







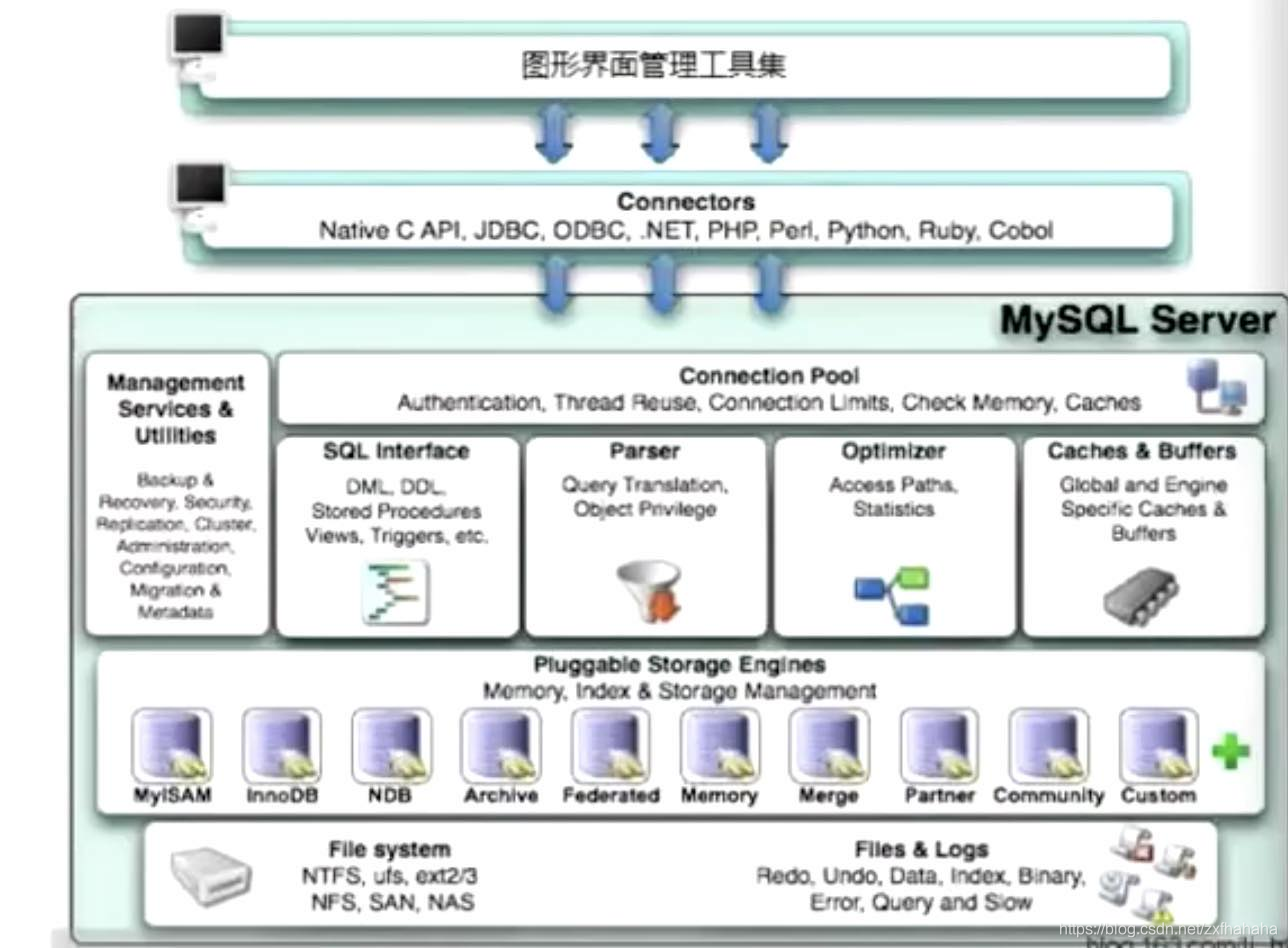
我们用JDBC 等连接MySQL 其实就是,jdbc是客户端来连接MySQL服务器。
Mysql服务器中负责对表中数据的读取和写入工作的部分是存储引擎,支持的存储引擎就是倒数第二行的innobd、memory、myisam等。
存储引擎的上一层是 处理数据的, 下一层是真的文件系统。
InnoDB
我们要讲的是innodb,它是将表中的数据存储到磁盘上的存储引擎。
InnoDB存储引擎不需要一条一条的把记录从磁盘上读出来,InnoDB采取的方式是:
将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,
InnoDB中页的大小一般为 16 KB
也就是说,当需要从磁盘中读数据时每一次最少将从磁盘中读取16KB的内容到内存中,每一次最少也会把内存中的16KB内容写到磁盘中
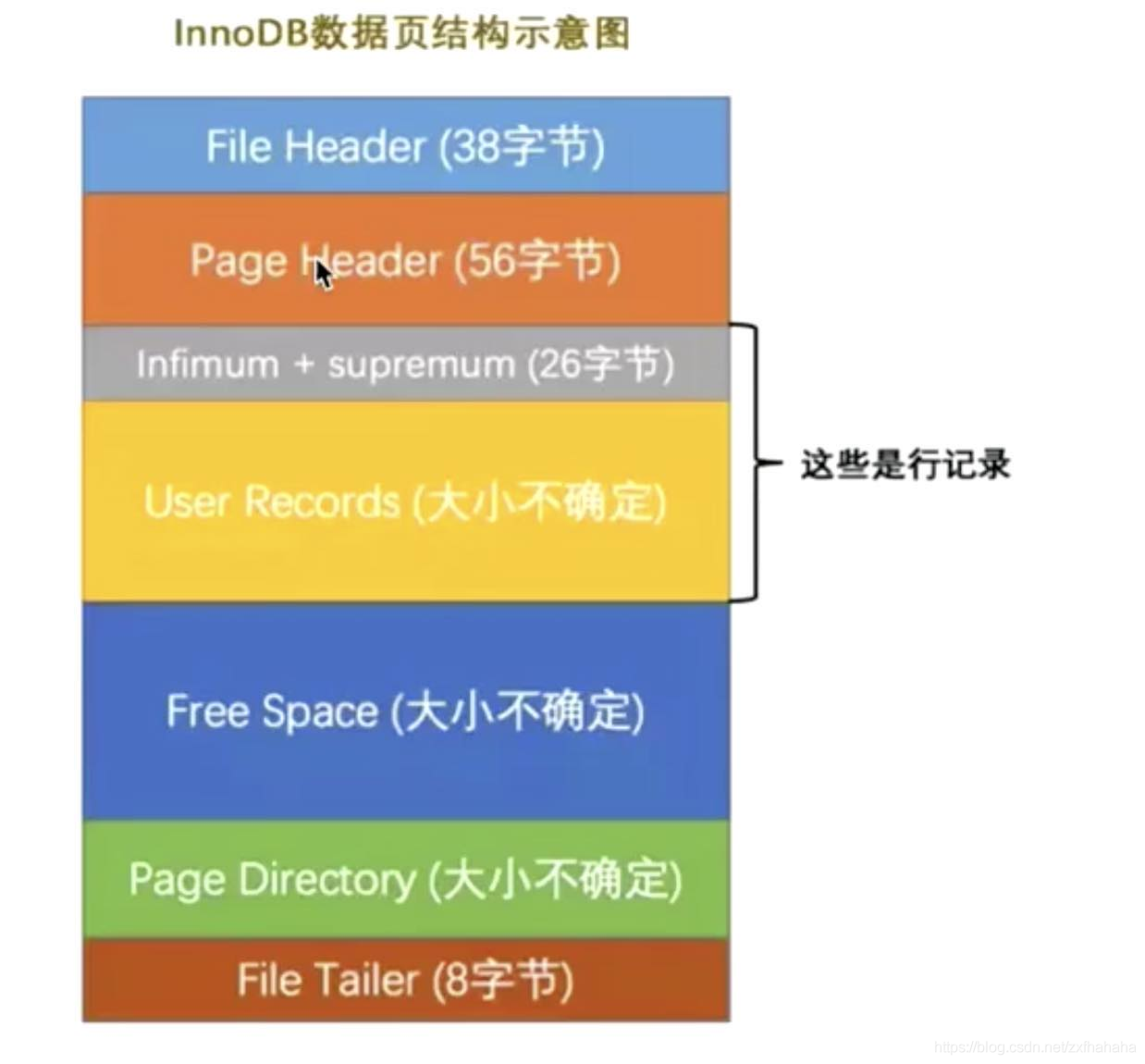
InnoDB数据页结构
每次InnoDB拿的页即数据页,为16kb,这16kb大小的存储空间可以被划分为多个部分,示意图如下:
名称
中文名
占用空间
简单描述</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2174
2174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









