







A Transformer-based Approach for Source Code Summarization 全文翻译
本文最佳阅读方式:读完一段中文内容快速阅读对应的英文部分
PS: 大模型基础和进阶付费课程(自己讲的):《AIGC大模型理论与工业落地实战》-CSDN学院 或者《AIGC大模型理论与工业落地实战》-网易云课堂
本文来自ACL 2020 Accepted Paper.
https://arxiv.org/abs/2005.00653
https://github.com/wasiahmad/NeuralCodeSum
基于Transformer的源代码摘要生成
摘要
Generating a readable summary that describes the functionality of a program is known as source code summarization. In this task, learning code representation by modeling the pairwise relationship between code tokens to capture their long-range dependencies is crucial. To learn code representation for summarization, we explore the Transformer model that uses a self-attention mechanism and has shown to be effective in capturing long-range dependencies. In this work, we show that despite the approach is simple, it outperforms the state-of-the-art techniques by a significant margin. We perform extensive analysis and ablation studies that reveal several important findings, e.g., the absolute encoding of source code tokens’ position hinders, while relative encoding significantly improves the summarization performance. We have made our code publicly available to facilitate future research(https://github.com/wasiahmad/NeuralCodeSum).
生成一个可读的描述程序功能的摘要称为源代码摘要。在此任务中,通过对代码token之间的成对关系建模以捕获其长期依赖性来学习代码表示至关重要。为了学习摘要的代码表示,我们探索了使用自注意机制的Transformer模型,该模型已证明在捕获远程依赖项方面有效。在这项工作中,我们表明,尽管该方法很简单,但在很大程度上领先于最新技术。我们进行了广泛的分析和消融研究,揭示了一些重要发现,例如,源代码token位置的绝对编码是有阻碍的,而相对编码则显着提高了摘要性能。我们已将代码公开发布以方便将来的研究:https://github.com/wasiahmad/NeuralCodeSum。
1 介绍
Program comprehension is an indispensable ingredient of software development and maintenance (Xia et al., 2018). A natural language summary of source code facilitates program comprehension by reducing developers’ efforts significantly (Sridhara et al., 2010). Source code summarization refers to the task of creating readable summaries that describe the functionality of a program.
程序理解是软件开发和维护必不可少的组成部分(Xia et al., 2018)。源代码的自然语言摘要通过显著减少开发人员的工作量来促进程序理解(Sridhara et al., 2010)。源代码摘要是指创建描述程序功能的可读摘要的任务。
With the advancement of deep learning and the availability of large-scale data through a vast number of open-source repositories, automatic source code summarizing has drawn attention from researchers. Most of the neural approaches generate source code summaries in a sequence-to-sequence fashion. One of the initial works Iyer et al. (2016) trained an embed-ding matrix to represent the individual code tokens and combine them with a Recurrent Neural Network (RNN) via an attention mechanism to generate a natural language summary. Subsequent works (Liang and Zhu , 2018 ; Hu et al., 2018a , b ) adopted the traditional RNN-based sequence-tosequence network (Sutskever et al., 2014) with attention mechanism (Luong et al., 2015) on different abstractions of code.
随着深度学习的发展以及通过大量开放源代码存储库提供的大规模数据的可用性,自动源代码摘要已引起研究人员的关注。大多数神经方法都以sequence-to-sequence的方式生成源代码摘要。Iyer et al. (2016) 的早期工作之一就是训练了一个嵌入矩阵来表示各个代码token,并通过注意力机制将它们与递归神经网络(RNN)结合起来以生成自然语言摘要。随后的工作(Liang and Zhu , 2018 ; Hu et al., 2018a , b)采用了传统的基于RNN的sequence-tosequence网络(Sutskever et al., 2014),并在不同的摘要代码中采用了注意力机制(Luong et al., 2015)。
The RNN-based sequence models have two limitations in learning source code representations.
基于RNN的序列模型在学习源代码表示中有两个限制。
First, they do not model the non-sequential structure of source code as they process the code tokens sequentially. Second, source code can be very long, and thus RNN-based models may fail to capture the long-range dependencies between code tokens. In contrast to the RNN-based models, Transformer (Vaswani et al., 2017), which leverages self-attention mechanism, can capture long-range dependencies. Transformers have been shown to perform well on many natural language generation tasks such as machine translation (Wang et al., 2019), text summarization (You et al., 2019), story generation (Fan et al., 2018), etc.
首先,他们不会对源代码的非顺序结构建模,因为它们会顺序处理代码token。其次,源代码可能很长,因此基于RNN的模型可能无法捕获代码token之间的长期依赖关系。与基于RNN的模型相比,利用自注意机制的Transformer (Vaswani et al., 2017)可以捕获长期依赖关系。事实证明,Transformer在许多自然语言生成任务中表现出色,例如机器翻译(Wang et al., 2019),文本摘要(You et al., 2019),故事生成(Fan et al., 2018)等。
To learn the order of tokens in a sequence or to model the relationship between tokens, Transformer requires to be injected with positional encodings (Vaswani et al., 2017; Shaw et al., 2018; Shiv and Quirk , 2019). In this work, we show that, by modeling the pairwise relationship between source code tokens using relative position representation (Shaw et al., 2018), we can achieve significant improvements over learning sequence information of code tokens using absolute position representation (Vaswani et al., 2017).
为了了解序列中token的顺序或建模token之间的关系,需要向Transformer注入位置编码 (Vaswani et al., 2017; Shaw et al., 2018; Shiv and Quirk , 2019)。在这项工作中,我们表明,通过使用相对位置表示对源代码token之间的成对关系进行建模(Shaw et al., 2018),相对于使用绝对位置表示的学习代码token的序列信息(Vaswani et al., 2017)可以实现重大改进。
We want to emphasize that our proposed approach is simple but effective as it outperforms the fancy and sophisticated state-of-the-art source code summarization techniques by a significant margin. We perform experiments on two well-studied datasets collected from GitHub, and the results endorse the effectiveness of our approach over the state-of-the-art solutions. In addition, we provide a detailed ablation study to quantify the effect of several design choices in the Transformer to deliver a strong baseline for future research.
我们要强调的是,我们提出的方法简单但有效,因为它在很大程度上超越了花哨的和复杂的最新源代码摘要技术。我们对从GitHub收集的两个经过充分研究的数据集进行了实验,结果证明了我们的方法在最新解决方案上的有效性。此外,我们提供了详细的消融研究,以量化Transformer中几种设计选择的效果,从而为将来的研究提供坚实的基础。
2 建议的方法
We propose to use Transformer (Vaswani et al., 2017) to generate a natural language summary given a piece of source code. Both the code and summary is a sequence of tokens that are represented by a sequence of vectors, x = ( x 1 , . . . , x n ) x =(x_1,...,x_n) x=(x1,...,xn) where x i ∈ R d m o d e l x_i∈R^{d_{model}} xi∈Rdmodel . In this section, we briefly describe the Transformer architecture (§ 2.1) and how to model the order of source code tokens or their pairwise relationship (§ 2.2) in Transformer.
我们建议使用Transformer(Vaswani et al., 2017) 在给出一段源代码的情况下生成自然语言摘要。代码和摘要都是由一系列向量表示的token序列,其中 x = ( x 1 , . . . , x n ) x =(x1,...,x_n) x=(x1,...,xn),其中 x i ∈ R d m o d e l x_i∈R^{d_{model}} xi∈Rdmodel。在本节中,我们将简要介绍Transformer体系结构(第2.1节)以及如何在Transformer中对源代码token的顺序或其成对关系(第2.2节)进行建模。
2.1 架构
The Transformer consists of stacked multi-head attention and parameterized linear transformation layers for both the encoder and decoder. At each layer, the multi-head attention employs h h h attention heads and performs the self-attention mechanism.
Transformer由堆叠的多头注意力和用于编码器和解码器的参数化线性变换层组成。在每一层上,多头注意都使用 h h h个注意头并执行自注意机制。
Self-Attention. We describe the self-attention mechanism based on Shaw et al. (2018). In each attention head, the sequence of input vectors, x = ( x 1 , . . . , x n ) x =(x_1,...,x_n) x=(x1,...,xn) where x i ∈ R d m o d e l x_i∈R^{d_{model}} xi∈Rdmodel are transformed into the sequence of output vectors, o = (o1, . . . , on) where oi ∈ Rdk as:
自注意力机制. 我们描述了基于Shaw et al. (2018)的自注意机制。在每个注意力头中,将输入向量的序列 x = ( x 1 , . . . , x n ) x =(x_1,...,x_n) x=(x1,...,xn) 其中 x i ∈ R d m o d e l x_i∈R^{d_{model}} xi∈Rdmodel转换为输出向量的序列 o = ( o 1 , . . . , o n ) o=(o1,...,o_n) o=(o1,...,on),其中 o i ∈ R d k o_i∈R^{d_k} oi∈Rdk:
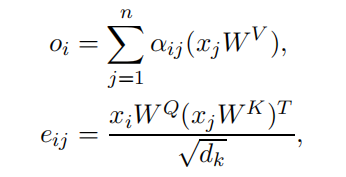
where α i j = e x p ( e i j ) ∑ k = 1 n e x p ( e i k ) α_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^nexp(e_{ik})} αij=∑k=1nexp(eik)exp(eij) and W Q W_Q WQ, W K ∈ R d m o d e l × d k W_K∈R^{d_{model}×d_k} WK∈Rdmodel×dk, W V ∈ R d m o d e l × d v W_V∈R^{d_{model}×d_v} WV∈Rdmodel×dv are the parameters that are unique per layer and attention head.
其中 α i j = e x p ( e i j ) ∑ k = 1 n e x p ( e i k ) α_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^nexp(e_{ik})} αij=∑k=1nexp(eik)exp(eij)且 W Q W_Q WQ, W K ∈ R d m o d e l × d k W_K∈R^{d_{model}×d_k} WK∈Rdmodel×dk, W V ∈ R d m o d e l × d v W_V∈R^{d_{model}×d_v} WV∈Rdmodel×dv是每层和注意力头唯一的参数。
Copy Attention. We incorporate the copying mechanism (See et al., 2017) in the Transformer to allow both generating words from vocabulary and copying from the input source code. We use an additional attention layer to learn the copy distribution on top of the decoder stack (Nishida et al., 2019). The copy attention enables the Transformer to copy rare tokens (e.g., function names, variable names) from source code and thus improves the summarization performance significantly (§ 3.2).
Copy Attention. 我们在Transformer中整合了复制机制 (See et al., 2017),以允许既根据词汇生成单词又根据输入源代码进行复制。我们使用额外的注意力层来学习解码器堆栈顶部的复制分布(Nishida et al., 2019)。Copy Attention使Transformer能够从源代码复制稀有标记(例如,函数名称,变量名称),从而显著提高摘要性能(第3.2节)。
2.2 位置表示
Now, we discuss how to learn the order of source code tokens or model their pairwise relationship.
现在,我们讨论如何学习源代码token的顺序或建模它们的成对关系。
Encoding absolute position. To allow the Transformer to utilize the order information of source code tokens, we train an embedding matrix W P e W^{Pe} WPe that learns to encode tokens’ absolute positions into vectors of dimension d m o d e l d_{model} dmodel. However, we show that capturing the order of code tokens is not helpful to learn source code representations and leads to poor summarization performance (§ 3.2).It is important to note that we train another embedding matrix W P d W^{Pd} WPd that learns to encode the absolute positions of summary tokens.(In this work, we do not study alternative ways of learning position representation for the summary tokens.)
编码绝对位置. 为了使Transformer利用源代码token的顺序信息,我们训练了一个嵌入矩阵 W P e W^{Pe} WPe,该矩阵学习将token的绝对位置编码为 d m o d e l d_{model} dmodel维的向量。但是,我们证明捕捉代码token的顺序对学习源代码表示形式无济于事,并且会导致摘要性能不佳(第3.2节)。重要的是要注意,我们训练了另一个嵌入矩阵 W P d W^{Pd} WPd,它学会编码摘要token的绝对位置(在这项工作中,我们不会研究摘要token的位置表示的替代方法)。
Encoding pairwise relationship. The semantic representation of a code does not rely on the absolute positions of its tokens. Instead, their mutual interactions influence the meaning of the source code. For instance, semantic meaning of the expressions a+b and b+a are the same.To encode the pairwise relationships between input elements, Shaw et al. (2018) extended the self-attention mechanism as follows.
编码成对关系. 代码的语义表示不依赖于其token的绝对位置。相反,它们之间的相互影响会影响源代码的含义。例如,表达式 a + b a + b a+b和 b + a b + a b+a的语义相同。为了对输入元素之间的成对关系进行编码,Shaw et al. (2018) 将自我注意机制扩展如下:
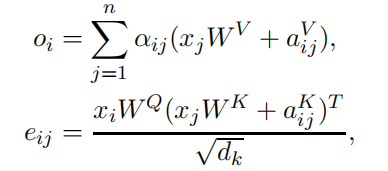
where, a V i j V_{ij} Vij and a K i j K_{ij} Kij are relative positional representations for the two position i and j. Shaw et al.(2018) suggested clipping the maximum relative position to a maximum absolute value of k as they hypothesize that precise relative position information is not useful beyond a certain distance.
其中, V i j V_{ij} Vij和 K i j K_{ij} Kij是两个位置 i i i和 j j j的相对位置表示。Shaw et al.(2018)建议将最大相对位置裁剪为k的最大绝对值,因为他们假设精确的相对位置信息在一定距离之外无用。


Hence, we learn 2 k + 1 2k + 1 2k+1 relative position representations: ( w − k K , . . . , w k K ) (w^K_{-k},...,w^K_k) (w−kK,...,wkK), and ( w − k V , . . . , w k V ) (w^V_{-k},...,w^V_k) (w−kV,...,wkV).In this work, we study an alternative of the relative position representations that ignores the directional information (Ahmad et al., 2019). In other words, the information whether the j’th token is on the left or right of the i’th token is ignored.
因此,我们学习了 2 k + 1 2k+1 2k+1个相对位置表示: ( w − k K , . . . , w k K ) (w^K_{-k},...,w^K_k) (w−kK,...,wkK)和 ( w − k V , . . . , w k V ) (w^V_{-k},...,w^V_k) (w−kV,...,wkV)。在这项工作中,我们研究了忽略方向信息的相对位置表示的替代方法(Ahmad et al., 2019)。换句话说,第 j j j个token位于第 i i i个token的左侧还是右侧的信息将被忽略。

3 实验
3.1 设置
Datasets and Pre-processing. We conduct our experiments on a Java dataset (Hu et al., 2018b) and a Python dataset (Wan et al., 2018). The statistics of the two datasets are shown in Table 1. In addition to the pre-processing steps followed by Wei et al. (2019), we split source code tokens of the form CamelCase and snake case to respective sub-tokens(The CamelCase and snake_case tokenization reduces the vocabulary significantly. For example, the number of unique tokens in Java source code reduced from 292,626 to 66,650) . We show that such a split of code tokens improves the summarization performance.
数据集和预处理。我们在Java数据集(Hu et al., 2018b)和Python数据集 (Wan et al., 2018)上进行实验。这两个数据集的统计数据如表1所示。除了Wei et al. (2019)的预处理步骤,我们将CamelCase和snake_case形式的源代码token拆分为相应的sub-tokens(CamelCase和snake_case token化显著减少了词汇量。例如,Java源代码中唯一token的数量从292,626减少到66,650)。我们证明了这样的代码token拆分可以提高汇总性能。

Metrics. We evaluate the source code summarization performance using three metrics, BLEU (Papineni et al., 2002), METEOR (Banerjee and Lavie, 2005), and ROUGE-L (Lin, 2004).
指标。我们使用BLEU (Papineni et al., 2002),METEOR (Banerjee and Lavie, 2005)和ROUGE-L(Lin, 2004)这三个指标来评估源代码摘要性能。
Baselines. We compare our Transformer-based source code summarization approach with five baseline methods reported in Wei et al. (2019) and their proposed Dual model. We refer the readers to (Wei et al., 2019) for the details about the hyperparameter of all the baseline methods.
基线。我们将基于Transformer的源代码摘要方法与Wei et al. (2019)报告的五种基线方法及其提出的对偶模型进行了比较。我们请读者参考(Wei et al., 2019)有关所有基线方法的超参数的详细信息。
Hyper-parameters. We follow Wei et al. (2019) to set the maximum lengths and vocabulary sizes for code and summaries in both the datasets. We train the Transformer models using Adam optimizer (Kingma and Ba, 2015) with an initial learning rate of 10−4 . We set the mini-batch size and dropout rate to 32 and 0.2, respectively. We train the Transformer models for a maximum of 200 epochs and perform early stop if the validation performance does not improve for 20 consecutive iterations. We use a beam search during inference and set the beam size to 4. Detailed hyperparameter settings can be found in Appendix A.
超参数。我们遵循 Wei et al. (2019) 设置两个数据集中代码和摘要的最大长度和词汇量。我们使用Adam优化器 (Kingma and Ba, 2015)训练Transformer模型,初始学习率为 1 0 − 4 10^{−4} 10−4。我们将最小batch-size和dropout分别设置为32和0.2。我们最多对Transformer模型进行200个epoch的训练,如果连续20次迭代的验证性能没有提高,则会执行early stop。我们在inference期间使用波束搜索,并将波束大小设置为4。详细的超参数设置可以在附录A中找到。
3.2 结果与分析
Overall results. The overall results of our proposed model and baselines are presented in Table 2. The result shows that the Base model outperforms the baselines (except for ROUGE-L in java), while the Full model improves the performance further(We observe a more significant gain on the Python dataset and a detailed discussion on it is provided in Appendix B). We ran the Base model on the original datasets (without splitting the CamelCase and snake case code tokens) and observed that the performance drops by 0.60, 0.72 BLEU and 1.66, 2.09 ROUGE-L points for the Java and Python datasets respectively. We provide a few qualitative examples in Appendix C showing the usefulness of the Full model over the Base model.
总体结果。表2列出了我们提出的模型和基准的总体结果。结果表明,Base模型的性能优于基准(Java中的ROUGE-L除外),而Full模型则进一步提高了性能(我们在Python数据集上观察到了更大的收益,附录B提供了有关它的详细讨论)。我们运行了Base模型原始数据集上的数据(不拆分CamelCase和snake_case代码的token),观察到Java和Python数据集的BLEU和ROUGE-L性能分别下降了0.60、0.72 和1.66、2.09。我们在附录C中提供了一些定性示例,这些示例显示了Full模型相对于Base模型的有用性。

Unlike the baseline approaches, our proposed model employs the copy attention mechanism. As shown in Table 2, the copy attention improves the performance 0.44 and 0.88 BLEU points for the Java and Python datasets respectively.
与基线方法不同,我们提出的模型采用了复制注意力机制。如表2所示,复制注意力分别提高了Java和Python数据集的性能0.44和0.88 BLEU点。
Impact of position representation. We perform an ablation study to investigate the benefits of encoding the absolute position of code tokens or modeling their pairwise relationship for the source code summarization task, and the results are presented in Table 3 and 4. Table 3 demonstrates that learning the absolute position of code tokens are not effective as we can see it slightly hurts the performance compared to when it is excluded. This empirical finding corroborates the design choice of Iyer et al. (2016), where they did not use the sequence information of the source code tokens.
位置表示的影响。我们进行了消融研究,以研究编码代码token的绝对位置或对源代码摘要任务进行建模它们的成对关系的好处,结果如表3和表4所示。表3证明了学习代码的绝对位置token无效,因为我们可以看到,与当被排除时相比,存在绝对位置token会稍微影响性能。这一经验性的发现证实了 Iyer et al. (2016)的设计选择,他们没有使用源代码token的序列信息。

On the other hand, we observe that learning the pairwise relationship between source code tokens via relative position representations helps as Table 4 demonstrates higher performance. We vary the clipping distance, k, and consider ignoring the directional information while modeling the pairwise relationship. The empirical results suggest that the directional information is indeed important while 16, 32, and 2 i relative distances result in similar performance (in both experimental datasets).
另一方面,我们观察到,通过相对位置表示来学习源代码token之间的成对关系会有所帮助,因为表4展示了更高的性能。我们改变裁剪距离 k k k,并在对成对关系建模时考虑忽略方向信息。实验结果表明方向信息的确很重要,而16、32和 2 i 2^i 2i的相对距离会得到相似的性能(在两个实验数据集中)。
Varying model size and number of layers. We perform ablation study by varying dmodel and l and the results are presented in Table 5 (Considering the model complexity, we do not increase the model size or number of layers further). In our experiments, we observe that a deeper model (more layers) performs better than a wider model (larger dmodel). Intuitively, the source code summarization task depends on more semantic information than syntactic, and thus deeper model helps.
不同的模型大小和层数。我们通过改变 d m o d e l d_{model} dmodel和 l l l进行消融研究,结果显示在表5中(考虑到模型的复杂性,我们不再增加模型的大小或层数)。在我们的实验中,我们观察到较深的模型(更多的层)比较宽的模型(较大的 d m o d e l d_{model} dmodel表现更好。直观上,源代码摘要任务依赖于更多的语义信息而不是句法,因此更深层次的模型会有所帮助。

Use of Abstract Syntax Tree (AST). We perform additional experiments to employ the abstract syntax tree (AST) structure of source code in the Transformer. We follow Hu et al. (2018a) and use the Structure-based Traversal (SBT) technique to transform the AST structure into a linear sequence. We keep our proposed Transformer architecture intact, except in the copy attention mechanism, we use a mask to block copying the non-terminal tokens from the input sequence. It is important to note that, with and without AST, the average length of the input code sequences is 172 and 120, respectively. Since the complexity of the Transformer is O(n 2 × d) where n is the input sequence length, hence, the use of AST comes with an additional cost. Our experimental findings suggest that the incorporation of AST information in the Transformer does not result in an improvement in source code summarization. We hypothesize that the exploitation of the code structure information in summarization has limited advantage, and it diminishes as the Transformer learns it implicitly with relative position representation.
抽象语法树(AST)的使用。我们执行其他实验,以在Transformer中采用源代码的抽象语法树(AST)结构。我们遵循Hu et al. (2018a),并使用基于结构的遍历(SBT)技术将AST结构转换为线性序列。我们保持我们的Transformer架构不变,除了在复制注意力机制中,我们使用掩码来阻止从输入序列复制非终端token。重要的是要注意,无论是否使用AST,输入代码序列的平均长度分别为172和120。由于Transformer的复杂度为 O ( n 2 × d ) O(n^2×d) O(n2×d),其中n为输入序列长度,因此,使用AST会产生额外的成本。我们的实验结果表明,将AST信息合并到Transformer中不会导致源代码摘要的改进。我们假设在摘要中利用代码结构信息的优势是有限的,当Transformer通过相对位置表示隐式地学习它时,这种优势就会减弱。
Qualitative analysis. We provide a couple of examples in Table 6 to demonstrate the usefulness of our proposed approach qualitatively (more examples are provided in Table 9 and 10 in the Appendix). The qualitative analysis reveals that, in comparison to the Vanilla Transformer model, the copy enabled model generates shorter summaries with more accurate keywords. Besides, we observe that in a copy enabled model, frequent tokens in the code snippet get a higher copy probability when relative position representations are used, in comparison to absolute position representations. We suspect this is due to the flexibility of learning the relation between code tokens without relying on their absolute position.
定性分析。我们在表6中提供了一些示例,以定性地证明我们提出的方法的有用性(附录中的表9和表10中提供了更多示例)。定性分析表明,与Vanilla Transformer模型相比,支持复制注意力机制的模型生成的摘要更短,关键字更准确。此外,我们观察到在复制模型中,与绝对位置表示相比,当使用相对位置表示时,代码片段中的频率token获得较高的复制概率。我们怀疑这是由于在不依赖于它们的绝对位置的情况下学习代码token之间的关系的灵活性。

4 相关工作
Most of the neural source code summarization approaches frame the problem as a sequence generation task and use recurrent encoderdecoder networks with attention mechanisms as the fundamental building blocks (Iyer et al., 2016; Liang and Zhu, 2018; Hu et al., 2018a,b). Different from these works, Allamanis et al. (2016) proposed a convolutional attention model to summarize the source codes into short, name-like summaries.
大多数神经网络源代码摘要生成方法将问题框架化为序列生成任务,并使用具有注意力机制的循环编码器-解码器网络作为基本构建块(Iyer et al., 2016; Liang and Zhu, 2018; Hu et al., 2018a,b)。与这些工作不同的是,Allamanis et al. (2016)提出了卷积注意力模型,将源代码总结为简短的,类似名称的摘要。
Recent works in code summarization utilize structural information of a program in the form of Abstract Syntax Tree (AST) that can be encoded using tree structure encoders such as Tree-LSTM (Shido et al., 2019), TreeTransformer (Harer et al., 2019), and Graph Neural Network (LeClair et al., 2020). In contrast, Hu et al. (2018a) proposed a structure based traversal (SBT) method to flatten the AST into a sequence and showed improvement over the AST based methods. Later, LeClair et al. (2019) used the SBT method and decoupled the code structure from the code tokens to learn better structure representation.
代码摘要方面的最新工作利用了抽象语法树(AST)形式的程序结构信息,可以使用诸如Tree-LSTM(Shido et al., 2019),TreeTransformer(Harer et al., 2019)和图神经网络 (LeClair et al., 2020)。相反, Hu et al. (2018a)提出了一种基于结构的遍历(SBT)方法将AST展平为序列,并显示出比基于AST的方法有所改进。后来,LeClair et al. (2019) 使用SBT方法并将代码结构与代码token分离,以学习更好的结构表示。
Among other noteworthy works, API usage information (Hu et al., 2018b), reinforcement learning (Wan et al., 2018), dual learning (Wei et al., 2019), retrieval-based techniques (Zhang et al., 2020) are leveraged to further enhance the code summarization models. We can enhance a Transformer with previously proposed techniques; however, in this work, we limit ourselves to study different design choices for a Transformer without breaking its’ core architectural design philosophy.
其他值得注意的工作包括 API usage information (Hu et al., 2018b),强化学习(Wan et al., 2018),双重学习 (Wei et al., 2019),基于检索的技术 (Zhang et al., 2020)用于进一步增强代码摘要模型。我们可以使用先前提出的技术来增强Transformer; 但是,在这项工作中,我们限制自己研究Transformer的不同设计选择,而不破坏其核心架构的设计理念。
5 结论
This paper empirically investigates the advantage of using the Transformer model for the source code summarization task. We demonstrate that the Transformer with relative position representations and copy attention outperforms state-of-the-art approaches by a large margin. In our future work, we want to study the effective incorporation of code structure into the Transformer and apply the techniques in other software engineering sequence generation tasks (e.g., commit message generation for source code changes).
本文通过经验研究了将Transformer模型用于源代码摘要任务的优势。我们证明了具有相对位置表示和复制注意的Transformer在很大程度上优于最新方法。在未来的工作中,我们希望研究将代码结构有效地整合到Transformer中,并将该技术应用于其他软件工程序列生成任务(例如,为源代码更改提供消息生成)。
致谢
This work was supported in part by National Science Foundation Grant OAC 1920462, CCF 1845893, CCF 1822965, CNS 1842456.
这项工作得到了美国国家科学基金会Grant OAC 1920462,CCF 1845893,CCF 1822965,CNS 1842456的部分支持。
附录
A 超参数
表7总结了我们在实验中使用的超参数

B 循环编码器-解码器vs.Python数据集上的Transformer
While conducting our study using the Transformer on the Python dataset, we observed a significant gain over the state-of-the-art methods as reported in Wei et al. (2019). However, our initial experiments on this dataset using recurrent sequence-to-sequence models also demonstrated higher performance compared to the results report in Wei et al. (2019). We suspect that such lower performance is due to not tuning the hyperparameters correctly. So for the sake of fairness and to investigate the true advantages of Transformer, we present a comparison on recurrent Seq2seq model and Transformer in Table 8 using our implementation.
在使用Python数据集上的Transformer进行我们的研究时,我们观察到与Wei et al. (2019)报告的最先进的方法相比有重大的收获。然而,我们使用循环sequence-to-sequence模型对该数据集进行的初始实验也显示了比Wei et al. (2019)报告的结果更高的性能。我们怀疑这种低性能是由于没有正确地调优超参数。因此,为了公平起见,也为了研究Transformer的真正优点,我们利用我们的实现,对表8中的Transformer与循环Seq2seq模型进行了比较。(我们的实现基于Open-NMT (Klein et al., 2017) 和PyTorch 1.3)

We can see from Table 8, the performance of the recurrent Seq2seq model is much better than the results reported in prior works. However, to our surprise, the copy attention mechanism does not result in improvement for the recurrent Seq2seq model. When we looked into the training perplexity and the validation performance, we also observed lower performance in comparison to the base recurrent Seq2seq model. In comparison, our proposed Transformer-based approach outperforms the recurrent Seq2seq models by a large margin showing its effectiveness for source code summarization.
从表8中我们可以看到,循环Seq2seq模型的性能比以前的工作报告的结果要好得多。但是,令我们惊讶的是,复制注意力机制并未对循环Seq2seq模型产生改善。当我们研究训练的perplexity和验证集的性能时,与基本的递归Seq2seq模型相比,我们还发现性能较低。相比之下,我们提出的基于Transformer的方法在很大程度上优于循环Seq2seq模型,显示了其对源代码摘要的有效性。
C 定性例子





参考文献
Wasi Ahmad, Zhisong Zhang, Xuezhe Ma, Eduard Hovy, Kai-Wei Chang, and Nanyun Peng. 2019. On difficulties of cross-lingual transfer with order differences: A case study on dependency parsing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota. Association for Computational Linguistics.
Miltiadis Allamanis, Hao Peng, and Charles A. Sutton. 2016. A convolutional attention network for extreme summarization of source code. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, volume 48 of JMLR Workshop and Conference Proceedings, pages 2091– 2100. JMLR.org.
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, Michigan.Association for Computational Linguistics.
Akiko Eriguchi, Kazuma Hashimoto, and Yoshimasa Tsuruoka. 2016. Tree-to-sequence attentional neural machine translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany. Association for Computational Linguistics.
Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia. Association for Computational Linguistics.
Jacob Harer, Chris Reale, and Peter Chin. 2019. Treetransformer: A transformer-based method for correction of tree-structured data. arXiv preprint arXiv:1908.00449.
Xing Hu, Ge Li, Xin Xia, David Lo, and Zhi Jin. 2018a. Deep code comment generation. New York, NY, USA. Association for Computing Machinery.
Xing Hu, Ge Li, Xin Xia, David Lo, Shuai Lu, and Zhi Jin. 2018b. Summarizing source code with transferred api knowledge. In Proceedings of the TwentySeventh International Joint Conference on Artificial Intelligence, IJCAI-18, pages 2269–2275. International Joint Conferences on Artificial Intelligence Organization.
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Summarizing source code using a neural attention model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany. Association for Computational Linguistics.
Diederik P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In International Conference on Learning Representations.
Guillaume Klein, Yoon Kim, Yuntian Deng, Jean Senellart, and Alexander Rush. 2017. OpenNMT: Open-source toolkit for neural machine translation. In Proceedings of ACL 2017, System Demonstrations, Vancouver, Canada. Association for Computational Linguistics.
Alexander LeClair, Sakib Haque, Linfgei Wu, and Collin McMillan. 2020. Improved code summarization via a graph neural network. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
Alexander LeClair, Siyuan Jiang, and Collin McMillan. 2019. A neural model for generating natural language summaries of program subroutines. IEEE Press.
Yuding Liang and Kenny Qili Zhu. 2018. Automatic generation of text descriptive comments for code blocks. In Thirty-Second AAAI Conference on Artificial Intelligence.
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, Barcelona, Spain. Association for Computational Linguistics.
Thang Luong, Hieu Pham, and Christopher D. Manning. 2015. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal. Association for Computational Linguistics.
Kyosuke Nishida, Itsumi Saito, Kosuke Nishida, Kazutoshi Shinoda, Atsushi Otsuka, Hisako Asano, and Junji Tomita. 2019. Multi-style generative reading comprehension. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy. Association for Computational Linguistics.
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
Abigail See, Peter J. Liu, and Christopher D. Manning. 2017.Get to the point: Summarization with pointergenerator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada. Association for Computational Linguistics.
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018.Self-attention with relative position representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, Louisiana. Association for Computational Linguistics.
Yusuke Shido, Yasuaki Kobayashi, Akihiro Yamamoto, Atsushi Miyamoto, and Tadayuki Matsumura. 2019.Automatic source code summarization with extended tree-lstm. In 2019 International Joint Conference on Neural Networks (IJCNN), pages 1–8.IEEE.
Vighnesh Shiv and Chris Quirk. 2019. Novel positional encodings to enable tree-based transformers. In Advances in Neural Information Processing Systems 32, pages 12081–12091. Curran Associates, Inc.
Giriprasad Sridhara, Emily Hill, Divya Muppaneni, Lori Pollock, and K. Vijay-Shanker. 2010. Towards automatically generating summary comments for java methods. New York, NY, USA. Association for Computing Machinery.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems 27, pages 3104–3112. Curran Associates, Inc.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30, pages 5998–6008. Curran Associates, Inc.
Yao Wan, Zhou Zhao, Min Yang, Guandong Xu, Haochao Ying, Jian Wu, and Philip S Yu. 2018. Improving automatic source code summarization via deep reinforcement learning. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, pages 397–407. ACM.
Qiang Wang, Bei Li, Tong Xiao, Jingbo Zhu, Changliang Li, Derek F. Wong, and Lidia S. Chao. 2019. Learning deep transformer models for machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy. Association for Computational Linguistics.
Bolin Wei, Ge Li, Xin Xia, Zhiyi Fu, and Zhi Jin. 2019. Code generation as a dual task of code summarization. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alch´e-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 6563–6573. Curran Associates, Inc.
Xin Xia, Lingfeng Bao, David Lo, Zhenchang Xing, Ahmed E. Hassan, and Shanping Li. 2018. Measuring program comprehension: A large-scale field study with professionals. New York, NY, USA. Association for Computing Machinery.
Yongjian You, Weijia Jia, Tianyi Liu, and Wenmian Yang. 2019. Improving abstractive document summarization with salient information modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy. Association for Computational Linguistics.
Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, and Xudong Liu. 2020. Retrieval-based neural source code summarization. In Proceedings of the 42nd International Conference on Software Engineering. IEEE.
再次感谢您的阅读,祝您工作顺利,万事如意。
















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











