









算法的发展脉络很重要, 它能让你知道后面出现新的算法是解决了前面算法的什么问题, 要将机器学习优化算法当作一部电影来记忆, 具有起承转合, 而不是一页一页的幻灯片.
三、对机器学习训练的优化算法的了解, 和SGD比怎么体现优化的?
我提到了Adam、RMSprop、还有动量的优化算法, 继续问我,是如何实现优化的?
这里介绍Momentum、AdaGrad、RMSprop、Adam四种优化算法.
优化思路总结:即将介绍的几个优化算法, 其核心思想都是想改变b轴的摆动幅度, 加快W轴的参数收敛速度.采取的方式本质来看是对学习率的改变.
3.0 指数移动加权平均数
公式:
v
t
=
β
v
t
−
1
+
(
1
−
β
)
θ
t
v_t=\beta v_{t-1}+(1-\beta)\theta _t
vt=βvt−1+(1−β)θt
v
t
v_t
vt指当前变量取值,
v
t
−
1
v_{t-1}
vt−1指前一时刻变量取值,
θ
t
\theta _t
θt表示当前变量的实际值,
β
\beta
β是“平均跨度”(自己定义的),决定去过去多少状态值相关.
详细说明参考(吴恩达《deep Learning》2.3指数加权平均数Exponentially weighted averages)
⚠️注意
β
\beta
β取值: 平均状态取值范围 =
1
/
(
1
−
β
)
1/(1-\beta)
1/(1−β),
β
\beta
β取值范围在[0,1)之间, 等于0时, 表示直接取当前值.
β
\beta
β=0.9, 平均了过去10个状态值,
β
\beta
β=0.95, 平均了过去20个状态值. (以天气的移动平均取值为例)

会有一个问题, 平均过去10天的气温, 那对于一开始的数据(没有过去10天, 第一天初始值为0)怎么取值? 这里涉及到一个“修正偏差”的概念, 但是这在实际应用中可以不做考虑, 因为随着训练迭代次数的增加, 后期的变化趋势会与预期的变化趋势相同.
如果想进一步对“修正偏差”的概念有所了解, 建议参考, 李沐先生的《手动学习深度学习》优化算法一节.(Adam算法是进行了‘偏差修正的’)
提出指数(移动)加权平均数的意义在于:
(1) 它使得变量的分布,变量的变化趋势更加平滑和平稳. 相当于对随着时间变化的变量的散点图拟合出一条平滑的近似曲线, 使变化规律更加明显, 消除噪声数据.
(2) 它占用极少内存,电脑内存中只占用一行数字而已,然后把最新数据代入公式,不断覆盖就可以了. 以天气移动平均取值为例, 如果你要计算移动窗,你直接算出过去10天的总和,过去50天的总和,除以10和50就好,如此往往会得到更好的估测。但缺点是,如果保存所有最近的温度数据,和过去10天的总和,必须占用更多的内存,执行更加复杂,计算成本也更加高昂。
3.1 Momentum动量法
mini-batch梯度下降法主要存在的问题是, 每一批次的权重更新都只根据当前批次的梯度变化,
w
t
=
w
t
−
1
−
α
∇
F
(
w
)
w_t=w_{t-1}-\alpha\nabla F(w)
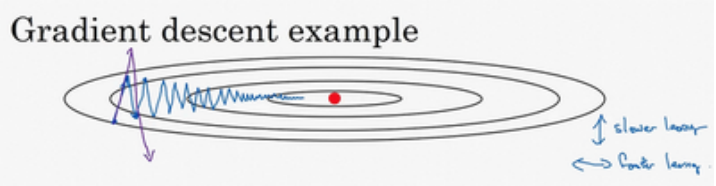
wt=wt−1−α∇F(w), 使得梯度下降的过程中沿着垂直于待更新参数的摆动幅度大, 甚至可能脱离函数规范区域. 这时得选择一个比较小的学习率, 这使得参数收敛的速度慢.基于此问题提出了动量法.
动量法公式:
v
d
w
=
β
v
d
w
+
(
1
−
β
)
d
W
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(
1
)
v_{dw}=\beta v_{dw}+(1-\beta)dW ..............(1)
vdw=βvdw+(1−β)dW..............(1)
v
d
b
=
β
v
d
b
+
(
1
−
β
)
d
b
.
.
.
.
.
.
.
.
.
.
.
.
.
(
2
)
v_{db}=\beta v_{db}+(1-\beta)db.............(2)
vdb=βvdb+(1−β)db.............(2)
w
t
=
w
t
−
1
−
α
v
d
w
.
.
.
.
.
.
.
.
.
.
.
.
(
3
)
w_t=w_{t-1}-\alpha v_{dw}............(3)
wt=wt−1−αvdw............(3)
b
t
=
b
t
−
1
−
α
v
d
b
.
.
.
.
.
.
.
.
.
.
.
(
4
)
b_t = b_{t-1}-\alpha v_{db}...........(4)
bt=bt−1−αvdb...........(4)
β
\beta
β=0.9是不错的取值, 即取当前值的前10个状态进行移动加权平均.
为什么动量法可以解决上述问题?
从上图我们可以发现, 以初始位置为0点建立平面直角坐标系, 纵轴的变化幅度是非常大的, 但是围绕横轴上下摆动, 可近似为关于横轴对称, 所以采用指数加权平均的方法后, 上下相互抵消, 会降低纵轴的摆动幅度, 而横轴方向是一直沿着参数优化方向(正半轴方向)前进的, 参照公式(1)可知, dW相当于加速度, 所以参数寻优过程中会沿着原来的运动方向有一个惯性加速度, 这使其可以越过鞍点.
但是动量法没能解决的一个mini-batch梯度下降法的遗留问题是, 所有的权重使用相同的学习率, 实际的权重更新应该是有快慢区别的, 为了适应多维度的权重变化, 应该为不同的权重更新设置差异化的学习率, 因此提出AdaGrad算法.
3.2 AdaGrad
AdaGrad算法流程图:

公式: 是流程图中标黄的两行.
黄色部分可见, AdaGrad是如何修改学习率的, (1)将梯度平方(注意这里是按元素相乘)累加;(2)累加梯度作为分母, 结果r越大, 参数更新的速度越慢, 结果r越小, 参数更新的速度越快, 从而加快训练速度. 这些按元素运算使得⽬标函数⾃变量中每个元素都分别拥有⾃⼰的学习率。
然而,由于r⼀直在累加按元素平⽅的梯度,⾃变量中每个元素的学习率在迭代过程中⼀直在降低(或不变, g为0)。所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到⼀个有⽤的解。 基于此, 提出RMSprop优化算法.
3.3 RMSprop

黄色部分可见, RMSprop相对于AdaGrad对梯度的累加方式做了修改, 采用指数加权平均的方法. 在保留后者优势的同时, 使得学习率的变化可以增加或减小.
3.4 Adam
Adam算法是结合了动量法和RMSprop方法的优点, 即平衡了b方向的摆动, 为参数优化的方向提供了动量, 又为每个学习参数分配了不同的学习率.

为什么这个算法叫做Adam?Adam代表的是Adaptive Moment Estimation,
β
1
\beta _1
β1用于计算这个微分
(
(
d
W
)
)
((dW))
((dW)),叫做第一矩,
β
2
\beta _2
β2用来计算平方数的指数加权平均数
(
(
d
w
)
2
)
((dw)^2)
((dw)2),叫做第二矩,所以Adam的名字由此而来,但是大家都简称Adam权威算法。
参考文章:
https://zhuanlan.zhihu.com/p/34230849
吴恩达《deepLearning》
李沐《动手学深度学习》
吴恩达和李沐的电子书可以私邮我.
---------------8.02更新----------------------
1 本质上,优化与深度学习的目标是有区别的:优化的目标在于降低训练误差, 而深度学习的目标在于降低泛化误差。为了降低泛化误差,除了使用优化算法降低训练误差以外,还需要注意应对过拟合。(但是我们这里讨论的是降低训练误差,不考虑过拟合的问题)
2 深度学习的优化算法按照倒数阶数划分,可分为一阶导数优化算法:SGD系列 + Momentum系列,和二阶导数优化算法:Adagrade\rmsprop\adam系列.其中 Adam是结合一阶导数和二阶导数的.
3 常见优化算法中SGD和Adam几乎能解决所有问题,但是SGD首先速度慢,精度高;Adam训练收敛速度快,精度相对较低.后来的很多优化算法(2015/16年之后)都是将SGD算法与Adam算法之间做平衡.
4 一类比较特殊的优化算法是添加Nestrov,超前一步更新梯度,既能加快收敛,又可以降低在垂直收敛方向的震荡.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









