







写在前面
本文是对一些文本匹配的核心函数做一个梳理(正好前段时间一直在搞检索问答相关的实验,核心之一在于如何构建匹配函数得到二维匹配矩阵),内容包含Attention Pooling模型、Decomposable Attention模型、SUBMULT+NN模型、BiMPM模型、ESIM模型。这些函数有的仅仅用于问答,有的用于自然语言推理(NLI),发展还是很有规律的。另外,本文只涉及模型的结构做法,实验可以参考原文~
Attention Pooling
处理的任务是:给定问题
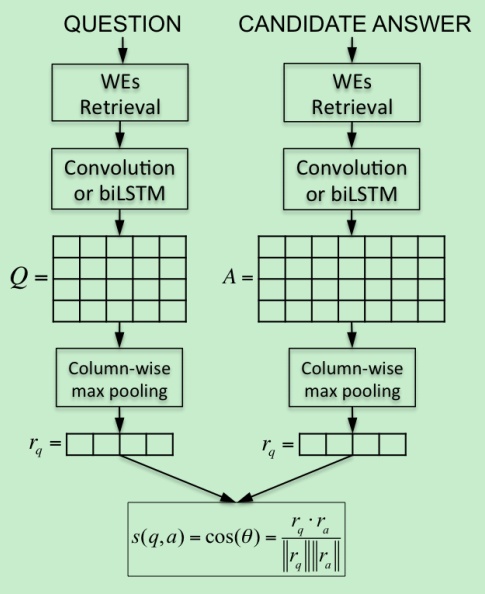
典型的双塔模型(Siamese Model),
其中矩阵
然后对得到的最大化池化结果自身做一个softmax:
对于
最终的匹配分数就是两个Attentive Pooling后的表征的余弦相似度。
本工作首先可以借鉴的是:
(1)使用双线性计算相似度
(2)使用得分矩阵通过Attentive Pooling交互问题和答案的表征(需要注意的是这是一个双向注意力,而且有一定 compare aggregate思想的影子--这个是目前文本匹配较为流行的)
Decomposable Attention
Decomposable Attention模型是用于自然语言推断的一个简单的神经网络。所谓的自然与然推断就是--确定前提(premise)与假设(hypothesis)之间是蕴涵关系或矛盾关系的问题。如下图例子:

可以很容易推断出第二句“Bob is awake”是紧跟着第一句,但是三句与第一句是矛盾的。
尽管此模型的提出不在于选择问答的范畴,但是在选择问答尤其是句子(语义)匹配的问题上非常有借鉴意义。原文亮点:(1)在subphase(可以理解为基于词层面的表示,之前的Siamese网络都是基于句子层面的)上进行推断,这样更能够充分利用到句子的元素信息,信息的粒度更加细致。(2)率先使用了比较聚合(Compare-Aggregate)范式,这个范式很重要,很多交互式问答都使用了这个范式,如多轮检索式对话等。Compare-Aggregate的做法大致分为三步--(1)Attend;(2)Compare;(3)Aggregate。另外需要注意的是亮点(1)我们经常操作匹配等都是在经过GRU或者CNN之后的上下文编码,但是原文只是用的是词嵌入以及增强的词嵌入(加入了Intra-Sentence Attention算法),原文模型可以看成一个纯前馈网络,是一种rnn/cnn-free的模型,他能干过基于CNN或者RNN模型在于其很多精细化的设计,尽管现在看来很多已经过时,但是方法还是值得借鉴与分析的,这个很重要。
Attend
所谓的attend,就是一个句子或者文案通过对齐矩阵(或者匹配矩阵或者注意力矩阵)去表示另一个句子或者文档的意思,如question attend to answer就是使用answer来表示question。如输入的两个文本
这
也就是按行softmax或者按列softmax来计算然后加和表征。
Compare
上一步得到了对齐部分然后与原来的表征拼接得到
Aggregate
对于上一步得到的两个比较向量
最后分类的结果就是简单的线性层
Intra-Sentence Attention增强词嵌入算法
上文提到了原文通过很精细化的设计让其可以CNN/RNN-free进而大幅度并行以及减少参数量,但是词嵌入不管是预训练的还是没有预训练的,他们都没有一个上下文联系,如果没有RNN或者CNN来编码上下文(不管是长期的还是局部的),模型的性能不一定比较强壮。在此原文提出一种增强词嵌入的方法,让原始词嵌入可以有一个全局信息的感知(其实很像self-attention,但是应该是有缺陷的)。对于输入序列
其中
本工作首先可以借鉴的是:
(1)Compare-Aggregate用于匹配的范式;
(2)双向注意力的使用;
(3)词嵌入增强算法---基于Intra-Sentence Attention















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









