






某大师曾说过,像了解自己的老婆 一样了解自己管理的数据库,个人认为包含了两个方面的了解:
1,在稳定性层面来说,更多的是关注高可用、读写分离、负载均衡,灾备管理等等high level层面的措施(就好比要保证生活的稳定性)
2,在实例级别的来说,需要关注内存、IO、网络,热点表,热点索引,top sql,死锁,阻塞,历史上执行异常的SQL(好比生活品质细节)MySQL的performance_data库和sys库提供了非常丰富的系统日志数据,可以帮助我们更好地了解非常细节的,这里简单地列举出来了一些常用的数据。
sys库是以较为可读化的方式封装了performance_data中的某些表,因此这些个数据来源还是performance_data库中的数据。
这里粗略列举出个人常用的一些系统数据,可以在实例级别更加清楚地了解MySQL的运行过程中资源分配情况。
Status中的信息
MySQL的status变量只是给出了一个总的信息,从status变量上无法得知详细资源的消耗,比如IO或者内存的热点在哪里,库、表的热点在哪里,如果想要知道具体的明细信息就需要系统库中的数据。
前提要开启performance_schema,因为sys库的视图是基于performance_schema的库的。
内存使用:
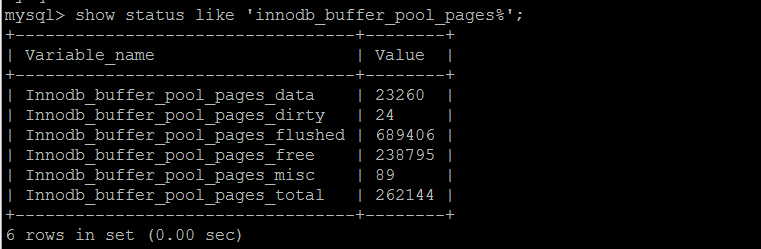
内存/innodb_buffer_pool使用
概要innodb_buffer_pool的使用情况summary,已知当前实例262144*16/1024 = 4096MB buffer pool,已使用23260*16/1024 363MB
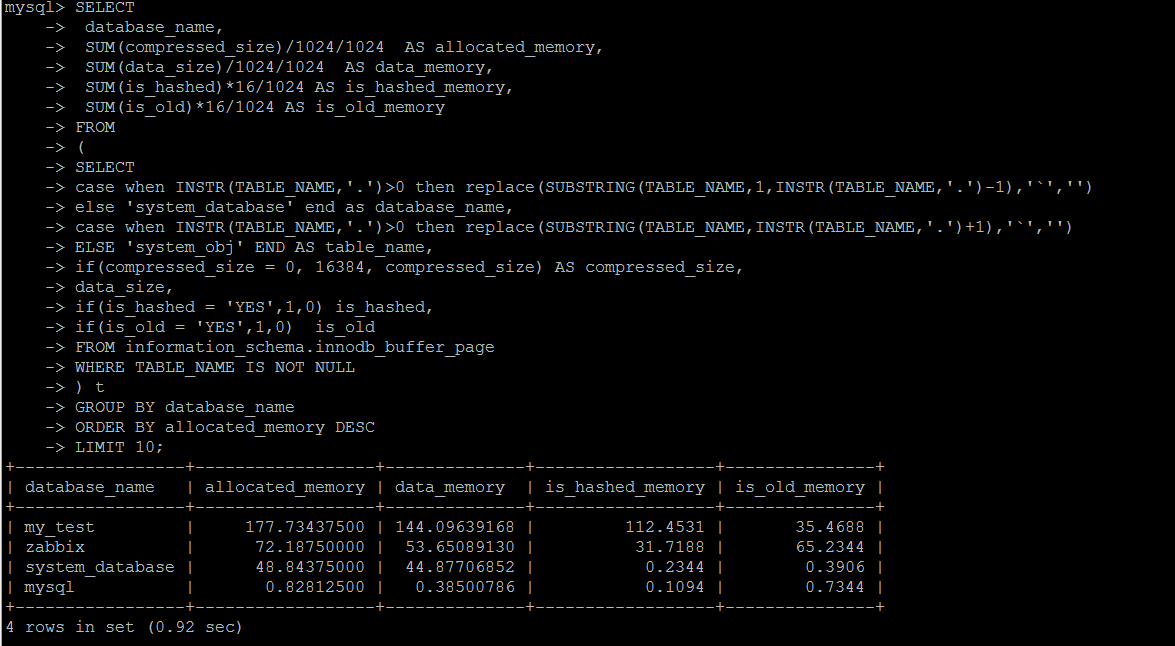
innodb_buffer_pool已占用内存的明细信息,可以按照库\表的维度来统计
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ;
SELECT
database_name,
SUM(compressed_size)/1024/1024 AS allocated_memory,
SUM(data_size)/1024/1024 AS data_memory,
SUM(is_hashed)*16/1024 AS is_hashed_memory,
SUM(is_old)*16/1024 AS is_old_memory
FROM
(
SELECT
case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,1,INSTR(TABLE_NAME,'.')-1),'`','')
else 'system_database' end as database_name,
case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,INSTR(TABLE_NAME,'.')+1),'`','')
ELSE 'system_obj' END AS table_name,
if(compressed_size = 0, 16384, compressed_size) AS compressed_size,
data_size,
if(is_hashed = 'YES',1,0) is_hashed,
if(is_old = 'YES',1,0) is_old
FROM information_schema.innodb_buffer_page
WHERE TABLE_NAME IS NOT NULL
) t
GROUP BY database_name
ORDER BY allocated_memory DESC
LIMIT 10;
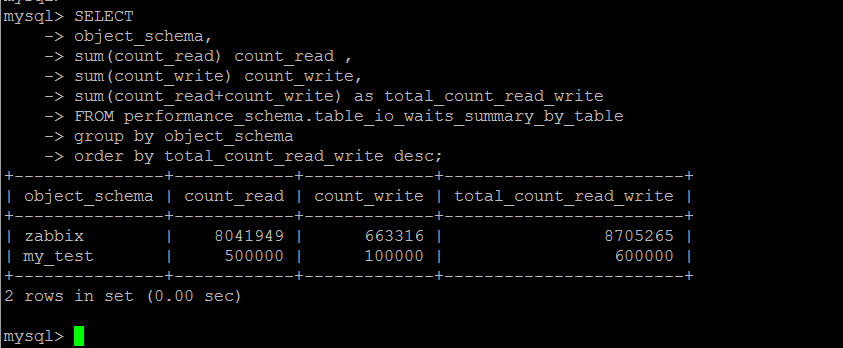
库\表的读写统计,逻辑层面的热点数据统计
目标表是performance_schema.table_io_waits_summary_by_table,某些文章上说是逻辑IO,其实这里跟逻辑IO并无关系,这个表中的字段含义是基于表,读写的到的行数的统计。至于真正的逻辑IO层面的统计,笔者目前还有不知道有哪个可用的系统表来查询。这个库可以很清楚地看到这个表中的统计结果是怎么计算出来的。
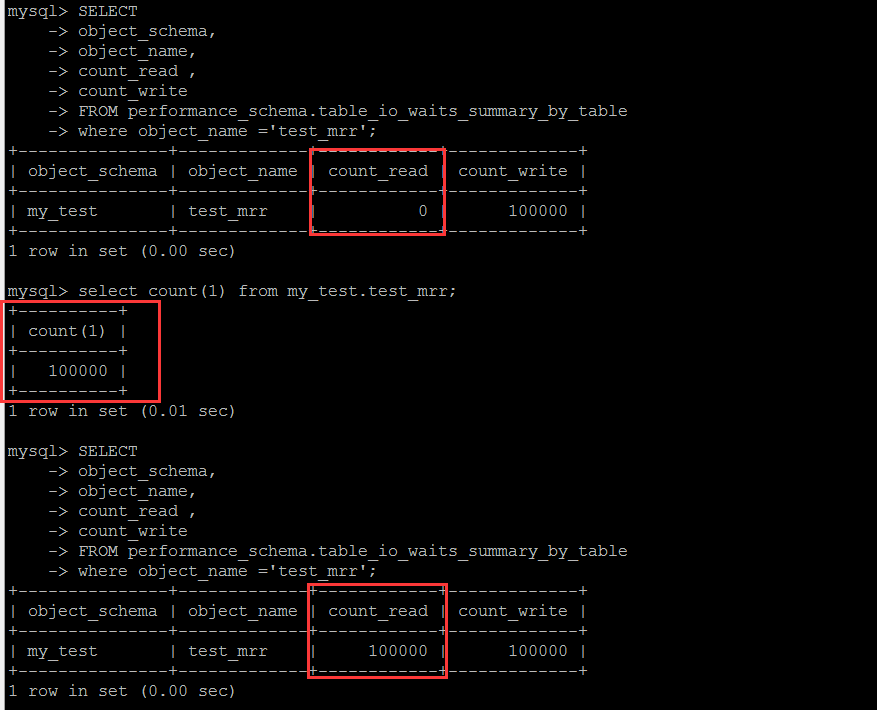
基于表的读写的行的次数统计,这是一个累计值,单纯的看这个值本身,个人觉得意义不大,需要定时收集计算差值,才具备参考意义。
以下按照库级别统计表的读写情况。
库\表的读写统计,物理IO层面的热点数据统计
按照物理IO的维度统计热点数据,哪些库\表消耗了多少物理IO。这里原始系统表中的数据是一个累计统计的值,最极端的情况就是一个表为0行,却存在大量的物理读写IO。
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ;
SELECT
database_name,
IFNULL(cast(sum(total_read) as signed),0) AS total_read,
IFNULL(cast(sum(total_written) as signed),0) AS total_written,
IFNULL(cast(sum(total) AS SIGNED),0) AS total_read_written
FROM
(
SELECT
substring(REPLACE(file, '@@datadir/', ''),1,instr(REPLACE(file, '@@datadir/', ''),'/')-1) AS database_name,
count_read,
case
when instr(total_read,'KiB')>0 then replace(total_read,'KiB','')/1024
when instr(total_read,'MiB')>0 then replace(total_read,'MiB','')/1024
when instr(total_read,'GiB')>0 then replace(total_read,'GiB','')*1024
END AS total_read,
case
when instr(total_written,'KiB')>0 then replace(total_written,'KiB','')/1024
when instr(total_written,'MiB')>0 then replace(total_written,'MiB','')
when instr(total_written,'GiB')>0 then replace(total_written,'GiB','')*1024
END AS total_written,
case
when instr(total,'KiB')>0 then replace(total,'KiB','')/1024
when instr(total,'MiB')>0 then replace(total,'MiB','')
when instr(total,'GiB')>0 then replace(total,'GiB','')*1024
END AS total
from sys.io_global_by_file_by_bytes
WHERE FILE LIKE '%@@datadir%' AND instr(REPLACE(file, '@@datadir/', ''),'/')>0
)t
GROUP BY database_name
ORDER BY total_read_written DESC;
ps:个人不太喜欢MySQL自定义的format_***函数,这个函数的初衷是好的,把一些数据(时间,存储空间)等格式化成更加可读的模式。但是却不支持单位的参数,更多的时候想以某个固定的单位来显示,比如格式化一个的时间,格式化后根据单位大小可能会显示微妙,或者是毫秒,或者是秒,或者分钟,或者天。比如想把时间统一格式化成秒,对不起,不支持,某些个数据不仅仅是看一眼那么简单,甚至是要读出来存档分析的,因此这里不建议也不会使用那些个format函数
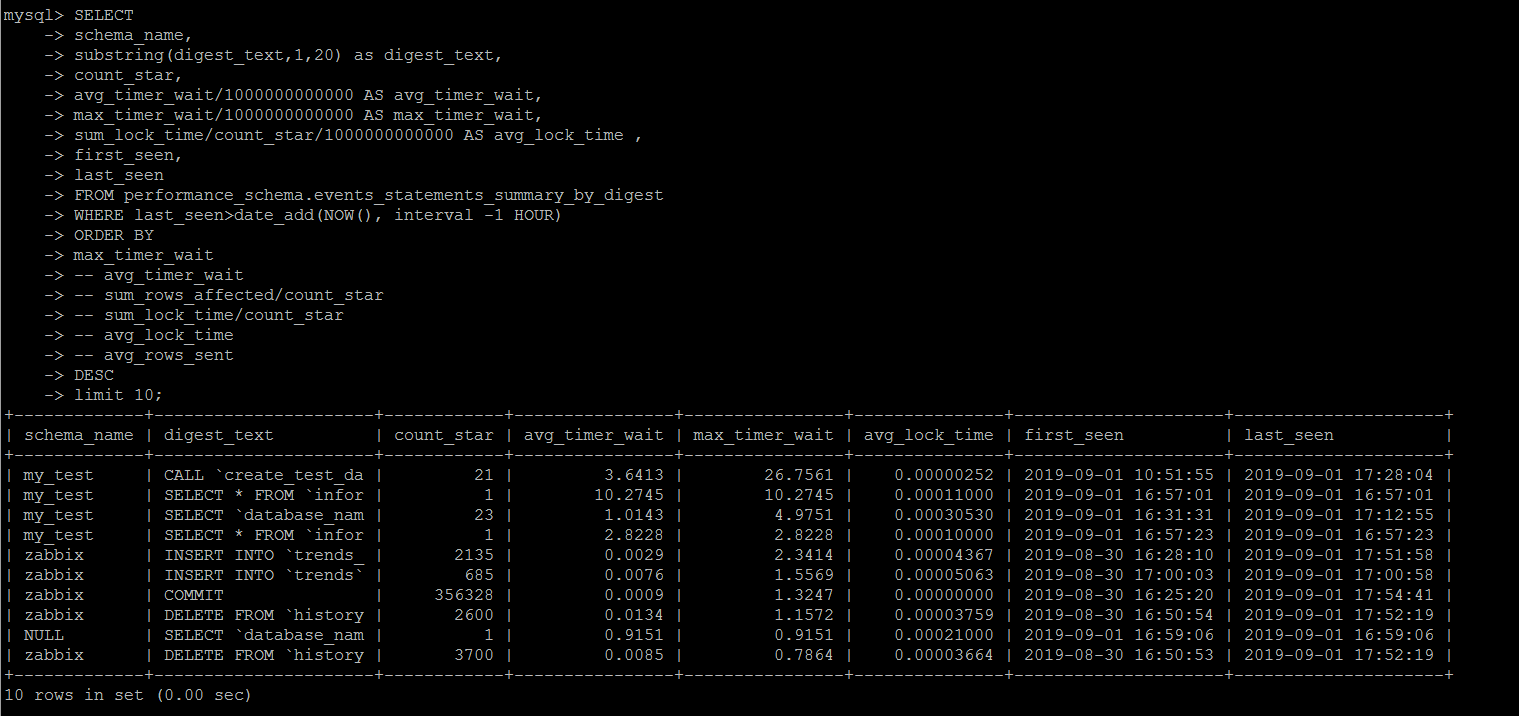
TOP SQL 统计
可以按照执行时间,阻塞时间,返回行数等等维度统计top sql。
另外可以按照时间筛选last_seen,可以统计最近某一段时间出现过的top sql
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ;
SELECT
schema_name,
digest_text,
count_star,
avg_timer_wait/1000000000000 AS avg_timer_wait,
max_timer_wait/1000000000000 AS max_timer_wait,
sum_lock_time/count_star/1000000000000 AS avg_lock_time ,
sum_rows_affected/count_star AS avg_rows_affected,
sum_rows_sent/count_star AS avg_rows_sent ,
sum_rows_examined/count_star AS avg_rows_examined,
sum_created_tmp_disk_tables/count_star AS avg_create_tmp_disk_tables,
sum_created_tmp_tables/count_star AS avg_create_tmp_tables,
sum_select_full_join/count_star AS avg_select_full_join,
sum_select_full_range_join/count_star AS avg_select_full_range_join,
sum_select_range/count_star AS avg_select_range,
sum_select_range_check/count_star AS avg_select_range,
first_seen,
last_seen
FROM performance_schema.events_statements_summary_by_digest
WHERE last_seen>date_add(NOW(), interval -1 HOUR)
ORDER BY
max_timer_wait
-- avg_timer_wait
-- sum_rows_affected/count_star
-- sum_lock_time/count_star
-- avg_lock_time
-- avg_rows_sent
DESC
limit 10;
需要注意的是,这个统计是按照MySQL执行一个事务消耗的资源做统计的,而不是一个语句,笔者一开始懵逼了一阵子,举个简单的例子。
参考如下,这里是循环写个数据的一个存储过程,调用方式就是call create_test_data(N),写入N条测试数据。
比如call create_test_data(1000000)就是写入100W的测试数据,这个执行过程耗费了几分钟的时间,按照笔者的测试实例情况,avg_timer_wait的维度,绝对是一个TOP SQL。
但是在查询的时候,始终没有发现这个存储过程的调用被列为TOP SQL,后面尝试在存储过程内部加了一个事物,然后就顺利地收集到了整个TOP SQL.
因此说performance_schema.events_statements_summary_by_digest里面的统计,是基于事务的,而不是某一个批处理的执行时间的。
CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`(
IN `loopcnt` INT
)
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT ''
BEGIN
-- START TRANSACTION;
while loopcnt>0 do
insert into test_mrr(rand_id,create_date) values (RAND()*100000000,now(6));
set loopcnt=loopcnt-1;
end while;
-- commit;
END
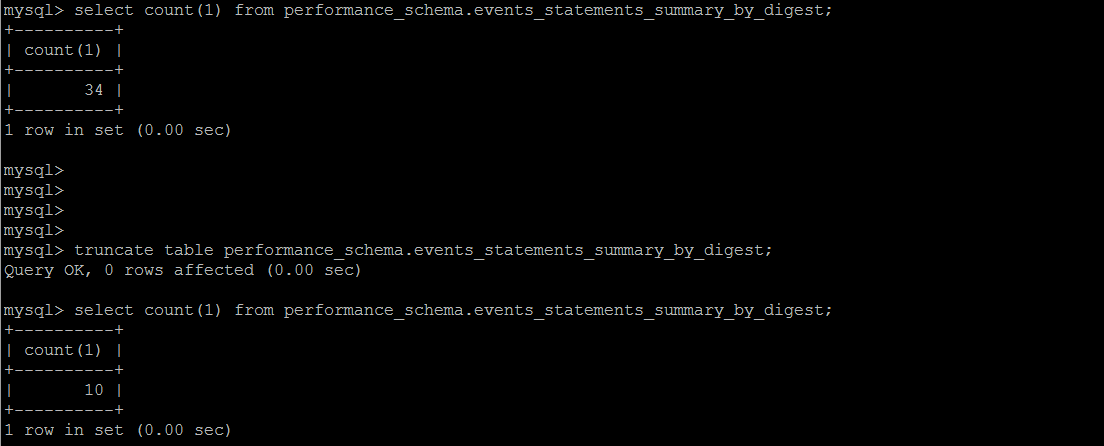
另外一点比较有意思的是,这个系统表是为数不多的支持truncate的,当然它在内部,也是在不断收集的一个过程。
执行失败的SQL 统计
一直以为系统不会记录执行失败的\解析错误的SQL,比如想统计因为超时而执行失败的语句,后面才发现,这些信息,MySQL会完整地记录下来
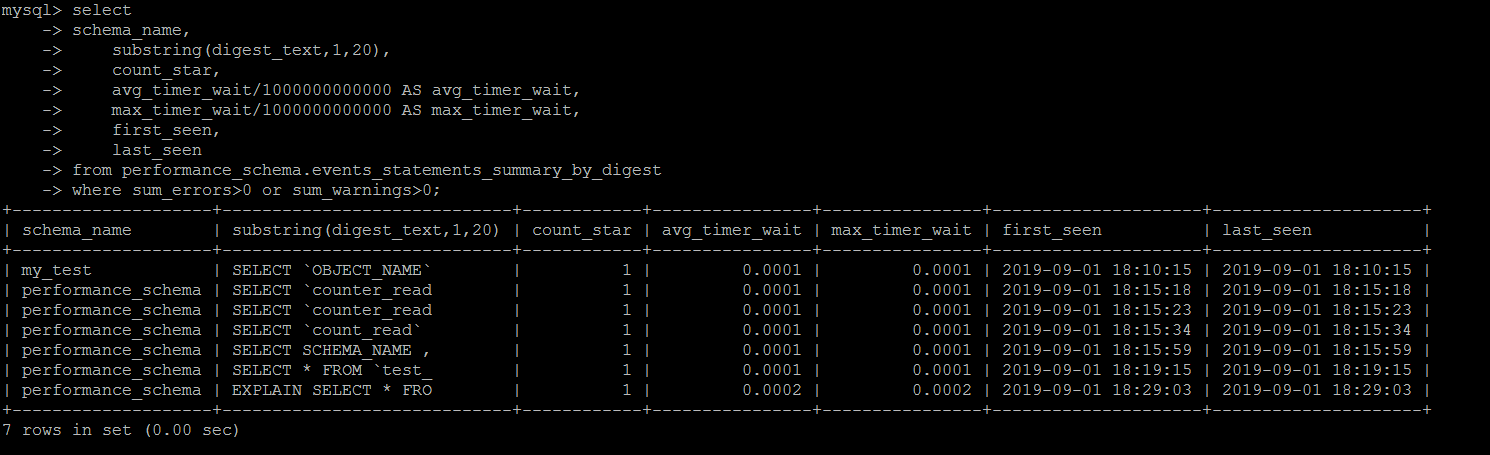
这里会详细记录执行错误的语句,包括最终执行失败(超时之类的),语法错误,执行过程中产生了警告之类的语句。用sum_errors>0 or sum_warnings>0去performance_schema.events_statements_summary_by_digest筛选一下即可。
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ;
select
schema_name,
digest_text,
count_star,
first_seen,
last_seen
from performance_schema.events_statements_summary_by_digest
where sum_errors>0 or sum_warnings>0
order by last_seen desc;
Index使用情况统计
基于performance_schema.table_io_waits_summary_by_index_usage这个系统表,其统计的维度同样是“按照某个索引查询返回的行数的统计”。
可以按照哪些索引使用最多\最少等情况进行统计。

不过这个统计有一个给人潜在一个误区:
count_read,count_write,count_fetch,count_insert,count_update,count_delete统计了某个索引上使用到索引的情况下,受影响的行数,sum_timer_wait是累计在该索引上等待的时间。
如果使用到了该索引,但是没有数据受影响(就是没有DML语句的条件没有命中数据),将count_***不会统计进来,但是sum_timer_wait会统计进来
这就存在一个容易受到误导的地方,这个索引明明没有命中过很多次,但是却产生了大量的timer_wait,索引看到类似的信息,也不能贸然删除索引。
等待事件统计
MySQL数据库中的任何一个动作,都需要等待(一定的时间来完成),一共有超过1000个等待事件,分属不懂的类别,每个版本都不一样,且默认不是所有的等待事件都启用。
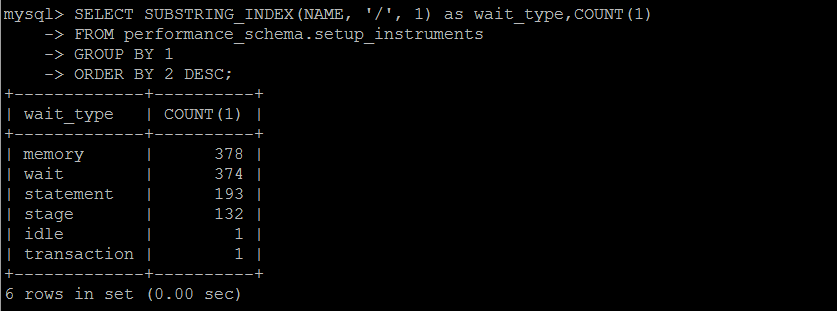
个人认为等待事件这个东西,仅做参考,不具备问题的诊断性,即便是再优化或者低负载的数据库,累计一段时间,某些事件仍旧会积累大量的等待事件。
这些事件的等待事件,不一定都是负面性的,比如事物的锁等待,是在并发执行过程中必然会生成的,这个等待事件的统计结果,也是累计的,单纯的看一个直接的值,不具备任何参考意义。
除非定期收集,做差值计算,根据实际情况,才具备参考意义。
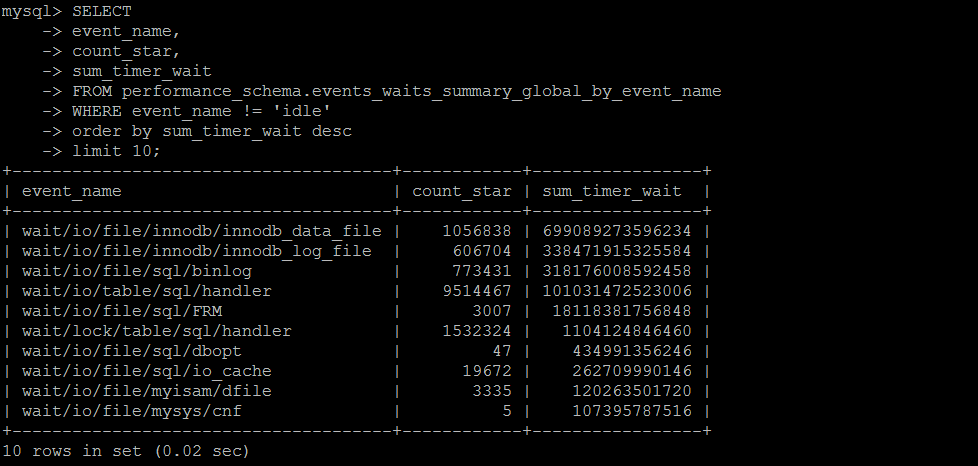
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ;
SELECT SUBSTRING_INDEX(NAME, '/', 1) as wait_type,COUNT(1)
FROM performance_schema.setup_instruments
GROUP BY 1
ORDER BY 2 DESC;
SELECT
event_name,
count_star,
sum_timer_wait
FROM performance_schema.events_waits_summary_global_by_event_name
WHERE event_name != 'idle'
order by sum_timer_wait desc
limit 100;
最后,需要注意的是,
1,MySQL提供的诸多的系统表(视图)中的数据,单纯的看这个值本身,因为它是一个累计值,个人觉得意义不大,尤其是avg_***,需要结合多方面的综合因素,做参考使用。
2,任何系统表的查询,都可能对系统性能的本身造成一定的影响,不要再对系统可能产生较大负面影响的情况下做数据的统计收集。
总结
以上所述是小编给大家介绍的利用MySQL系统数据库做性能负载诊断的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!














 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









