







1.训练速度慢的原因
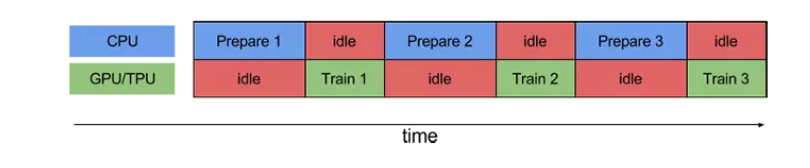
在我们训练网络的时候,是cpu先处理好数据然后送入网络中gpu进行计算,这样在cpu处理数据时非常的慢,会使得gpu有较长的空载时间。常规的训练方式如下。
2 加速方法
2.1 方法1 tf.data.prefetch()
这是可以使用tf.data.prefetch()方法,提前从数据集中取出若干数据放到内存中,这样可以使在gpu计算时,cpu通过处理数据,从而提高训练的速度。如下图所示

#手动设置
dataset = dataset.prefetch(config.batch_size).batch(config.batch_size).repeat(config.epochs)
#tensorflow自动划分
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE).batch(config.batch_size).repeat(config.epochs)
2.2 方法1 data.map()
使用data.map()函数,与data.perfecth()类似,也可以充分利用cpu的多核对数据进行预处理进行并行加速。
dataset = raw_dataset.map(_parse_example,num_parallel_calls=config.nums)
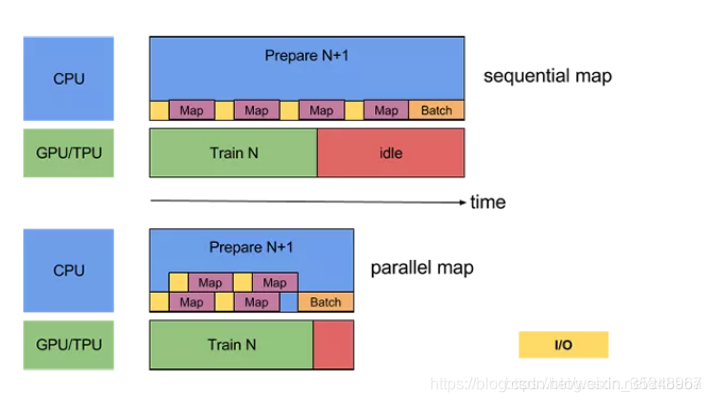
通过设置 Dataset.map() 的 num_parallel_calls 参数实现数据转换的并行化,上部分是未并行化的图示,下部分是 2 核并行的图示
当然,这里同样可以将 num_parallel_calls 设置为 tf.data.experimental.AUTOTUNE 以让 TensorFlow 自动选择合适的数值。
tensorflow官方给出了关于数据输入流水线处理方法和数据处理性能提升的方法。https://tensorflow.google.cn/guide/data_performance
3 完整代码
数据的格式为图片的字节数据 .dat文件

这里使用TFRecord处理数据,因为数据为字节型数据,所以使用struct解析数据,并将数据保存为.tfrecords格式。因为我的网络的目标有两个regression和classfication,因为两个数据的维度不一样,所以将两个数据分装成一个tensor时(iterator = tf.compat.v1.data.make_one_shot_iterator(dataset))出现错误,所以又自定义一个方法MakeData()来解析生成器中的数据,并将目标函数组成一个list为[reg,clas]。
size = config.hight * config.width * 3
def write_tfrecord(tfrecord_file,allData,trainORvalida=True):
with tf.io.TFRecordWriter(tfrecord_file) as writer:
Data = allData
print(Data.shape[0])
for i in range(Data.shape[0]):
img_filename = Data[i][0]
reg_filename = Data[i][1]
label = Data[i][2]
f = open(img_filename, 'rb') # 读取数据集图片到内存,image 为一个 Byte 类型的字符串
image = struct.unpack('f' * size, f.read(4 * size))
reg = np.loadtxt(reg_filename, delimiter=',') # 读取数据集图片到内存,image 为一个 Byte 类型的字符串
feature = { # 建立 tf.train.Feature 字典
'image': tf.train.Feature(float_list=tf.train.FloatList(value=image)), # 图片是一个 Bytes 对象
'reg': tf.train.Feature(float_list=tf.train.FloatList(value=reg.flatten())), # 图片是一个 Bytes 对象
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[int(label)])) # 标签是一个 Int 对象
}
example = tf.train.Example(features=tf.train.Features(feature=feature)) # 通过字典建立 Example
writer.write(example.SerializeToString()) # 将Example序列化并写入 TFRecord 文件
def read_tfrecode(tfrecord_file):
raw_dataset = tf.data.TFRecordDataset(tfrecord_file) # 读取 TFRecord 文件
# print(ra
feature_description = { # 定义Feature结构,告诉解码器每个Feature的类型是什么
'image': tf.io.FixedLenFeature([192,336,3], tf.float32),
'reg': tf.io.FixedLenFeature([1,54],tf.float32),
'label': tf.io.FixedLenFeature([], tf.int64),
}
def _parse_example(example_string): # 将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
feature_dict = tf.io.parse_single_example(example_string, feature_description)
# feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码JPEG图片
label = tf.one_hot(feature_dict['label'], config.classNum)
return feature_dict['image'], feature_dict['reg'], label
# dataset.prefetch()
dataset = raw_dataset.map(_parse_example,num_parallel_calls=config.nums)
# dataset = dataset.shuffle(buffer_size=10000)
dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
dataset = dataset.prefetch(config.batch_size).batch(config.batch_size).repeat(config.epochs)
iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
return iterator
def MakeData(dataset):
while 1:
# for data in list(dataset.as_numpy_iterator()):
data = dataset.get_next()
img = data[0]
reg = data[1]
label = data[2]
yield np.array(img),[np.array(reg),np.array(label)]
def MakeValidation():
raw_dataset = tf.data.TFRecordDataset(config.validation_tfrecord_file) # 读取 TFRecord 文件
feature_description = { # 定义Feature结构,告诉解码器每个Feature的类型是什么
'image': tf.io.FixedLenFeature([192,336,3], tf.float32),
'reg': tf.io.FixedLenFeature([1,54],tf.float32),
'label': tf.io.FixedLenFeature([], tf.int64),
}
def _parse_example(example_string): # 将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
feature_dict = tf.io.parse_single_example(example_string, feature_description)
feature_dict['image'] = tf.image.convert_image_dtype(feature_dict['image'],dtype=tf.uint8)
# feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码JPEG图片
label = tf.one_hot(feature_dict['label'], config.classNum)
# return tf.reshape(feature_dict['image'],[config.hight,config.width,3]),feature_dict['reg'],label
return feature_dict['image'], feature_dict['reg'], label
dataset = raw_dataset.map(_parse_example)
iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
validation_x = np.array([data[0] for data in list(dataset.as_numpy_iterator())])
validation_y_reg = np.array([data[1] for data in list(dataset.as_numpy_iterator())])
validation_label = np.array([data[2] for data in list(dataset.as_numpy_iterator())])
return validation_x,validation_y_reg,validation_label
if __name__ == '__main__':
from DataProcess.ImageProcess import splitDataTrainValidation
_,validationData = splitDataTrainValidation()
trainData = np.loadtxt(config.train,delimiter=',',dtype=np.str)
#
write_tfrecord(config.train_tfrecord_file,trainData)
write_tfrecord(config.validation_tfrecord_file, validationData)
validation_x,validation_label,validation_clas = MakeValidation()
#
dataset = read_tfrecode(config.train_tfrecord_file)
for x,y in MakeData(dataset):
print(x.shape,y[0].shape,y[1].shape)
4 总结
这是第一次写博客,写的可能不好。使用data.perfectch和TFRecord使网络训练变快了。下次更新使用tf.data.Dataset.from_generator处理数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









