







架构-1:高性能架构之读写分离和分表分库
架构-2:高性能架构之NoSQL和缓存
架构-3:高性能架构之单机高性能和负载均衡
架构-4:高可用架构之存储高可用
架构-5:高可用架构之Paxos和Raft
架构-6:高可用架构之一致性哈希算法和数据分片
架构-7.高可用架构之接口级故障
单机高性能
PPC和TPC
- PPC
PPC是指,当有新连接进来时,创建一个进程取处理,创建一个进程的代价是非常高的,需要分配很多的内核资源,且进程之间的通信也很昂贵,所以一般只有连接数比较少的会使用(如数据库服务器),而普通的业务服务器是不会使用的。 - TPC
PPC与TPC的区别在于,PPC在接收请求之后,会fork一个子进程(不是线程)而TPC则会创建一个子线程。
TPC进行了改良,创建线程而不是进程,在tomcat早期的版本,使用的就是TPC。然而随着业务的发展,TPC依然不能满足高访问量的要求。一个原因是:创建线程依然非常昂贵,如jvm中创建线程是通过内核创建的,内核可以说是另外一个进程,进程间的通信很昂贵,必须要把用户空间的数据复制到内核空间,另一方面内核还会对用户的访问代码进行检查,防止非法的访问。
即使使用了线程池,线程的切换也会很大的性能消耗,线程的切换需要内核空间和用户空间的数据交换,需要保存现场数据(寄存器里的数据)和还原现场(把保存的寄存器数据还原),而且线程数量都有上限,因为每个线程都会占用资源。
IO多路复用
单机的性能瓶颈几乎都是在I/O(I/O包括磁盘I/O和网络I/O),为什么,我们来对比下速度。CPU执行一条指令的时间是0.38ns(主频2.6G的CPU),如果把这个时间看成基本单位1秒,那么从磁盘中读取1MB连续数据需要20ms,换算成0.38ns=1秒,20ms约等于20个月。也就是对于阻塞的I/O(即线程在遇到访问I/O的命令时,会进行等待),大部分CPU时间时耗费在等待I/O上。
于是乎,有了I/O多路复用,其原理是:系统会为每一个I/O事件提供一个标志。而我们只需要一个主线程不停的查询所有的标志,当I/O事件准备就绪的时候,才去创建新的线程去执行非I/O的快速命令,极大的释放了CPU的性能。
三种I/O多路复用
select(不要跟sql的select搞混了)
select是最基础的I/O多路复用,select保存了一个fd_set的数据结构,实际上是一个long类型的数组,每一个数组元素对应一个文件描述符。所谓文件描述符即是上文所讲的系统提供的标志,通过访问这个标志即可知道对应的I/O的状态。由于这是一个数组,所以是固定长度的,固定长度为1024.所以Select能监视的最大I/O事件是1024个。
#include <sys/select.h>
#define FD_SETSIZE 1024
#define NFDBITS (8 * sizeof(unsigned long))
#define __FDSET_LONGS (FD_SETSIZE/NFDBITS)
typedef struct {
unsigned long fds_bits[__FDSET_LONGS];//定义的数组
} fd_set;
void FD_SET(int fd, fd_set *fdset) //将fd添加到fdset
void FD_CLR(int fd, fd_set *fdset) //从fdset中删除fd
void FD_ISSET(int fd, fd_set *fdset) //判断fd是否已存在fdset
void FD_ZERO(fd_set *fdset) //初始化fdset内容全为0
select执行过程
- 从用户空间把fd_set拷贝到内核空间
- 执行do_select方法,是一个无限的for循环
- 该方法会遍历fd_set,
- 并调用每个元素对应的poll函数,这个poll区别于下面即将提到的poll,该函数把当前线程挂载到对应的设备(I/O操作的设备)的等待队列下,poll函数还会返回I/O执行结果
- 把I/O的结果更新到fd_set中
- 如果存在文件符号被更新,那么跳出循环
- 如果文件符号没有没有被更新,那么会无限循环,直到超时进入休眠,上面调用poll方法的作用就是,当文件描述符发生变化时,唤醒所有等待队列的线程,当前线程又被唤醒,于是当前函数又会被执行一次。
- 把fd_set从内核空间拷贝到用户空间
select的问题
- 最大限制监视文件符个数为1024
- 每次select需要从用户空间和内核空间进行两次拷贝
- 遍历fd_set,时间复杂度为O(n)
poll
poll与select差不多,唯一的区别在于poll使用链表实现,而是没有1024的长度限制。
epoll
epoll是对select/poll的优化版本,epoll有以下好处
- 1.不用每次操作都拷贝文件描述符,只在首次从用户空间拷贝到内核空间,在准备就绪时从内核空间拷贝到用户空间。
- 2.通过回调函数加载到就绪链,不用遍历整个文件描述符
- 3.无长度限制
- 4.使用红黑树存放文件描述符,提高查询的效率
那么是怎么做到的呢?
- 首先, 把文件描述符从用户空间拷贝到内核空间,仅这一次,不用每次调用都拷贝。
- 文件描述符使用了红黑树来存储,这样提高了查询的效率。
- 接着,还是遍历文件描述符,并调用对应的poll方法,但是挂载的不是当前线程,而是一个回调函数。
- 当设备执行完I/O操作后,唤醒等待队列调用回调函数。
- 回调函数会把已经就绪的文件描述符写入到一个就绪链中。
- 把就绪链拷贝到用户空间(只有就绪的会被拷贝,也就是每个文件操作符只会被拷贝一次,加上拷贝进内核空间,合计两次)。
负载均衡
上文聊的是单机高性能,那么多机高性能就不得不提到负载均衡了。通过负载均衡,可以把流量分流到不同的服务器,以降低每一个服务器的压力。
- Nginx
Nginx是比较常用的负载均衡中间件,Nginx是七成负载,所谓七层负载就是在网络的七层模型中的应用层进行负载,也就是必须跟客户端建立TCP连接后,才可以对请求进行转发。因此,Nginx更像一个代理服务器。一般的Linux服务器装一个Nginx大概能到5万每秒。但是其分流策略比较灵活,不仅能基于IP和Port,还能针对域名,目录结构等进行分流。- Nginx负载均衡算法
- 轮询,无差别轮询,不关注运行状态,但是如果对应的服务器故障,还是会发给下一台服务器
- 加权轮询,可以对性能比较高的服务器加权,让更多的请求到达高性能的服务器
- 负载最低优先,根据请求数或者连接数来判断那一台服务器最闲,给闲的服务器发送请求
- 性能最优,分配给处理最快的服务器,通过响应速度进行判断
- Hash类,根据Hash运行,可以把Hash值一样的分配到同一台服务器,如同一个用户一直访问同一台服务器。
- Nginx负载均衡算法
7.应用层
6.表示层
5.会话层
4.传输层
3.网络层
2.数据链路层
1.物理层(硬件)
-
LVS
LVS是四层负载,也就是在传输层就进行了请求转发,并不需要跟客户端建立TCP连接,服务器跟客户端时直接建立TCP连接的,因此,性能要比Nginx高。据说能够达到80万每秒。但是仅能基于IP和Port进行数据分流。 -
F5
Nginx和LVS都是软件负载均衡,而F5则是硬件负载,当然其性能就非常高了,从200万/秒到800万/秒都有。但是价格就非常高了,一台F5十来万到上百万都有。 -
DNS
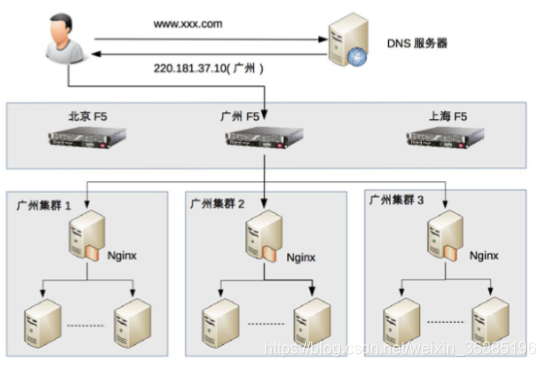
DNS是最简单的负载均衡,一般来实现地理级别的均衡,如北京的用户访问北京的机房,而深圳的用户访问深圳的机房。DNS的本质就是解析同一个域名可以返回不同的IP地址。DNS的缺点是,更新缓慢,因此只做比较固定的地理级别的均衡。
组合的原则为,DNS用于地理级别的负载均衡,F5用于每个地区的总负载(如果需要的话),Nginx负责机器级别的负载均衡。
一般的负载均衡架构图














 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









