







zookeeper是一个分布式协调服务。所谓分布式协调主要是来解决分布式系统中多个进程之间的同步限制,防止出现脏读,例如我们常说的分布式锁。
zookeeper中的数据是存储在内存当中的,因此它的效率十分高效。它内部的存储方式十分类似于文件存储结构,采用了分层存储结构。但是它和文件存储结构的区别是,它的各个节点中是允许存储数据的,需要注意的是zk的每个节点存储数据不能超过1M。它的内存数据结果如下图:
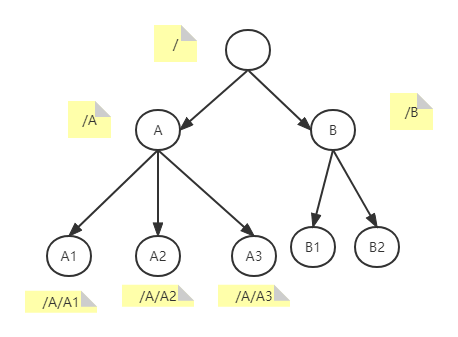
可以通过不同的路径访问到不同的节点,因为它是分层结构,我们也可以通过某一个父节点,获取到该节点下的所有子节点信息。
zk只提供了几个简单的api,但是我们可以通过灵活使用这些api的组合,来实现我们复杂的业务要求:
- create:创建一个新节点,通过指定路径的方式创建节点,例如创建路径为/A/A1/demo,则会在A1节点下创建一个demo节点;
- delete:删除节点,通过路径的方式删除节点,如果删除路径为/A/A1/demo,则会删除A1节点下的demo节点;
- exists:判断指定路径下的节点是否存在,例如判断路径为/A/A1/demo,则会判断A1节点下的demo节点是否存在;
- get:获取指定路径下某个节点的值是什么,例如获取路径为/A/A1/demo,则会获取A1节点下的demo节点的值什么;
- set:为指定路径的节点进行赋值操作,例如修改路径为/A/A1/demo,则会修改A1节点下的demo节点的值;
- get children:获取指定路径节点下的子节点信息,例如获取路径为/A,则会获取A节点下的A1和A2节点;
- sync:获取到同步数据,这个涉及到了zk的原理,zk集群属于最终一致性,调用该方法,可以获取到最终的结果值,如果不使用该方法,在查询的时候可能获取到的值是中间值;
zk中创建的节点分为两种:永久性节点和临时性节点。永久性节点即创建以后,在不执行delete命令的前提下,该节点是永久存在的;而临时节点与session有关,每个客户端与zk建立链接的时候会生成一个session,这个session不会因为链接zk服务器节点的变化而变化,只有当客户端断开连接以后,该session才会消失,而临时节点会随着session的消失而消失。
zk拥有watch机制,也就是监视机制,可以支持响应式编程模式,它可以对某个路径的终节点及其子节点的变更进行监视,当其发生变更以后,会调用注册的callback方法,然后进行具体的业务逻辑。例如监测路径为/A/A1,那么它会加测A1节点,以及附属于A1的所有子节点,这个子不单单只一层子节点,是指所有层的子节点。
zk拥有以下几个重要特性:
1)顺序一致性:来自客户端的相关指令会按照顺序执行,不会出现乱序的情况,客户端发送到服务的指令1->2->3->4,那个这些指令就会按照顺序执行;
2)原子性:更新只有成功和失败,没有中间状态;
3)可靠性:也可以称之为持久性,节点更新以后,在下次更新之前,它的数据不会发生变更;
4)准实时性:也可以称之为最终一致性,在zk集群中,一个客户端修改了其中的一个节点,一定时间以后,所有可用的服务对应的节点都会变成更新以后的值。
分布式锁
zk作为分布式协调服务,它的一个很大的作用就是用来实现分布式锁。zk节点存在临时节点,它的生命周期与session有关,它会随着session的消失而消失,这就解决了分布式锁时可能出现的死锁问题。
Zookeeper 是基于临时顺序节点以及 Watcher 监听器机制实现分布式锁的。
具体流程
- 一把分布式锁通常使用一个 Znode 节点表示;如果锁对应的 Znode 节点不存在,首先创建 Znode 节点。这里假设为 /test/lock,代表了一把需要创建的分布式锁。
- 抢占锁的所有客户端,使用锁的 Znode 节点的子节点列表来表示;如果某个客户端需要占用锁,则在 /test/lock 下创建一个临时顺序的子节点。比如,如果子节点的前缀为 /test/lock/seq-,则第一次抢锁对应的子节点为 /test/lock/seq-000000001,第二次抢锁对应的子节点为 /test/lock/seq-000000002,以此类推。
- 当客户端创建子节点后,需要进行判断:自己创建的子节点,是否为当前子节点列表中序号最小的子节点。如果是,则加锁成功;如果不是,则监听前一个 Znode 子节点变更消息,等待前一个节点释放锁。
- 一旦队列中的后面的节点,获得前一个子节点变更通知,则开始进行判断,判断自己是否为当前子节点列表中序号最小的子节点,如果是,则认为加锁成功;如果不是,则持续监听,一直到获得锁。
- 获取锁后,开始处理业务流程。完成业务流程后,删除自己的对应的子节点,完成释放锁的工作,以方面后继节点能捕获到节点变更通知,获得分布式锁。
ZooKeeper 分布式锁的优缺点
这里把 Zookeeper 与 Redis 实现分布式锁对比一下:
- 优点:ZooKeeper分布式锁(如 InterProcessMutex),除了独占锁、可重入锁,还能实现读写锁,并且可靠性比 Redis 更好。
- 缺点:ZooKeeper实现的分布式锁,性能并不太高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。而 ZK 中创建和删除节点只能通过 Leader 服务器来执行,然后 Leader 服务器还需要将数据同不到所有的 Follower 机器上,同步之后才返回,这样频繁的网络通信,性能的短板是非常突出的;而 Redis 则是异步复制。
Redis 是 AP 架构,而 ZooKeeper 是 CP 架构。在高性能,高并发的场景下,不建议使用ZooKeeper的分布式锁,可以使用 Redis 分布式锁。而由于ZooKeeper的可靠性,所以在并发量不是太高的场景,推荐使用ZooKeeper的分布式锁。















 2523
2523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









