






在前面的两篇文章中我们介绍了如何编译和部署Apache
在现实情况下,我们编写程序一般都是需要依赖外部的相关类库的,比如我们现在需要
一、我们都知道,很多类库都是可以通过Maven仓库下载到的,所以我们可以指定依赖库的group ID、artifact ID以及version来指定具体的依赖。在Zeppelin中,我们可以通过%dep Interpreter来加载依赖,如下: %dep
z.load("mysql:mysql-connector-java:5.1.35")
%dep默认就可以使用,z代表的是Zeppelin context。
如果我们觉得Maven中央仓库下载的速度比较慢,我们可以自定义Maven仓库,如下: %dep
z.addRepo("RepoName").url("RepoURL")
二、通过指定jar的本地路径来加载外部依赖,具体如下: %dep
z.load("/path/to.jar")
在使用dep需要主要的是,我们必须在初始化
上面已经加载好了Mysql驱动,现在我们需要构建连接Mysql相关的参数信息,如下: val props = scala.collection.mutable.Map[String,String]();
props+=("driver" -> "com.mysql.jdbc.Driver")
props+=("url" -> "jdbc:mysql://www.iteblog.com/scalada?user=root&password=orange123")
props+=("dbtable" -> "(select id, name, phone, email, gender from scalada.student) as students")
props+=("partitionColumn" -> "id")
props+=("lowerBound" -> "0")
props+=("upperBound" -> "100")
props+=("numPartitions" -> "2")
我们可以看出这是Spark连接Mysql的一种方式(更多的方式可以参见《Spark读取数据库(Mysql)的四种方式讲解》),然后我们可以创建DataFrame了: import scala.collection.JavaConverters._
val studentDf = sqlContext.load("jdbc", props.asJava)
studentDf.printSchema()
studentDf.show()
studentDf.registerTempTable("students")
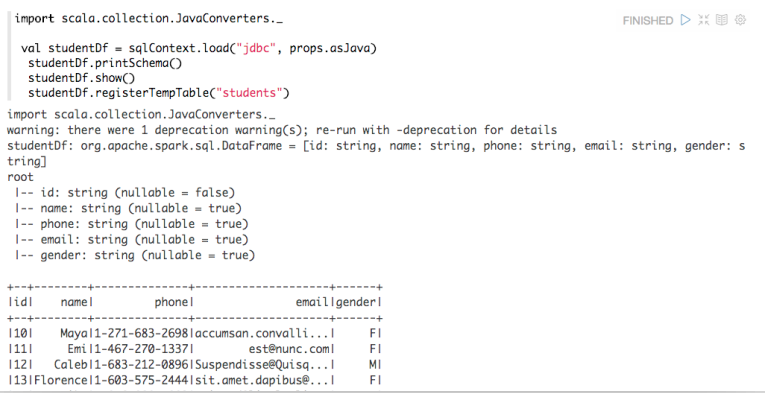
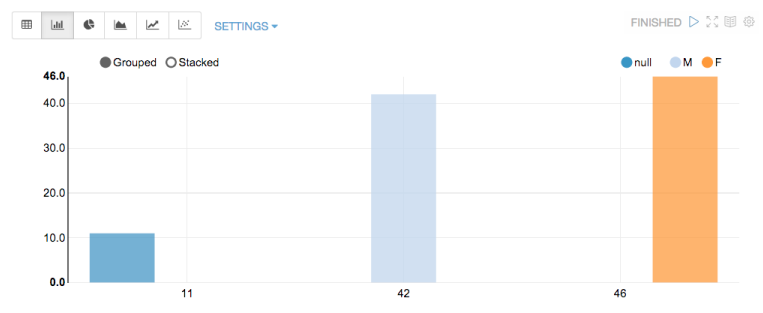
这样将会输出相关的结果。至此,我们通过dep加载外部依赖库已经介绍完了。















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









