






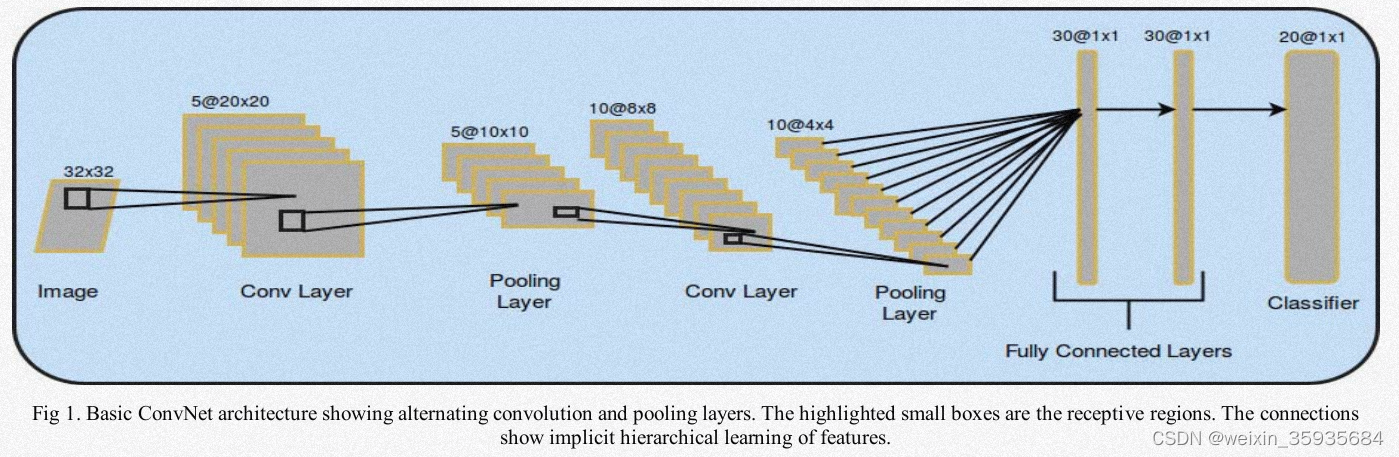
一、神经网络架构
1.卷积层
该层是卷积网络的基本单元。它由一系列排列着神经元的特征图组成。该层的参数是一系列的卷积核(滤波器)。这些卷积核与特征图进行卷积从而产生单独的二维激活图,它们在z轴上堆叠产生最终的输出。同一张特征图的神经元共享权重,通过降低参数数量可以减少网络复杂度。两层神经元之间稀疏连接的空间扩展是称为感受野的超参。卷积层中控制输出大小的超参称为深度(滤波器的数量),步幅(控制滤波器的移动)以及零填充(控制输出空间大小)。卷积网络使用反向传播进行训练,反向传播也涉及卷积运算,但是用的是空间翻转滤波器。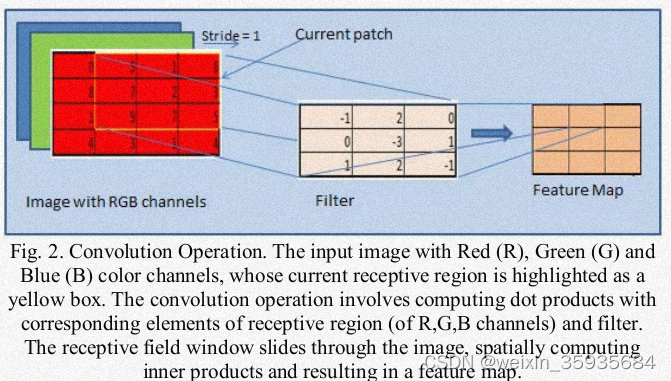
2.非线性映射层
非线性函数的目的是把输入信号转换为输出信号,用于下一个层的输入。常见的非线性映射函数(激活函数)如下:
Sigmoid:输出位于0~1之间。缺点是啊a.容易造成梯度饱和以及梯度消失b.输出不是零中心,容易在正值和负值之间振荡。具体形式如下:

Tanh:输出位于-1~1之间的数。仍然存在梯度饱和的问题,但由于输出是以0为中心,输出不在正负两极间震荡。一般比Sigmoid常用。
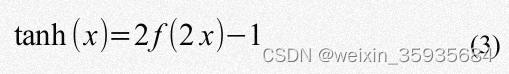
ReLU:通过使用ReLU函数,可以加速梯度下降的收敛过程。
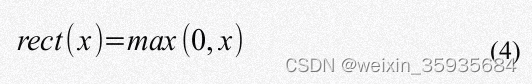
Leaky ReLU:
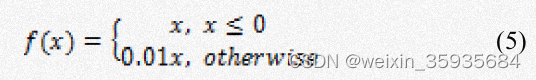
3.池化层
基本的卷积网络架构通过交替卷积层与池化层,在不丢失信息的前提下,减少激活图的空间维度以后网络的参数从而降低计算复杂度。常见的池化操作包括最大池化、平均池化、随机池化、频谱池化以及空间金字塔池化等。它可以解决过拟合问题。最大池化过程如下图所示:
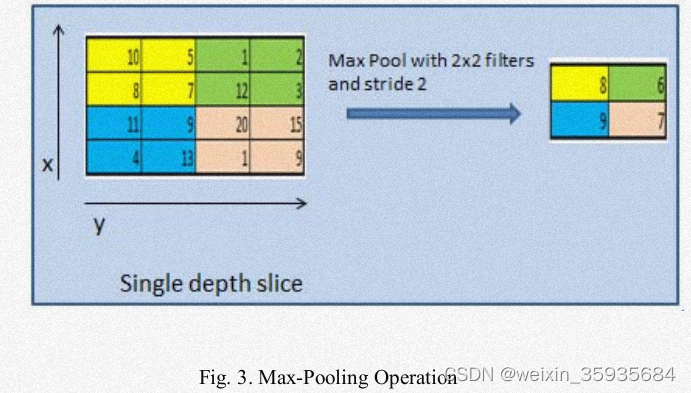
4.全连接层
该层的每个神经元和前一层的所有神经元相连,我们基于前一层的激活输出,在全连接层计算预测结果,用于分类和回归。由于全连接层的输出是一维向量,因此无法在其后添加卷积层。
5.损失函数层
最后一个全连接层用于计算损失,作为预测值和真实值不匹配的惩罚。如果从K个互斥类中预测一个单独的类,通常使用Softmax函数。交叉熵损失函数预测样本属于K个类别的K个概率值。欧式损失通常用于回归问题中。
二、主干网络模型
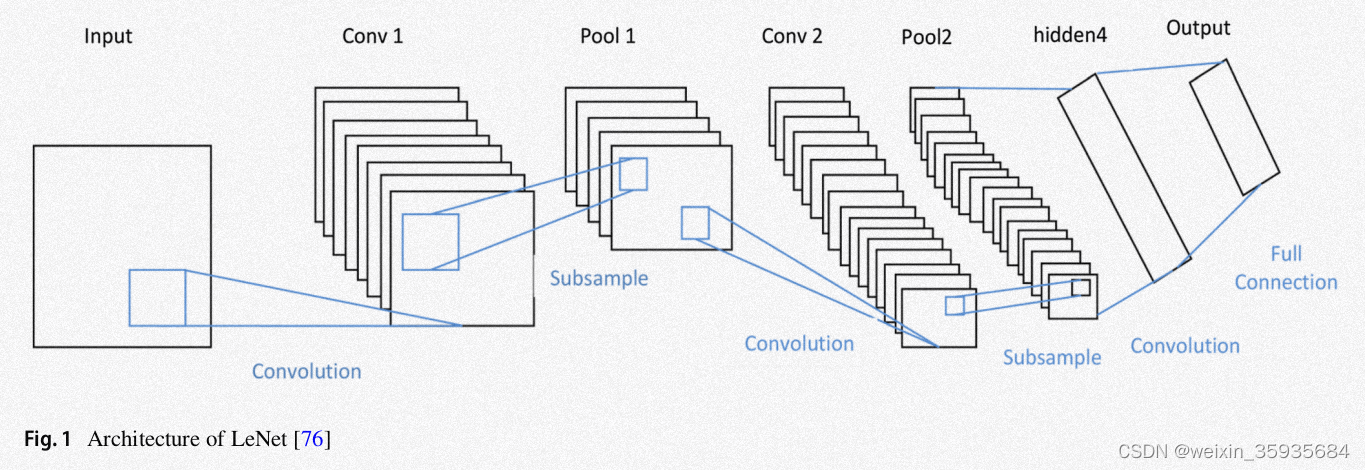
1.LeNet
这种传统的神经网络架构被成功地应用到了MNIST手写数字识别中。LeNet要求输入是一张32×32×1的灰度图,经过卷积层和下采样层。之后又经过一系列伴随着池化层的卷积层。最后是三个全连接层。它利用的是步幅为1的5×5的卷积核。
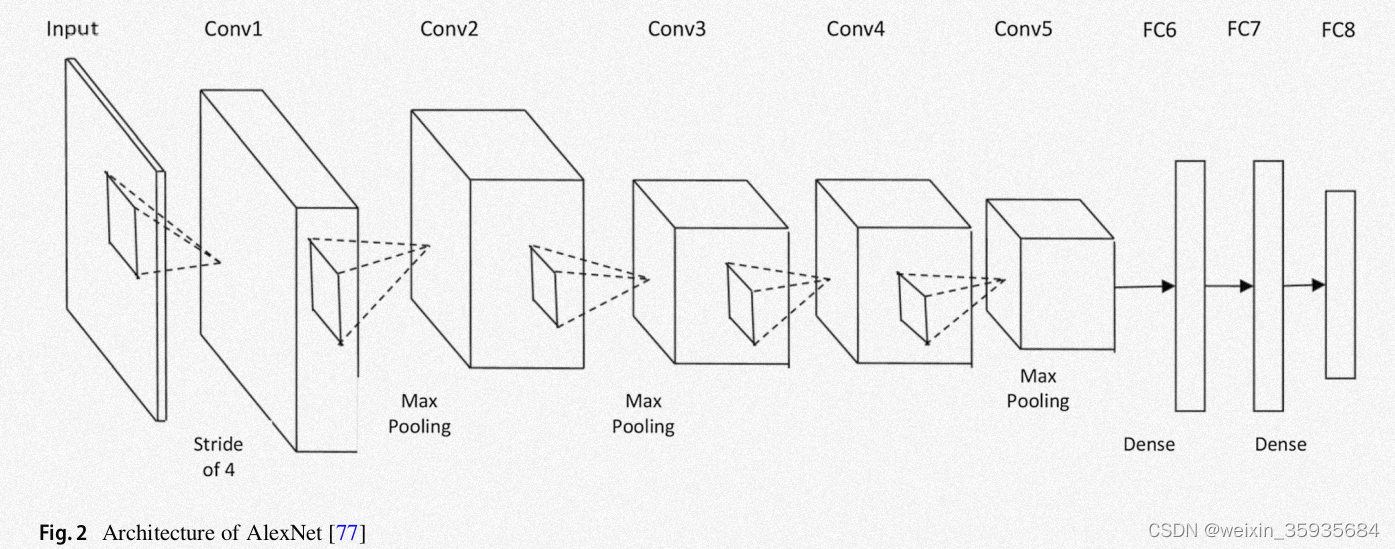
2.AlexNet
它首先利用了一系列的数据优化方法,包括图像平移,局部提取以及水平翻转。该模型通过丢弃层解决了训练数据过程中的过拟合问题。它通过随机梯度下降法,以给定值进行权重衰减和梯度优化。它包括5个卷积层以及池化层,以ReLU函数为激活函数,3个全连接层和丢弃层。
3.ZFNet
该模型在输入上利用7×7的卷积核以减小步幅。后来由此发展除了反卷积网络技术。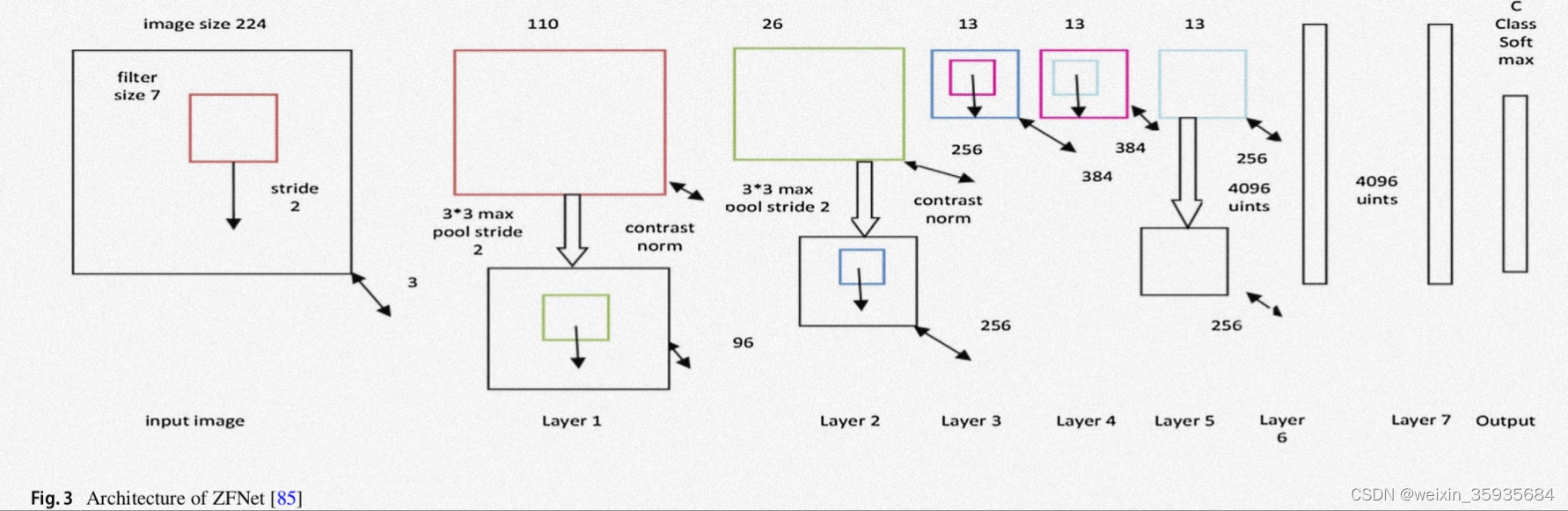
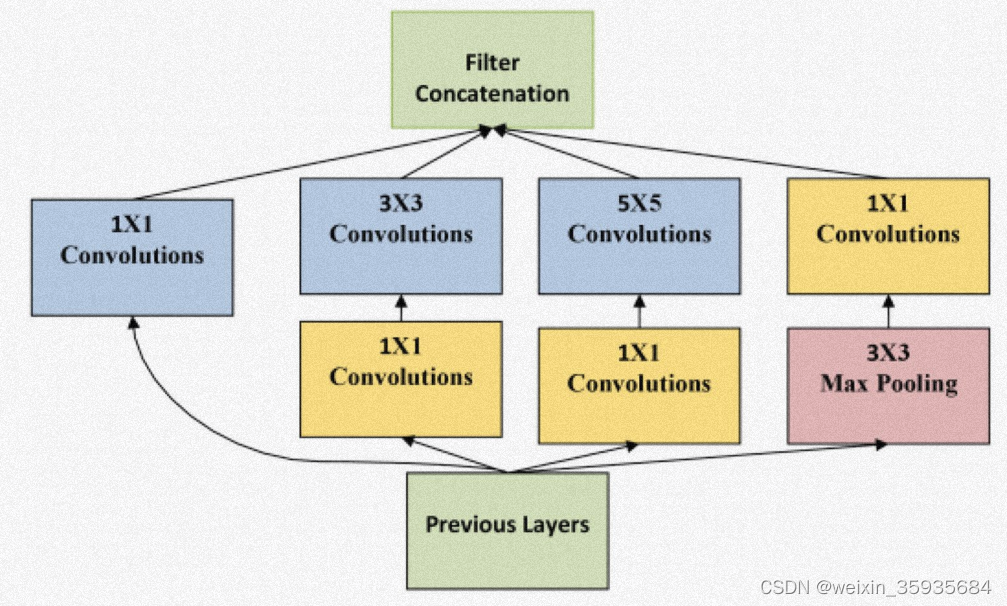
4.GoogleNet
该模型采用一种名为“inception module”的块,可以有效的拓宽模型的宽度和深度。GoogleNet最典型的结构用了22个inception module,最后参数还是要比AlexNet少。
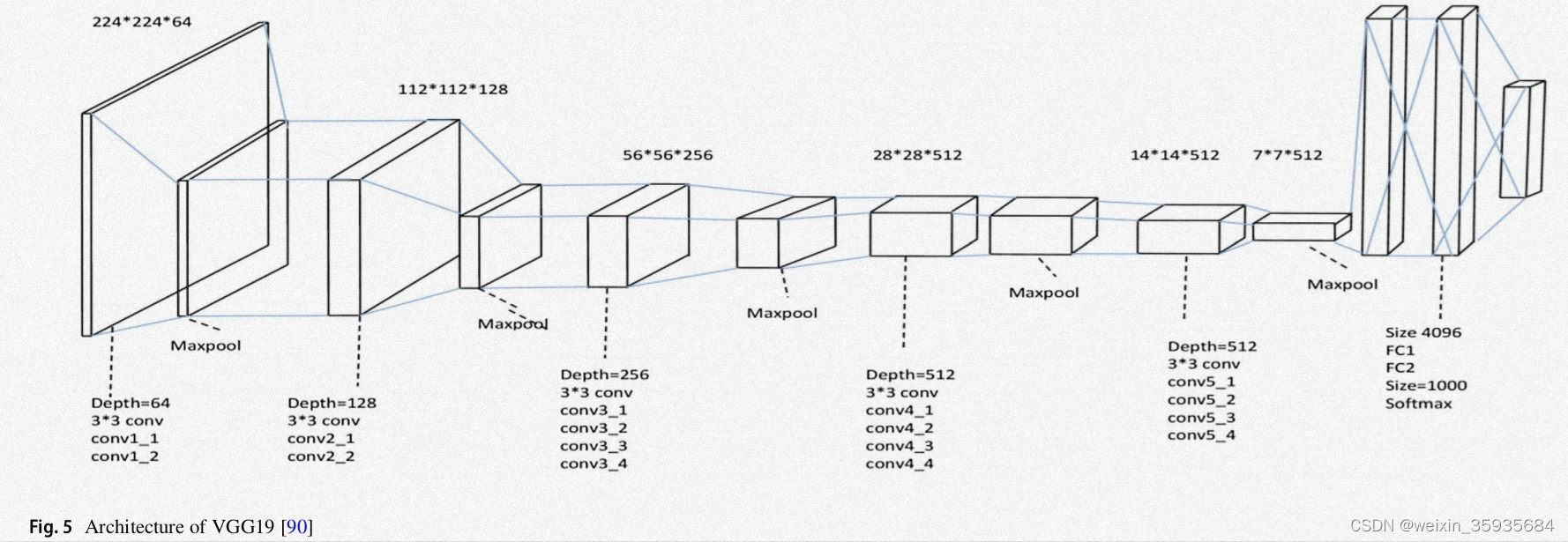
5.VGGNet
VGG-16有13个卷积层和3个全连接层,而VGG-19有3个额外的卷积层。它的感受野尺寸为3×3,每个隐藏层都以ReLU作为激活函数。前向传播和深度处理,是该模型的意义。
6.ResNet
残差网络通过一种类似于“跳线”的技巧,在原本距离很远的两个网络层之间建立一个短路连接,打破了神经网络逐层传递的结构,从而避免了梯度爆炸和梯度消失的问题。借助于残差网络,人们可以很轻松的搭建1000层以上的神经网络。
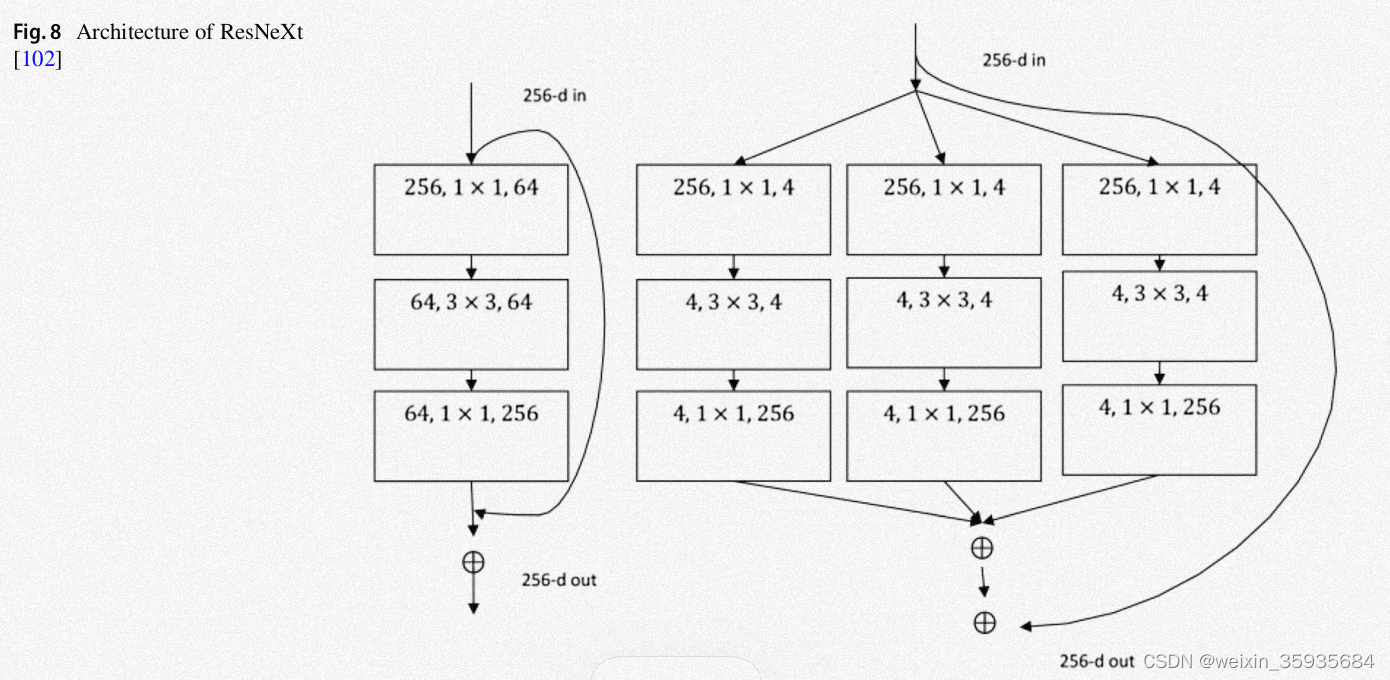
7.ResNeXt
这是一种可管理的架构,它基于VGG/ResNet的结构,形成了拆分、转换以及合并的过程。这些残差块使用相似的拓扑和规则。
 9.MobileNet
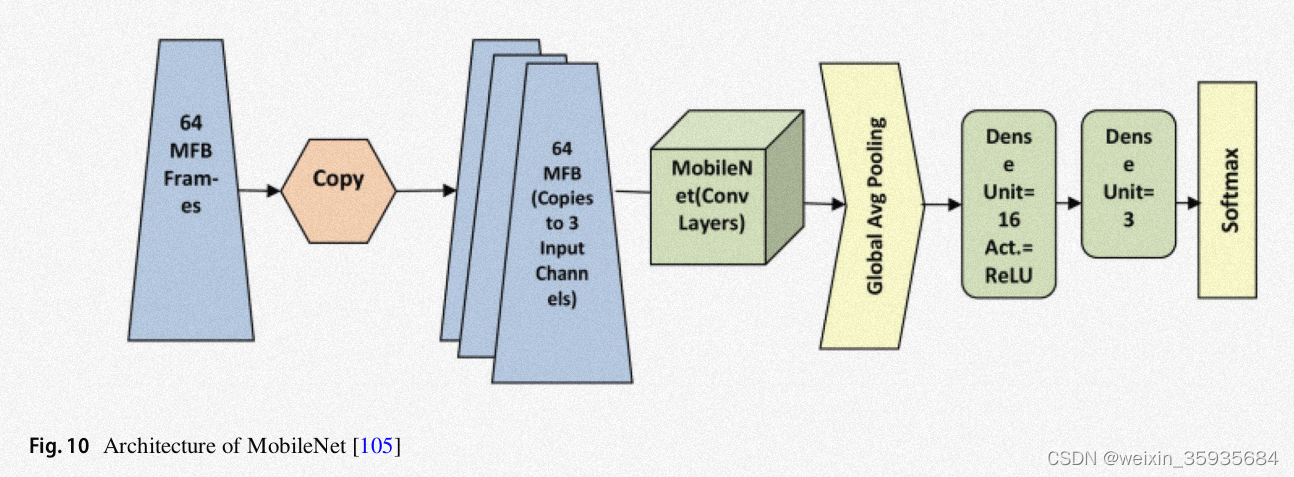
9.MobileNet
在该模型中,传统的卷积被深度独立卷积替代。它在每个颜色通道上施加单独的卷积操作,而不是把三个通道连接起来再进行平滑操作。
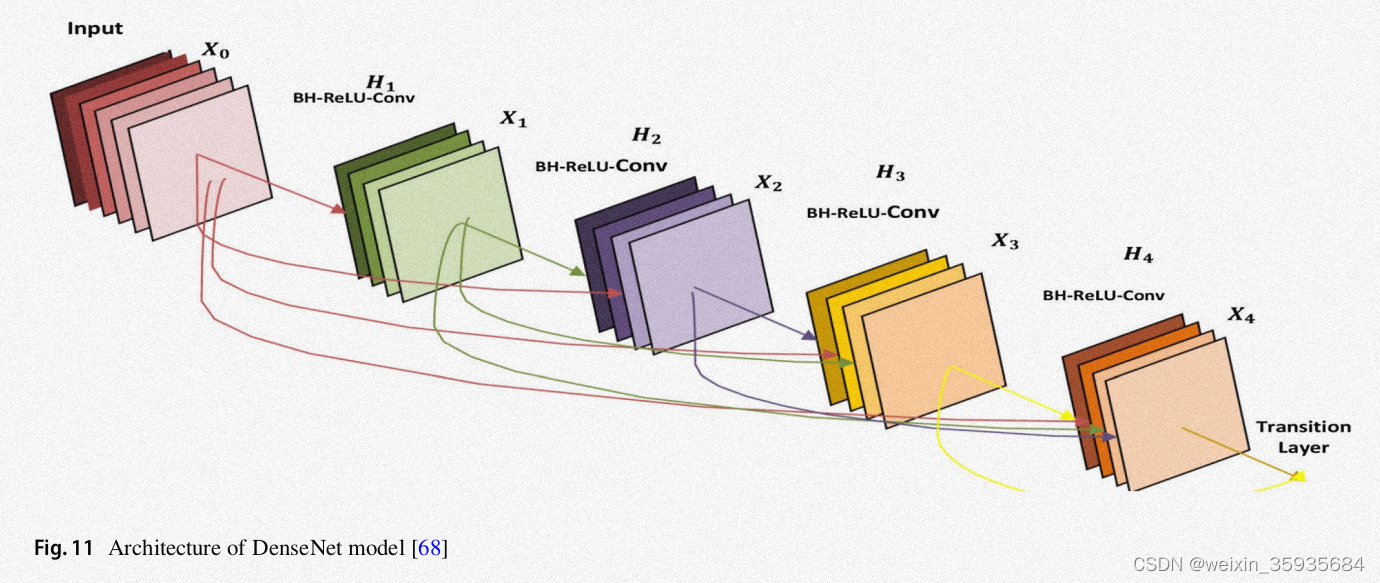
10.DenseNet
该架构每一层都以前馈方式耦合。L层的模型有L(L+1)/2个直接连接。它将输出特征图与输入特征图连接在一起,每一层都从之前的所有层获取知识。这项工作在减少梯度消失问题、最小化参数数量和特征重用方面很有用。在CIFAR-100、ImageNet等数据集上都实现了最先进的性能,唯一的缺点是由于张量串联,需要大量额外内存。
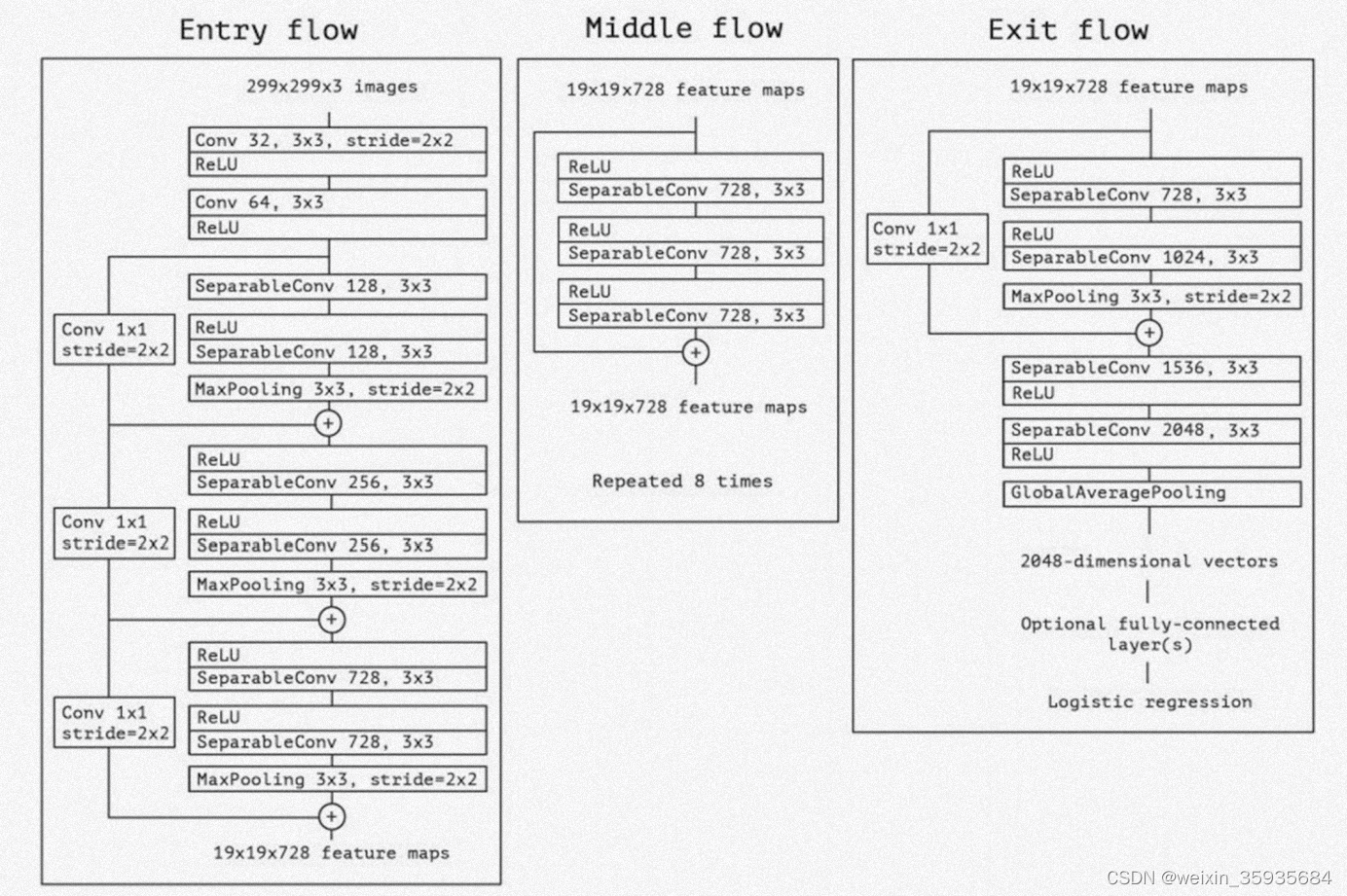
11.Xception
该模型是“inception module”的扩展,它运用了这样一条假设:空间关联性和跨通道关联性可以适当的解耦。
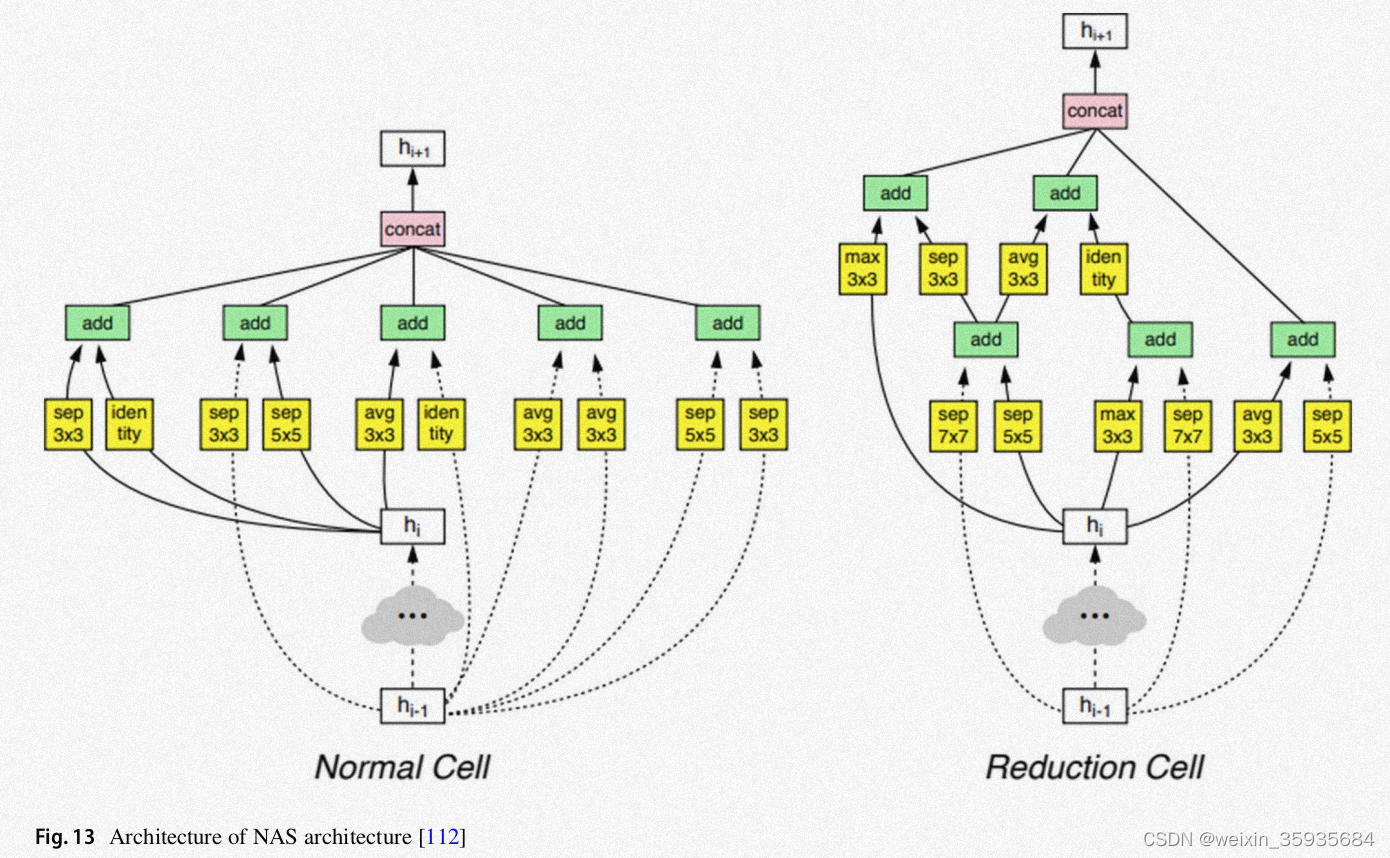
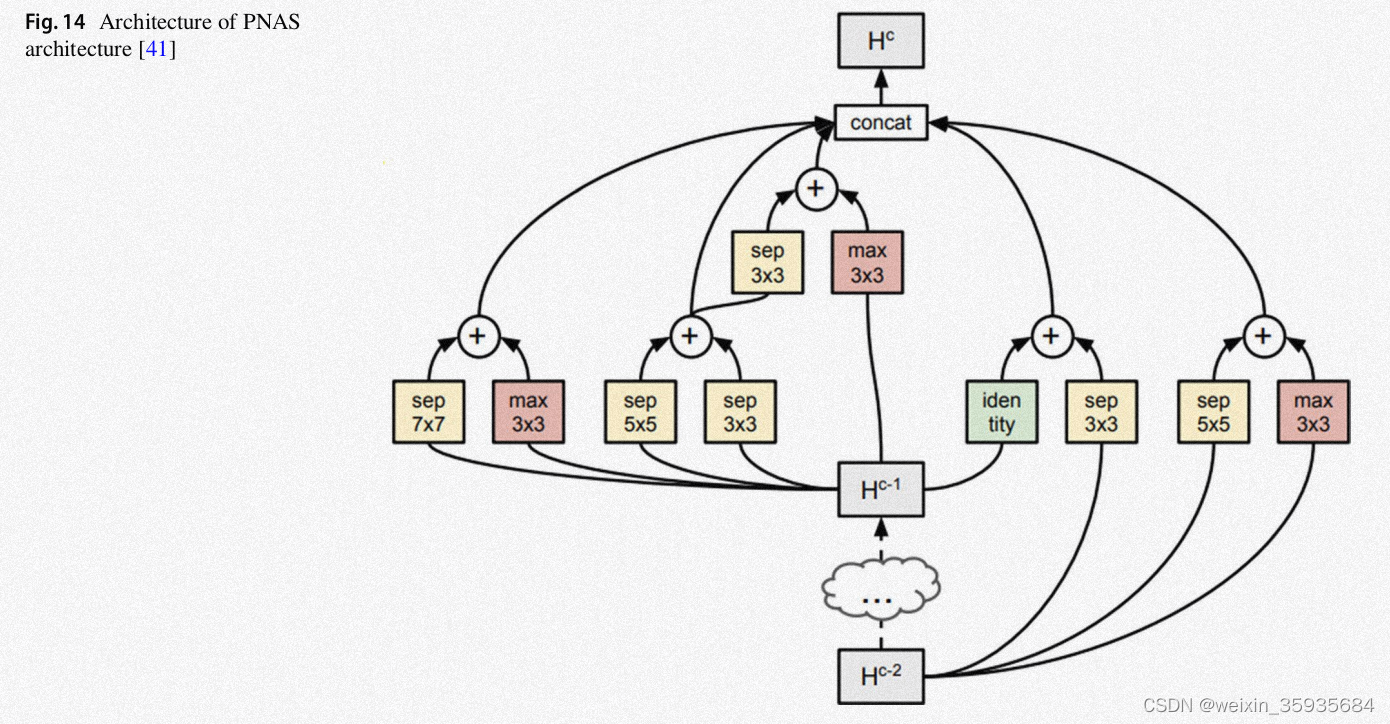
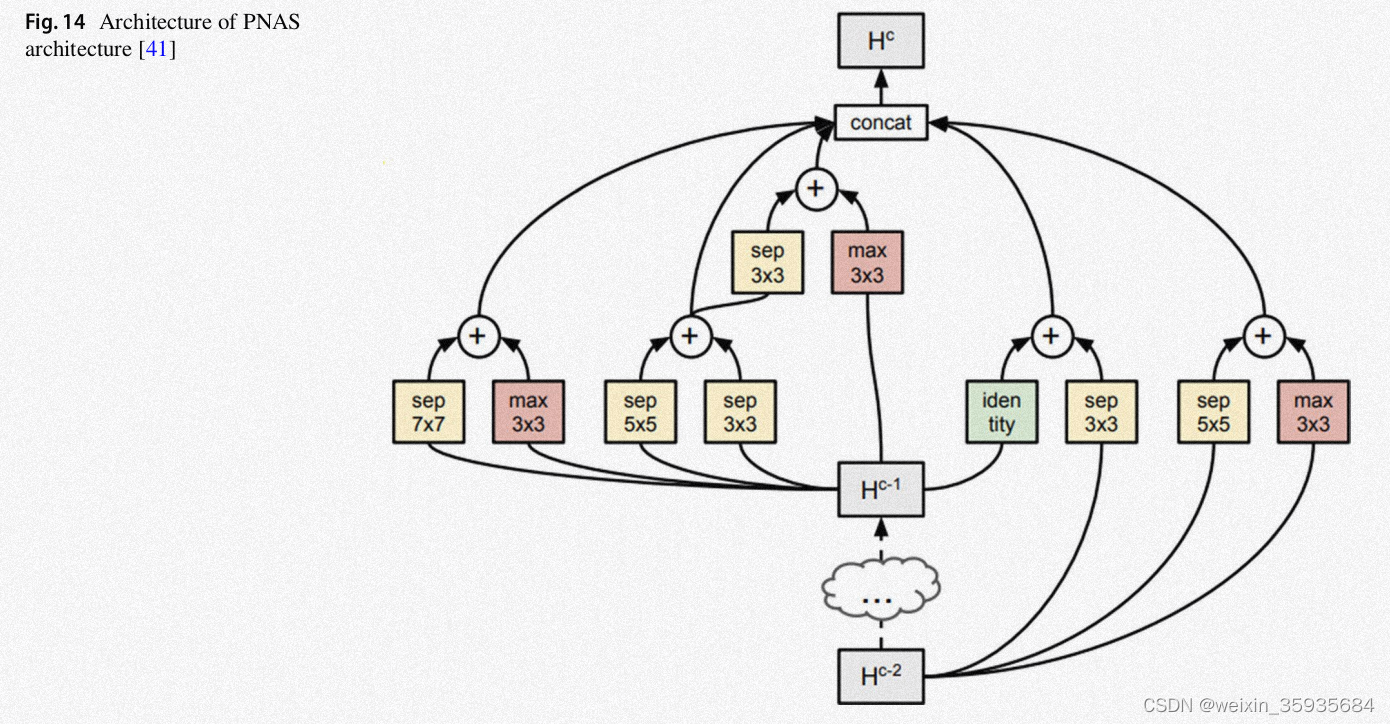
12.NAS\PNAS\ENAS
Neural Architecture Search是一种最优模型搜索算法。为了优化模型的配置,标准的NAS使用强化学习搜索方法。
在渐进式搜索框架中(PNAS),我们用序列化基于模型的优化(SMBO)代替强化学习。该图主要说明了我们可以利用渐进式方法进行架构查询。学习到的预测函数会和逐渐复杂的图空间合并。它可以快速训练基础模型,从而预测要求的替代结构的质量。
高效神经网络架构搜索(ENAS)利用宏观和微观搜索生成两种类型的神经网络,分别叫做控制器和子模型。其中控制器是一个与训练好的RNN,子模型是图像分类要求的CNN。
13.EfficientNet
这是一种缩放技术,其核心是利用有效复合系数以逐步组织的方式放大CNN。它使用一组固定的缩放系数,一致的缩放每个维度,比如深度、宽度和分辨率。















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









