






原标题:技术分析:Spark数据倾斜怎么入门
最近工作中spark任务遇见了某个task异常慢的情况,最后发现是数据倾斜导致。
这里简单记录一下相应的场景。
数据准备
先准备四条数据:
320321199105077870,xm
320321199105077871,hw
320321199105077874,jd
320321199105077877,sn
测试代码
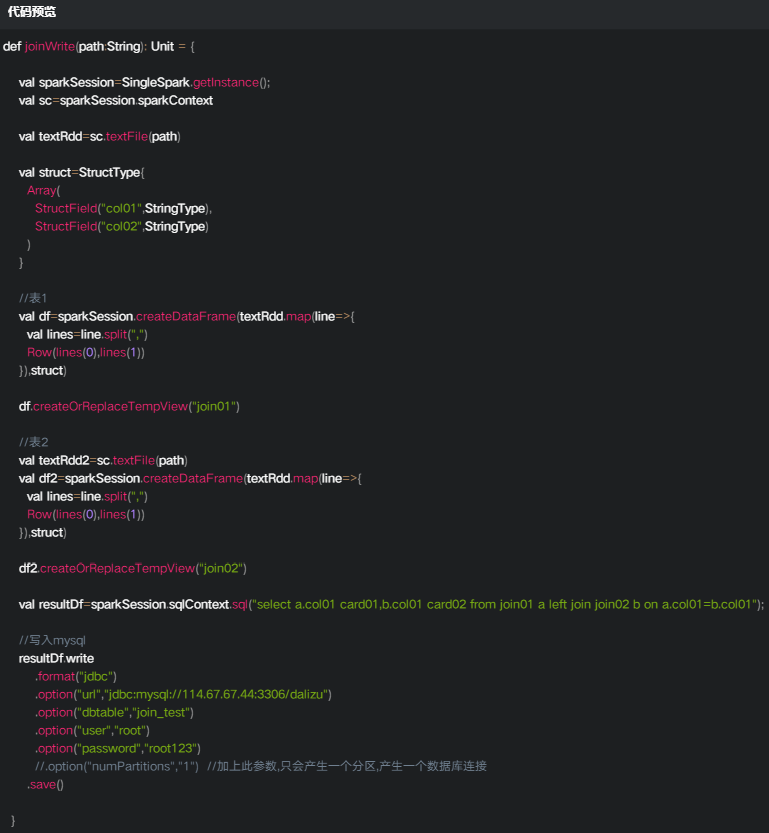
参数使用和测试
spark.sql.shuffle.partitions
默认情况下sparksql中的值为200
执行上面的代码我们可以通过spark web页面进行查看
发现上面的代码会产生一个Job,包含三个stage:

可以发现stage2会包含200个task.
我们点到这个stage中去查看task的详情信息
会发现很多task都没有处理数据,只有四个task处理了数据,每个task处理了两条数据。
说明spark对数据进行了分区,每条数据都落在了不同的分区中。并且少量数据的情况下,会有很多空跑的task,这种情况应该减少task的数量。
通过修改参数来进行测试,有以下两种方式:
1-val spark = SparkSession.builder()
.config(spark.sql.shuffle.partitions,100)//设置并行度100
.getOrCreate()
2-修改脚本设置两个并行度

我们这里把spark.sql.shuffle.partitions修改为4。
然后观察web监控页面:http://192.168.76.142:8088/proxy/application_1576415699341_0007/jobs/
可以看到stage2总共会产生4个task.
某个key过大的情况
我们将数据量调大,然后再次执行。比如最后一行数据增加到37个。
我们会发现
其中有一个task处理了74条数据,而其他三个task有一个处理了2条,一个处理了4条,还有一个task没有数据处理。
并且这个task处理时间为37s.远大于其他的0.6s。(这里数据量比较小,机器性能也比较低)

可以想象,如果持续加大这行数据的数量,这个task所需要处理的数据也会加大,执行的时间也会越来越长,就会出现
其他task都执行完毕,然后等待这个task的执行,就出现了数据倾斜的情况。
在spark中,每个task处理的分区数据会根据key来进行分布,不同的key可能会划分到不同的分区下,具体的算法可以查看
相关资料。每个task会处理一个分区的数据。
JDBC参数测试
我们通过这种方式将分区数据写入mysql中:

不管是读还是写,其实每一个分区都会打开一个jdbc连接,所以分区数量不能太多。
我们可以通过.option(numPartitions,1)参数来限制jdbc的连接数。
放开这行代码之后,你就会发现此时只会有一个task处理所有的数据80条.也就是产生一个jdbc的连接。
具体原理可以自己了解一下coalease接口。当然顺便可以比较一下repartition的使用。返回搜狐,查看更多
责任编辑:















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









