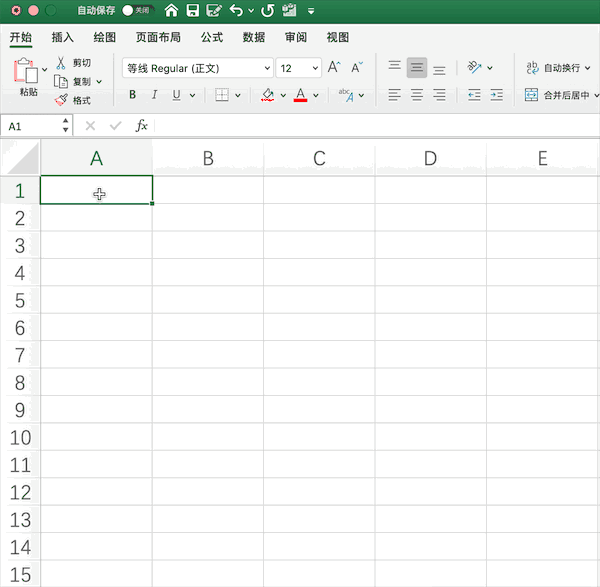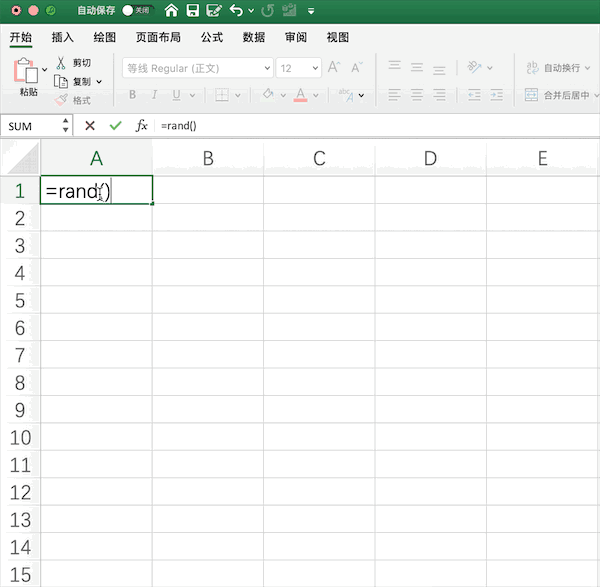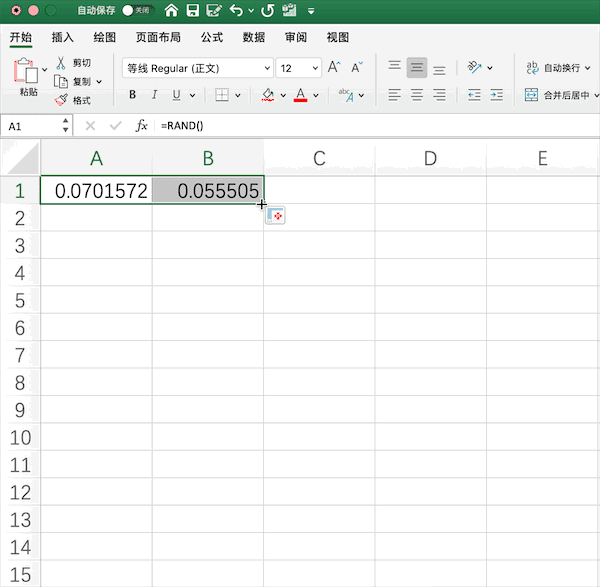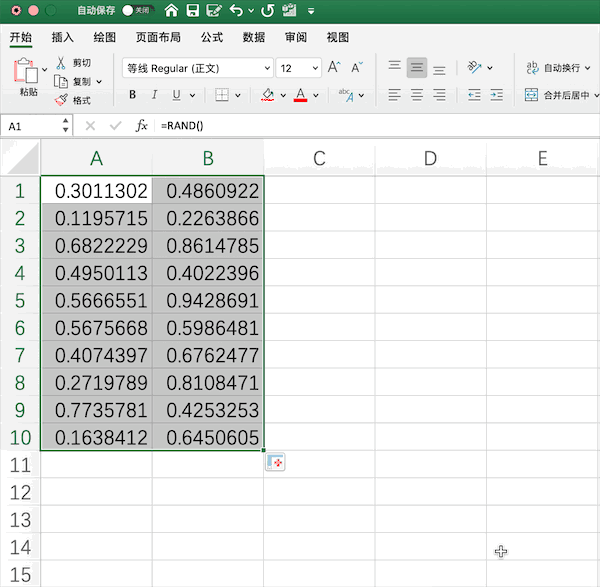 在Pandas中可以结合NumPy生成由指定随机数(均匀分布、正态分布等)生成的矩阵,例如同样生成10*2的0—1均匀分布随机数矩阵为,使用一行代码即可:pd.DataFrame(np.random.rand(10,2))
在Pandas中可以结合NumPy生成由指定随机数(均匀分布、正态分布等)生成的矩阵,例如同样生成10*2的0—1均匀分布随机数矩阵为,使用一行代码即可:pd.DataFrame(np.random.rand(10,2))
 在Excel中需要点击保存并设置格式/文件名
在Excel中需要点击保存并设置格式/文件名
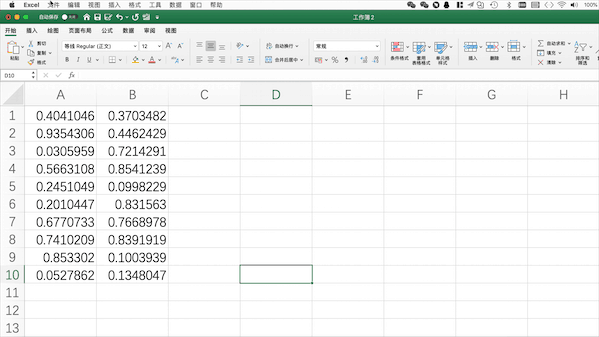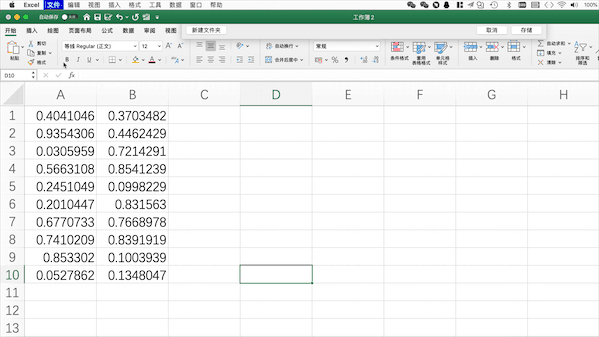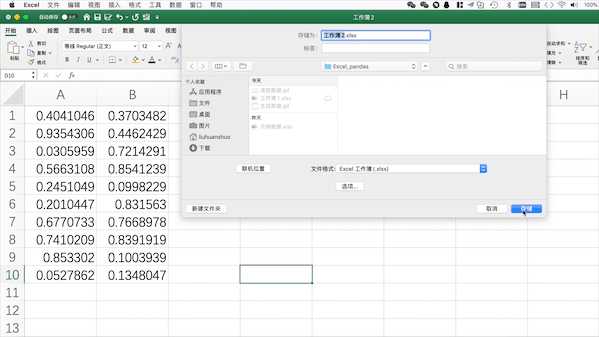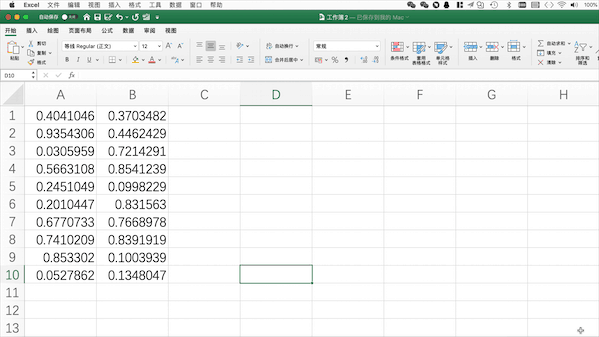 在Pandas中可以使用pd.to_excel("filename.xlsx")来将当前工作表格保存至当前目录下,当然也可以使用to_csv保存为csv等其他格式,也可以使用绝对路径来指定保存位置
在Pandas中可以使用pd.to_excel("filename.xlsx")来将当前工作表格保存至当前目录下,当然也可以使用to_csv保存为csv等其他格式,也可以使用绝对路径来指定保存位置

筛选、排序、去重数据
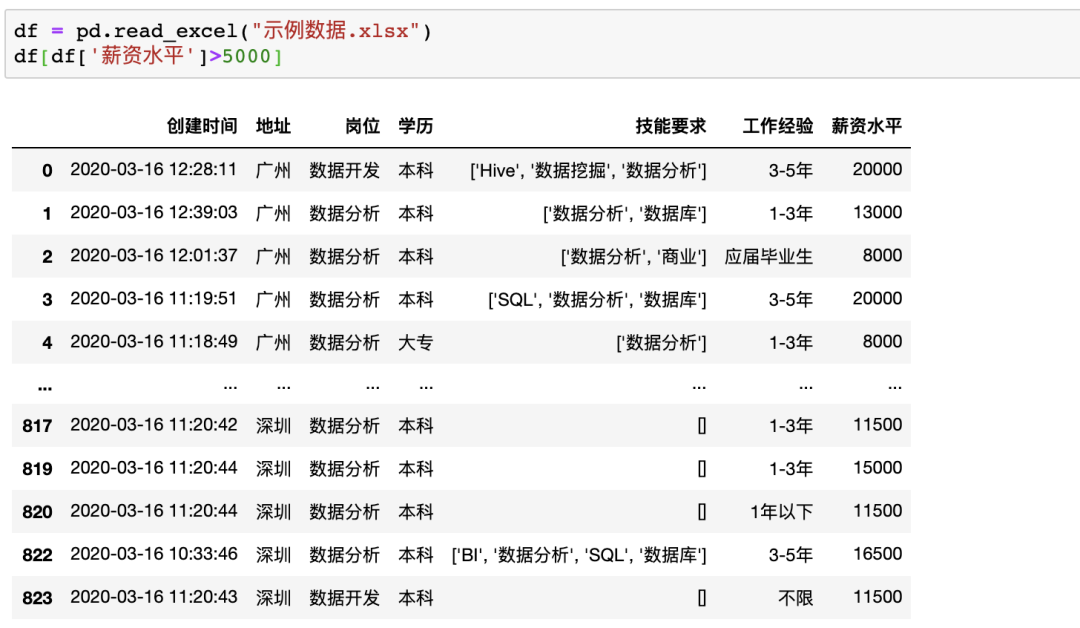
使用我们之前的示例数据,在Excel中筛选出薪资大于5000的数据步骤如下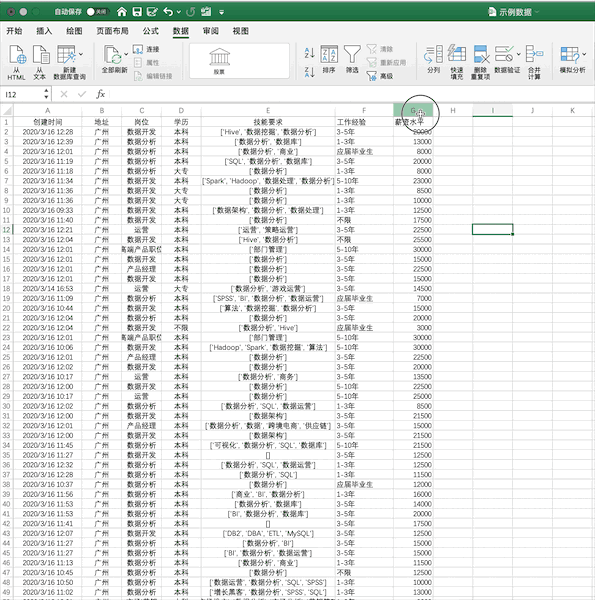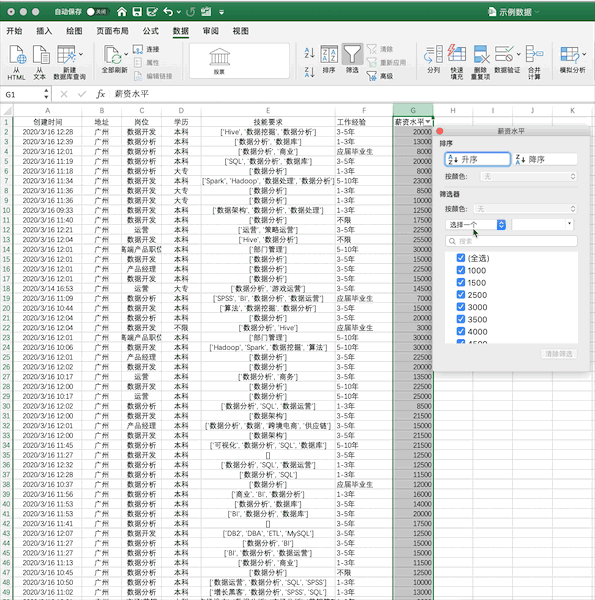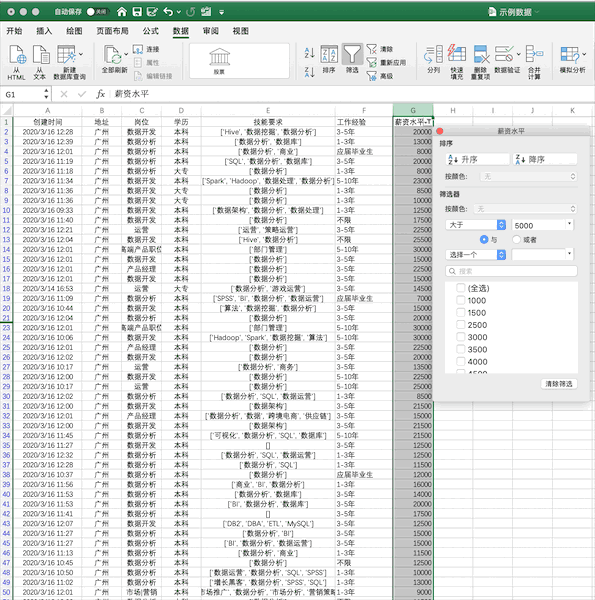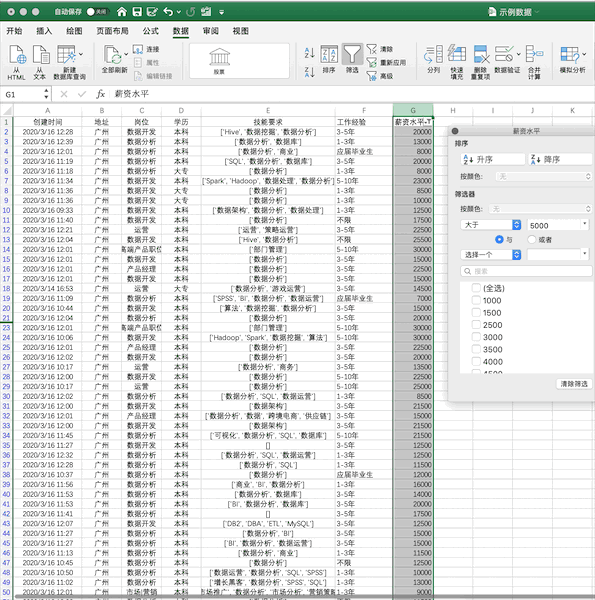 在Pandas中,可直接对数据框进行条件筛选,例如同样进行单个条件(薪资大于5000)的筛选可以使用df[df['薪资水平']>5000],如果使用多个条件的筛选只需要使用&(并)与|(或)操作符实现
在Pandas中,可直接对数据框进行条件筛选,例如同样进行单个条件(薪资大于5000)的筛选可以使用df[df['薪资水平']>5000],如果使用多个条件的筛选只需要使用&(并)与|(或)操作符实现
 在Excel中可以点击排序按钮进行排序,例如将示例数据按照薪资从高到低进行排序可以按照下面的步骤进行
在Excel中可以点击排序按钮进行排序,例如将示例数据按照薪资从高到低进行排序可以按照下面的步骤进行
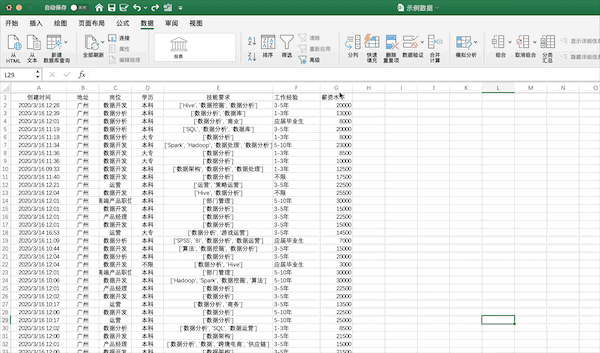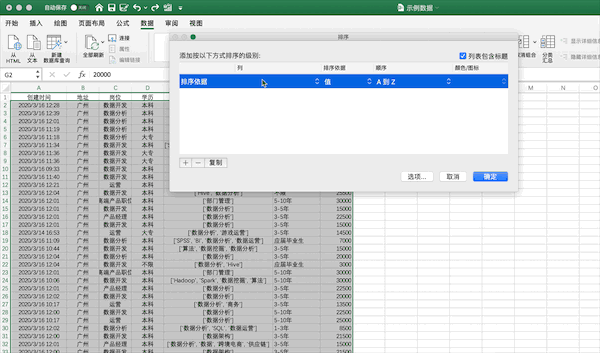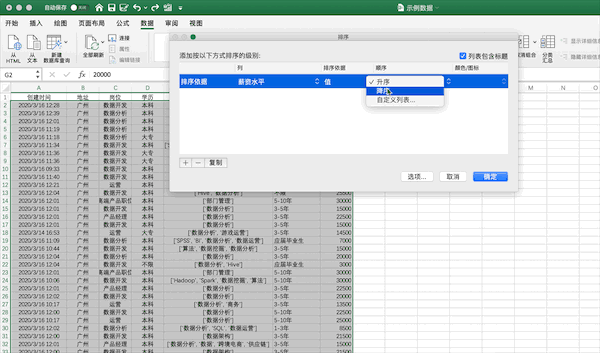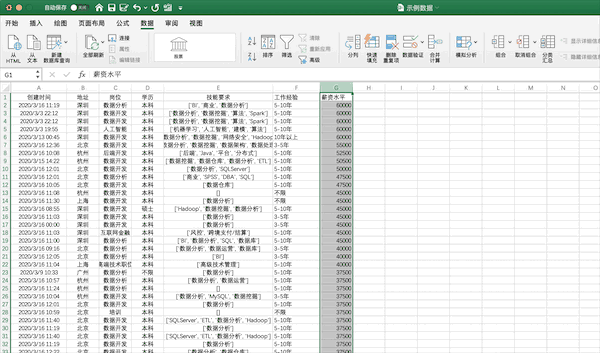 在pandas中可以使用sort_values进行排序,使用ascending来控制升降序,例如将示例数据按照薪资从高到低进行排序可以使用df.sort_values("薪资水平",ascending=False,inplace=True)
在pandas中可以使用sort_values进行排序,使用ascending来控制升降序,例如将示例数据按照薪资从高到低进行排序可以使用df.sort_values("薪资水平",ascending=False,inplace=True)
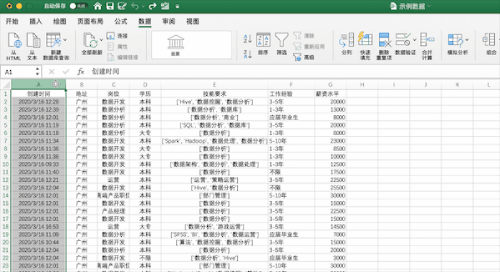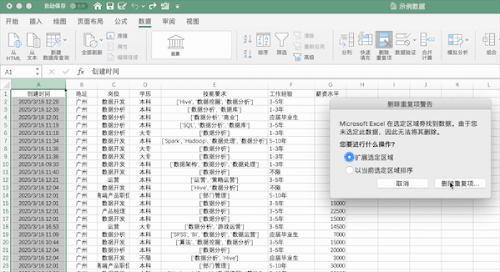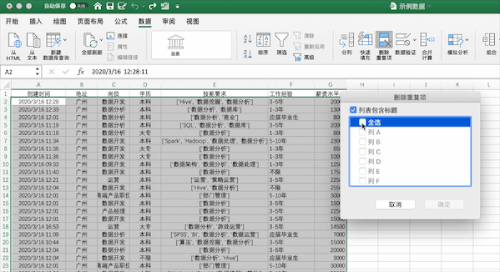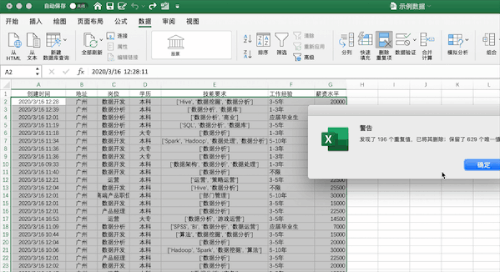
 在Excel中可以通过点击数据—>删除重复值按钮并选择需要去重的列即可,例如对示例数据按照创建时间列进行去重,可以发现去掉了196 个重复值,保留了 629 个唯一值。
在Excel中可以通过点击数据—>删除重复值按钮并选择需要去重的列即可,例如对示例数据按照创建时间列进行去重,可以发现去掉了196 个重复值,保留了 629 个唯一值。
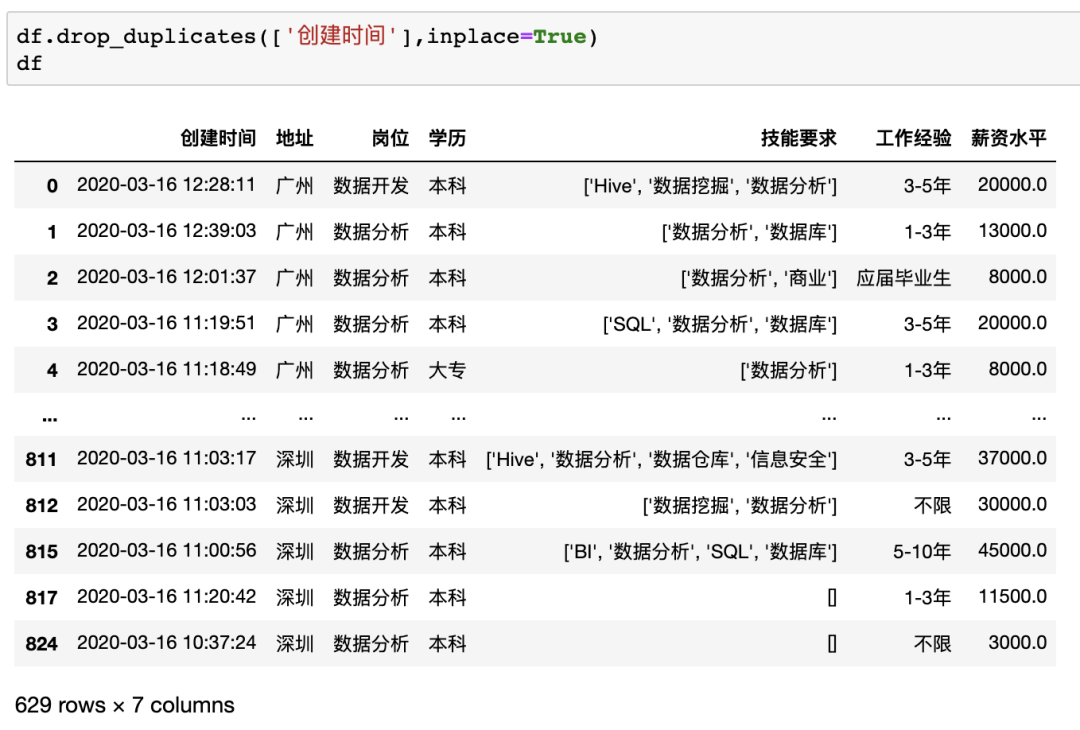
 在pandas中可以使用drop_duplicates来对数据进行去重,并且可以指定列以及保留顺序,例如对示例数据按照创建时间列进行去重df.drop_duplicates(['创建时间'],inplace=True),可以发现和Excel处理的结果一致,保留了 629 个唯一值。
在pandas中可以使用drop_duplicates来对数据进行去重,并且可以指定列以及保留顺序,例如对示例数据按照创建时间列进行去重df.drop_duplicates(['创建时间'],inplace=True),可以发现和Excel处理的结果一致,保留了 629 个唯一值。
合并/拆分数据
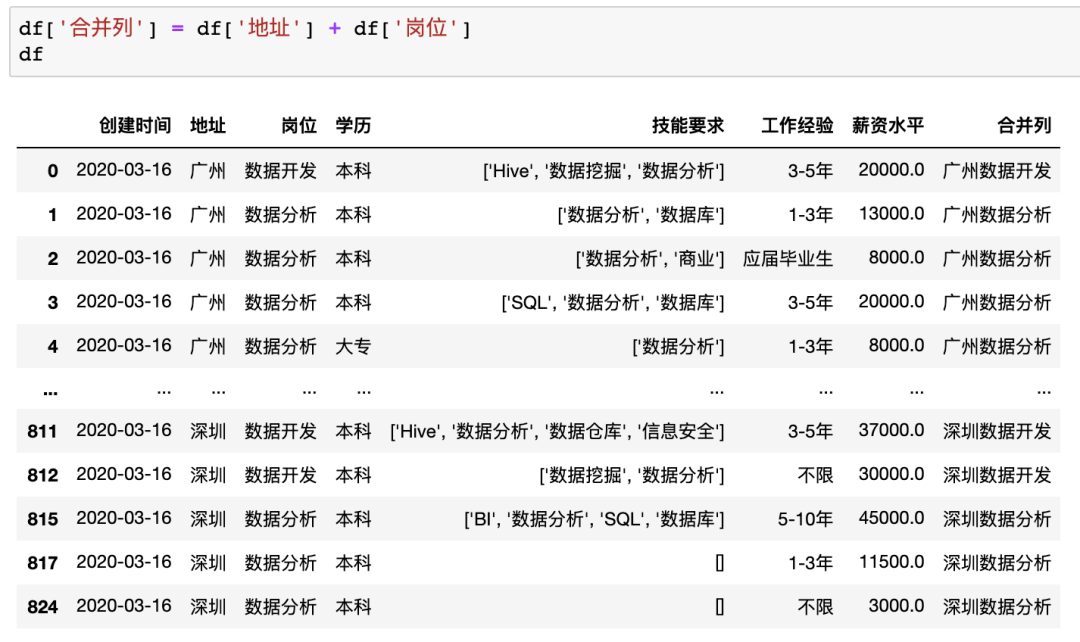
在Excel中可以使用公式也可以使用Ctrl+E快捷键完成多列合并,以公式为例,合并示例数据中的地址+岗位列步骤如下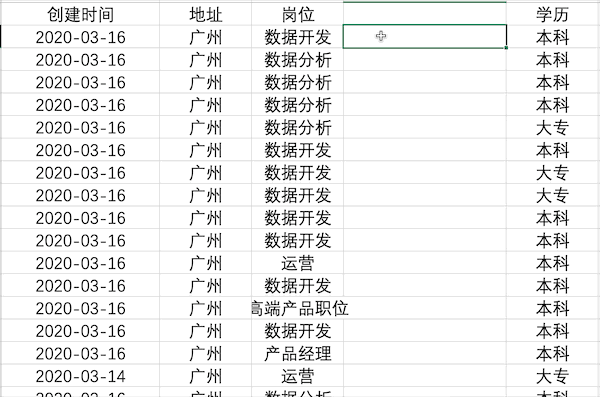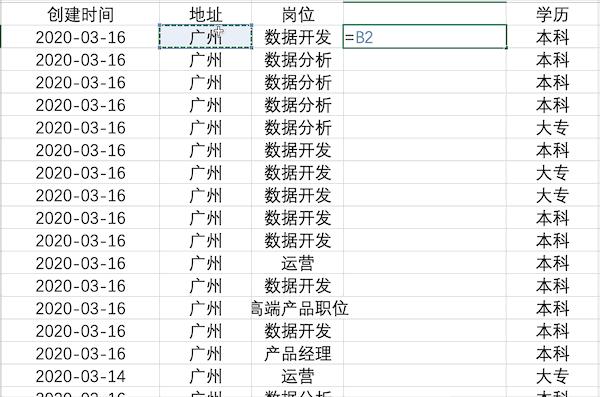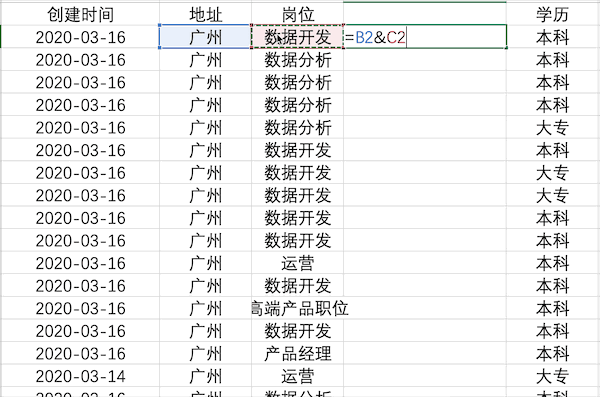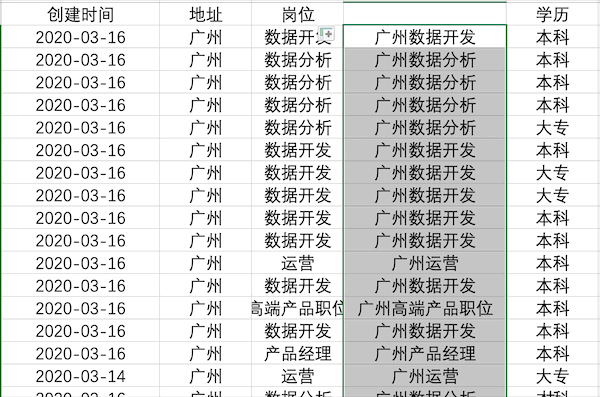 在Pandas中合并多列比较简单,类似于之前的数据插入操作,例如合并示例数据中的地址+岗位列使用df['合并列'] = df['地址'] + df['岗位']
在Pandas中合并多列比较简单,类似于之前的数据插入操作,例如合并示例数据中的地址+岗位列使用df['合并列'] = df['地址'] + df['岗位']
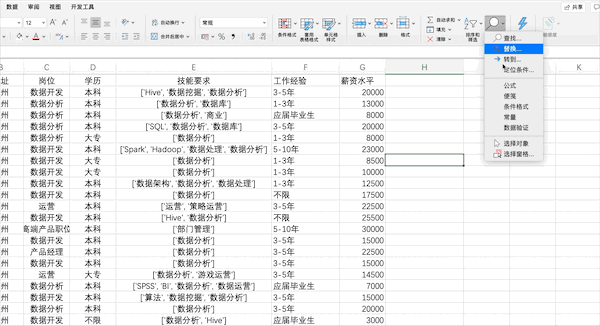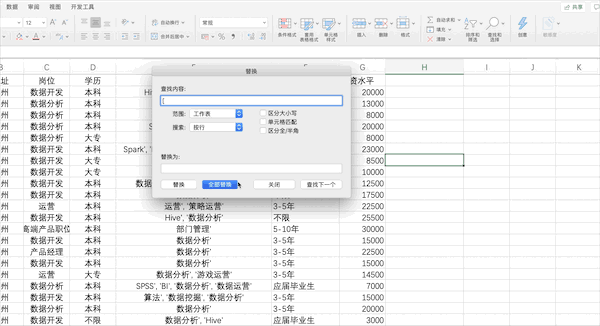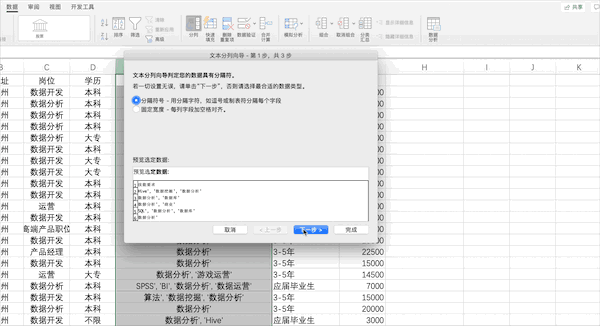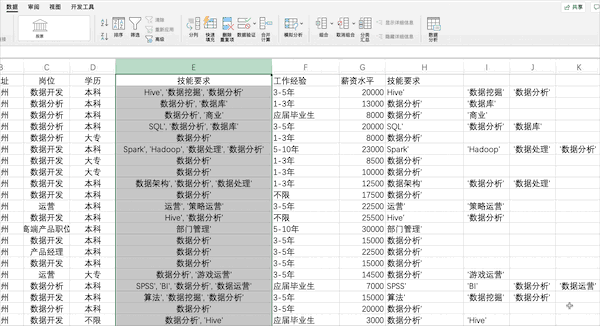
 拆分数据在Excel中可以通过点击
数据—>分列并按照提示的选项设置相关参数完成分列,但是由于该列含有[]等特殊字符,所以需要先使用查找替换去掉
拆分数据在Excel中可以通过点击
数据—>分列并按照提示的选项设置相关参数完成分列,但是由于该列含有[]等特殊字符,所以需要先使用查找替换去掉
 在Pandas中可以使用.split来完成分列,但是在分列完毕后需要使用merge来将分列完的数据添加至原DataFrame,对于分列完的数据含有[]字符,我们可以使用正则或者字符串lstrip方法进行处理,但因不是pandas特性,此处不再展开。
在Pandas中可以使用.split来完成分列,但是在分列完毕后需要使用merge来将分列完的数据添加至原DataFrame,对于分列完的数据含有[]字符,我们可以使用正则或者字符串lstrip方法进行处理,但因不是pandas特性,此处不再展开。
数据分组、统计、计算
在Excel中对数据进行分组计算需要先对需要分组的字段进行排序,之后可以通过点击分类汇总并设置相关参数完成,比如对示例数据的学历进行分组并求不同学历的平均薪资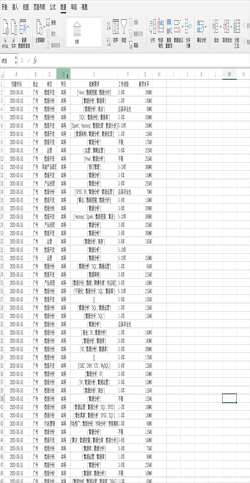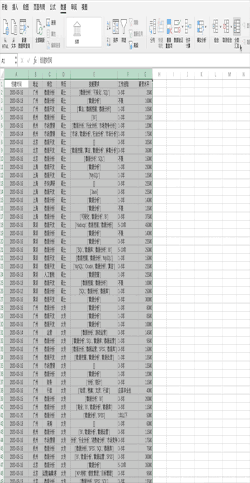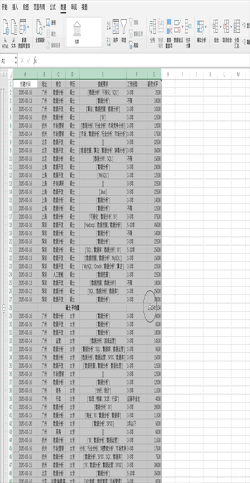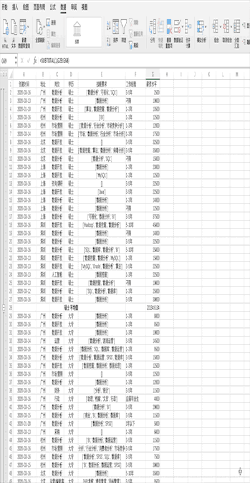 在Pandas中对数据进行分组计算可以使用groupby轻松搞定,比如使用df.groupby("学历").mean()一行代码即可对示例数据的学历进行分组并求不同学历的平均薪资,结果与Excel一致
在Pandas中对数据进行分组计算可以使用groupby轻松搞定,比如使用df.groupby("学历").mean()一行代码即可对示例数据的学历进行分组并求不同学历的平均薪资,结果与Excel一致
 在Excel中有很多统计相关的公式,也有现成的分析工具,比如对薪资水平列进行描述性统计分析,可以通过添加工具库之后点击数据分析按钮并设置相关参数
在Excel中有很多统计相关的公式,也有现成的分析工具,比如对薪资水平列进行描述性统计分析,可以通过添加工具库之后点击数据分析按钮并设置相关参数
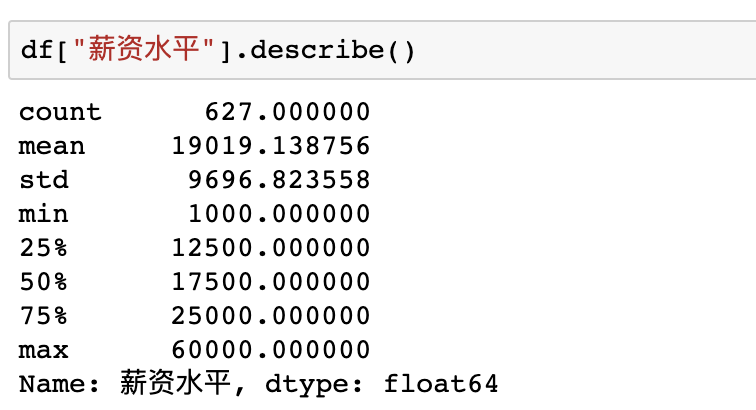
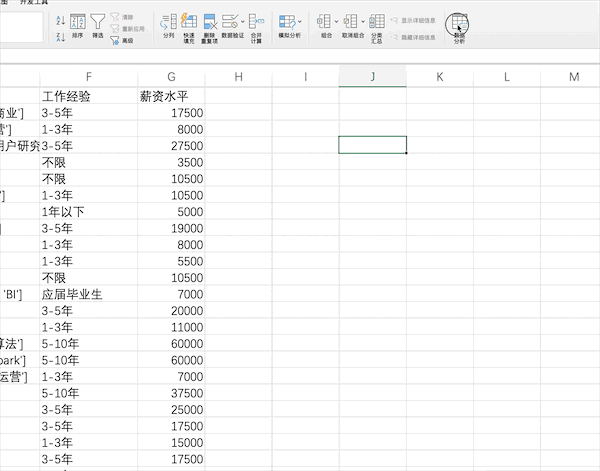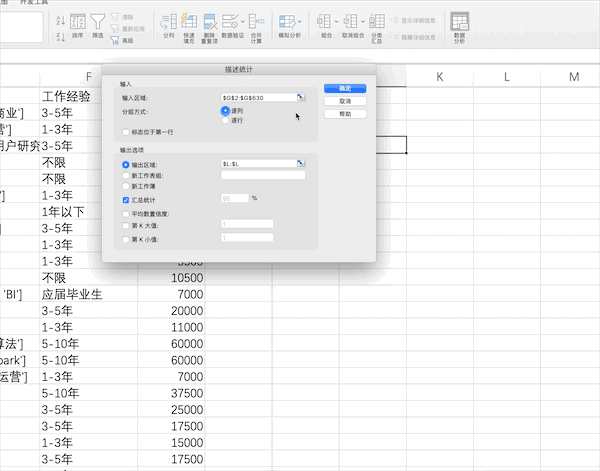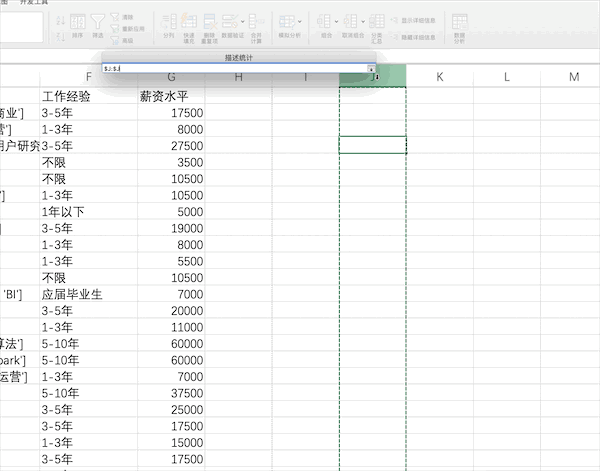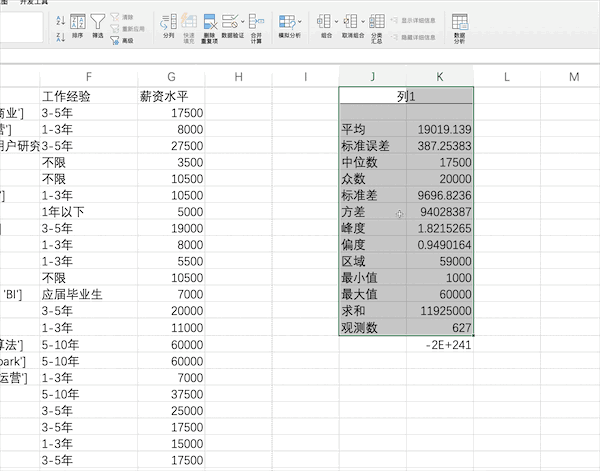 在pandas中也有现成的函数describe快速完成对数据的描述性统计,比如使用df["薪资水平"].describe()即可得到薪资列的描述性统计结果
在pandas中也有现成的函数describe快速完成对数据的描述性统计,比如使用df["薪资水平"].describe()即可得到薪资列的描述性统计结果
 在Excel中有很多计算相关的公式,比如可以使用COUNTIFS来统计薪资大于10000的岗位数量有518个
在Excel中有很多计算相关的公式,比如可以使用COUNTIFS来统计薪资大于10000的岗位数量有518个
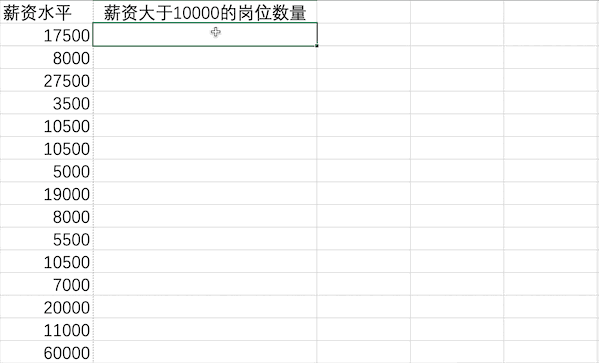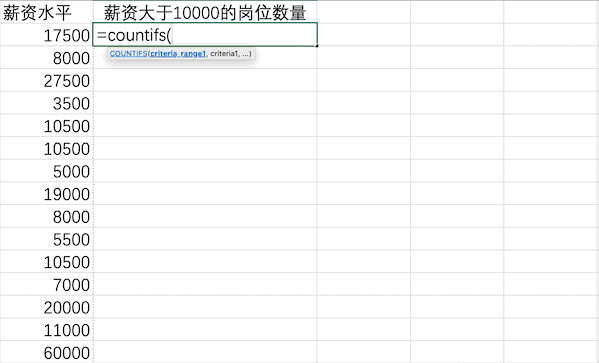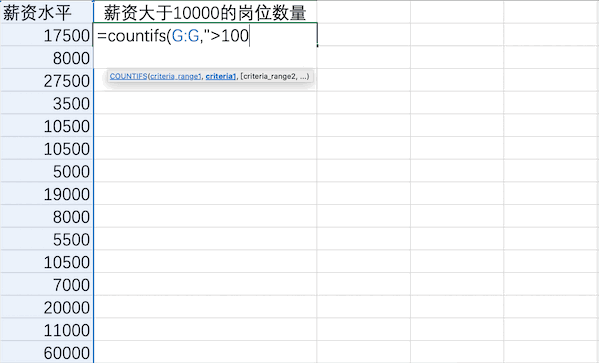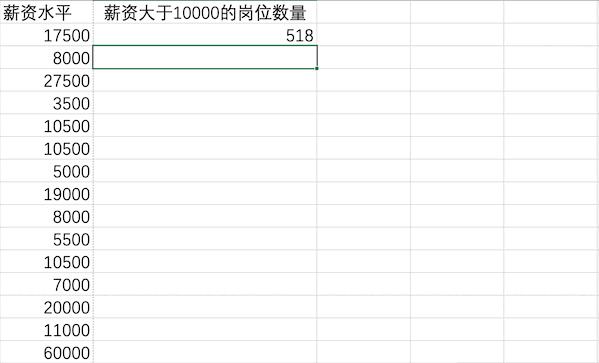 在Pandas中可以直接使用类似数据筛选的方法来统计薪资大于10000的岗位数量len(df[df["薪资水平"]>10000])
在Pandas中可以直接使用类似数据筛选的方法来统计薪资大于10000的岗位数量len(df[df["薪资水平"]>10000])

数据可视化
在Excel中可以通过点击插入并选择图表来快速完成对数据的可视化,比如制作薪资的直方图,并且有很多样式可以直接使用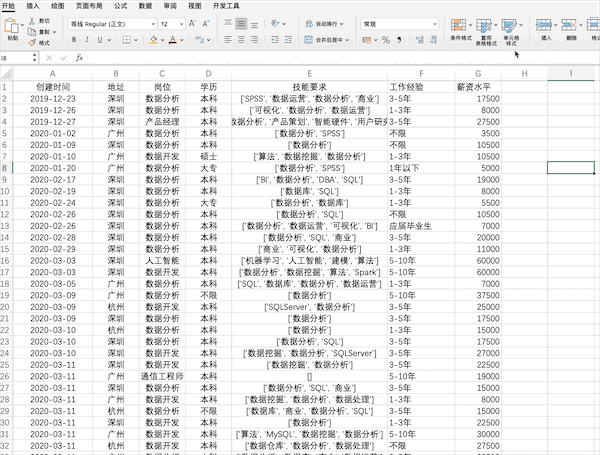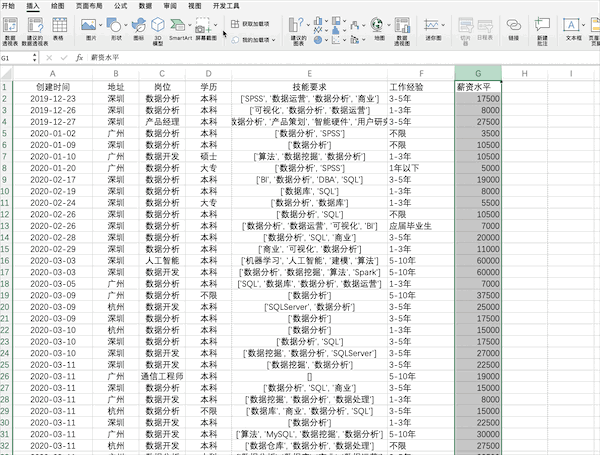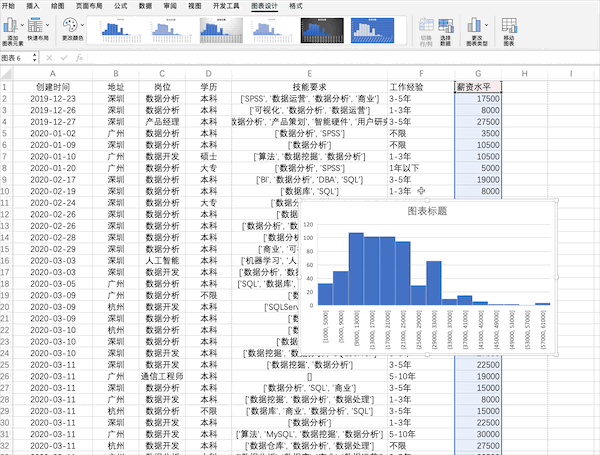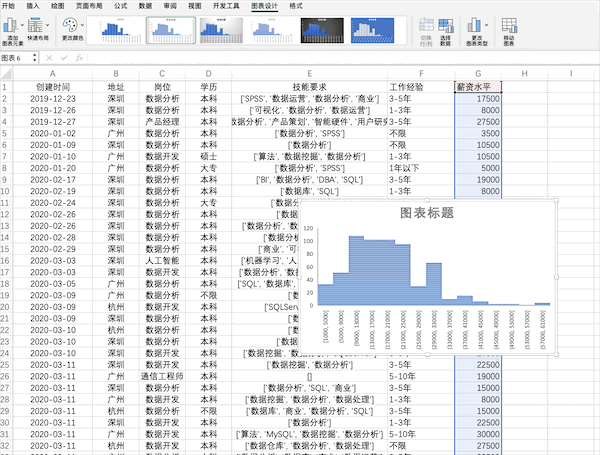 在Pandas中也支持直接对数据绘制不同可视化图表,例如直方图,可以使用plot或者直接使用hist来制作df["薪资水平"].hist()
也可以做数据透视表,在Excel中有现成的工具,只需要选中数据—>点击插入—>数据透视表即可生成,并且支持字段的拖取实现不同的透视表,非常方便,比如制作地址、学历、薪资的透视表
在Pandas中也支持直接对数据绘制不同可视化图表,例如直方图,可以使用plot或者直接使用hist来制作df["薪资水平"].hist()
也可以做数据透视表,在Excel中有现成的工具,只需要选中数据—>点击插入—>数据透视表即可生成,并且支持字段的拖取实现不同的透视表,非常方便,比如制作地址、学历、薪资的透视表
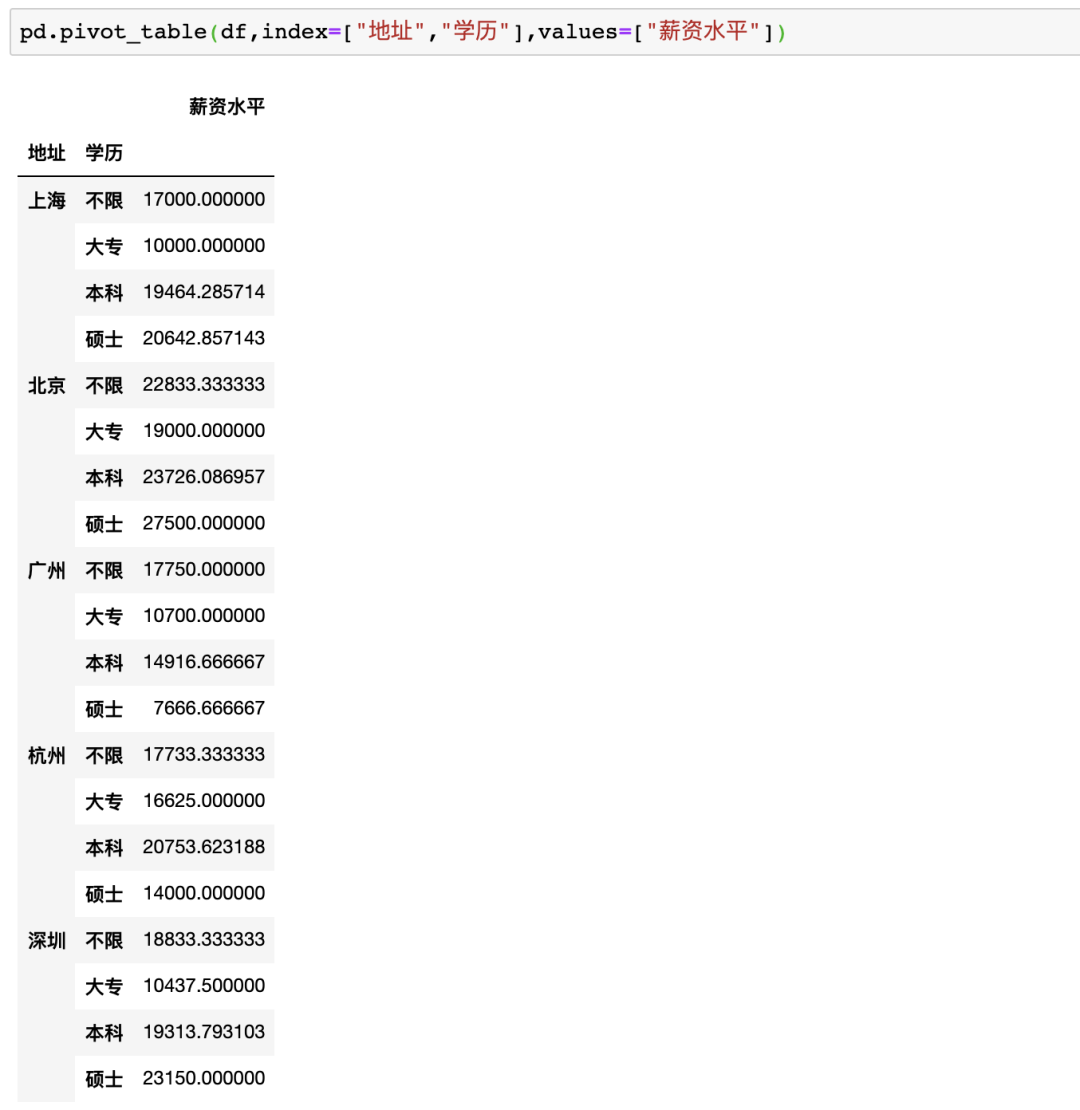
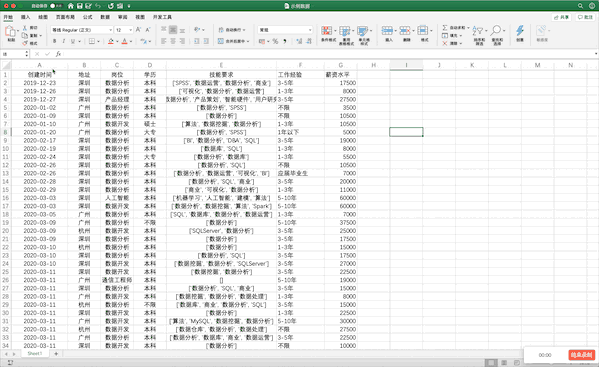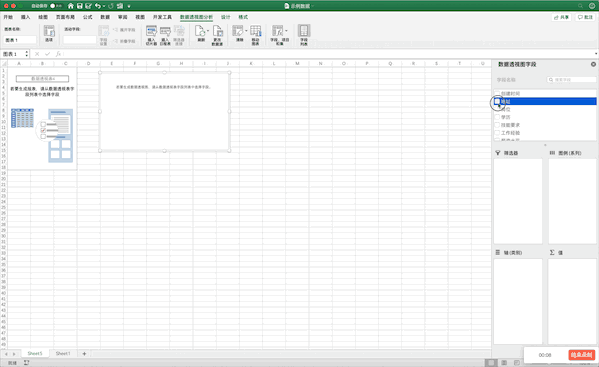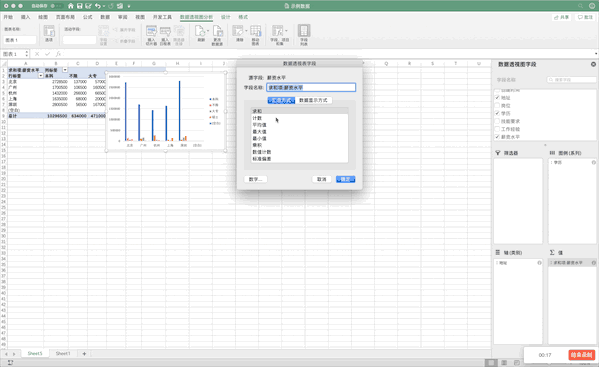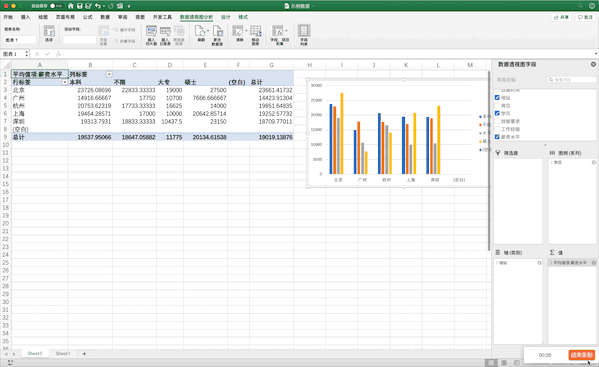 在Pandas中制作数据透视表可以使用pivot_table函数,例如制作地址、学历、薪资的透视表pd.pivot_table(df,index=["地址","学历"],values=["薪资水平"]),虽然结果一样,但是并没有Excel一样方便调整与多样
在Pandas中制作数据透视表可以使用pivot_table函数,例如制作地址、学历、薪资的透视表pd.pivot_table(df,index=["地址","学历"],values=["薪资水平"]),虽然结果一样,但是并没有Excel一样方便调整与多样
vlookup
vlookup号称是Excel里的神器之一,用途很广泛,你会几种? 案例一 问题:A3:B7单元格区域为字母等级查询表,表示60分以下为E级、60~69分为D级、70~79分为C级、80~89分为B级、90分以上为A级。D:G列为初二年级1班语文测验成绩表,如何根据语文成绩返回其字母等级?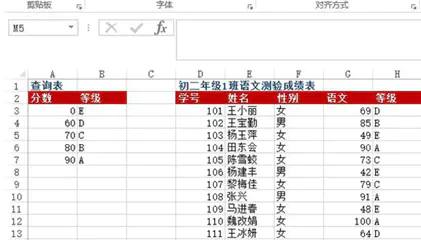
df = pd.read_excel("test.xlsx", sheet_name=0)def grade_to_point(x): if x >= 90: return 'A' elif x >= 80: return 'B' elif x >= 70: return 'C' elif x >= 60: return 'D' else: return 'E'df['等级'] = df['语文'].apply(grade_to_point)dfOut[]: 学号 姓名 性别 语文 等级0 101 王小丽 女 69 D1 102 王宝勤 男 85 B2 103 杨玉萍 女 49 E3 104 田东会 女 90 A4 105 陈雪蛟 女 73 C5 106 杨建丰 男 42 E6 107 黎梅佳 女 79 C7 108 张兴 男 91 A8 109 马进春 女 48 E9 110 魏改娟 女 100 A10 111 王冰研 女 64 D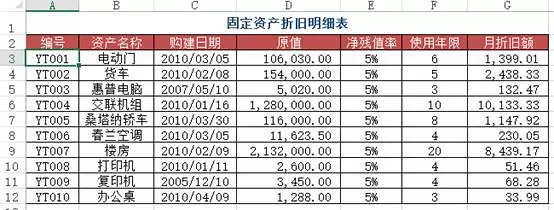

df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')Out[]: 编号 资产名称 月折旧额0 YT001 电动门 13991 YT005 桑塔纳轿车 11472 YT008 打印机 51

df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表') df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表df3['月折旧额'] = 0for i in range(len(df3['资产名称'])): df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']df3Out[]: 资产名称 月折旧额0 电动 13991 货车 24382 惠普 1323 交联 101334 桑塔纳 11475 春兰 230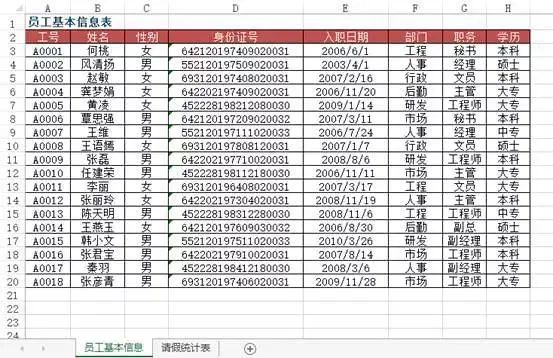
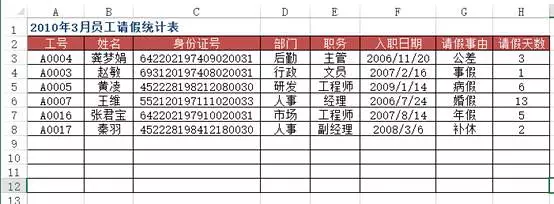
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')Out[]: 工号 姓名 部门 职务 入职日期0 A0004 龚梦娟 后勤 主管 2006-11-201 A0003 赵敏 行政 文员 2007-02-162 A0005 黄凌 研发 工程师 2009-01-143 A0007 王维 人事 经理 2006-07-244 A0016 张君宝 市场 工程师 2007-08-145 A0017 秦羽 人事 副经理 2008-03-06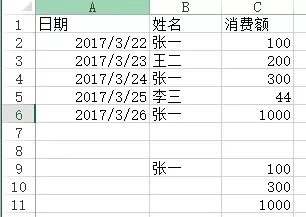
df6 = pd.read_excel("test.xlsx", sheet_name='消费额')df6[df6['姓名'] == '张一'][['姓名', '消费额']]Out[]: 姓名 消费额0 张一 1002 张一 3004 张一 1000






















 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









