






在这篇博客中,主要是收集到一些图像融合框架中引入Transformer结构的文章,提供给大家参考学习,目前图像融合领域引入Transformer结构的文章比较少(我所看到的比较少,也看可能我看的比较少?),主要作用就是把它作为一种提取特征的方式,或者说更倾向于long-range dependencies的建立。Transformer引入到图像融合领域的时间并不长,大部分文章都是2020-2022发出的,所有并没有统计发表年份。至于是具体是哪个会议或者期刊发表的并没有标注,有兴趣可以自己去查查。
Transformer 主要是通过自注意力学习图像斑块之间的全局空间关系。 自注意力机制致力于建立long-range dependencies,从而在浅层和深层中更好地利用全局信息,所以 Transformer 的使用就是解决长序列问题的一个好方法。在 CV 领域中常用的就是 CNN,它可以提取本地的特征,因为每次卷积就是提取该卷积下的特征图,在局部信息的提取上有很大优势,但无法关注图像的长期依赖关系,阻碍了复杂场景融合的上下文信息提取。所以, Transformer 的引入主要解决这个问题。
下面这个思维导图从单任务和多任务的角度进行设计的,简单看看吧!!!
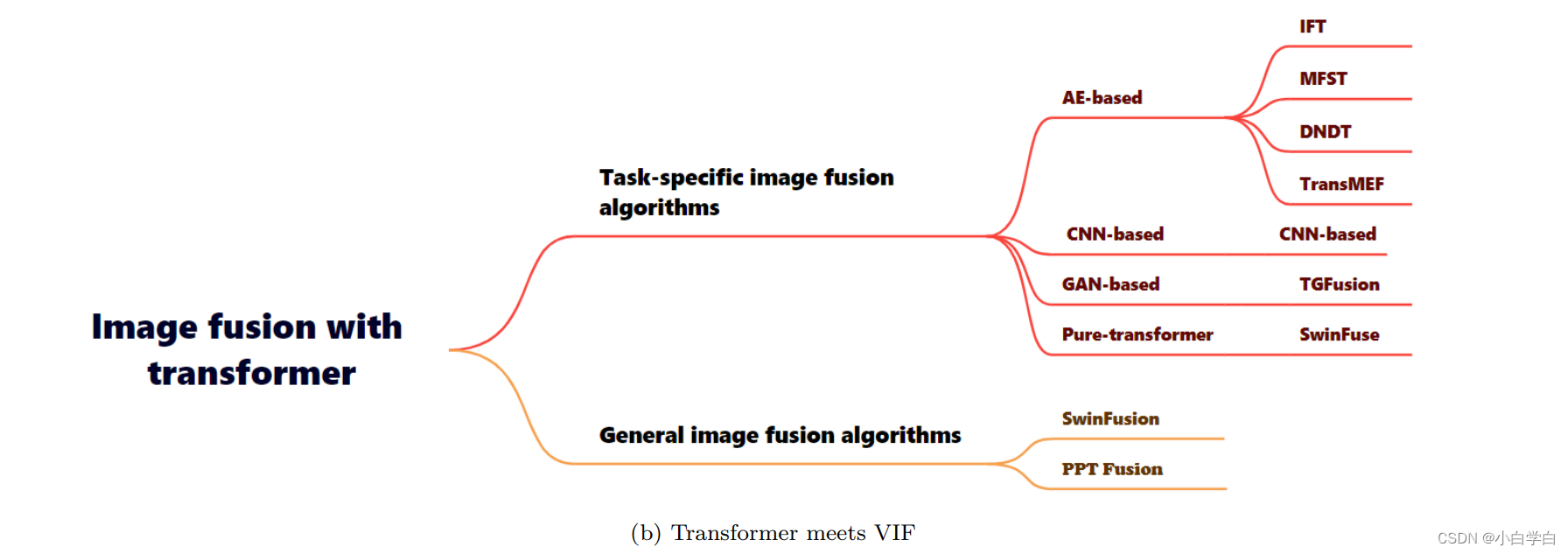
下面这个表格是论文的名称,以及在网络结构上进行了总结。
| CNN+Transformer结构 | ||
| 文章 | 类型 | 代码 |
| Image Fusion Transformer | VIF | 文中提供了代码链接 |
| MFST: Multi-Modal Feature Self-Adaptive Transformer for Infrared and Visible Image Fusion | VIF | |
| DNDT: Infrared and Visible Image Fusion Via DenseNet and Dual-Transformer | VIF | |
| TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning | MEF | 文中提供了代码链接 |
| TransFuse: A Unified Transformer-based Image Fusion Framework using Self-supervised Learning | Unified Framework | 文中提供了代码链接 |
| TGFuse: An Infrared and Visible Image Fusion Approach Based on Transformer and Generative Adversarial Network | VIF | |
| SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer | Unified Framework | 文中提供了代码链接 |
| CGTF: Convolution-Guided Transformer for Infrared and Visible Image Fusion | VIF | |
| Pure Transformer结构(这两篇都是预训练模型做的) | ||
| SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images | VIF | 文中提供了代码链接 |
| PPT Fusion: Pyramid Patch Transformer for a Case Study in Image Fusion | Unified Framework | |
| 新增 | ||
| THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor | VIF | |
| IFormerFusion: Cross-Domain Frequency Information Learning for Infrared and Visible Image Fusion Based on the Inception Transformer | VIF | |
| Breaking Free from Fusion Rule: A Fully Semantic-driven Infrared and Visible Image Fusion | VIF | |
| 扩散模型 | ||
| Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion Models | VIF,扩散彩色通道特征 | |
| 2023.11.28新增顶会、顶刊 | ||
| CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion | +Transformer | CVPR23 |
| MetaFusion: Infrared and Visible lmage Fusion via Meta-Feature Embedding from Object Detection | +目标检测 | CVPR23 |
| Deep Convolutional Sparse Coding Networks for Interpretable Image Fusion | Unified Framework | CVPR |
| Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation | +语义分割 | ICCV23 |
| DDFM: Denoising Diffusion Model for Multi-Modality Image Fusion | +GAN+扩散模型 | ICCV23 |
| Bi-level Dynamic Learning for Jointly Multi-modality Image Fusion and Beyond | +语义分割 | IJCAI23 |
| LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images | VIF | TPAMI23 |
| CoCoNet: Coupled Contrastive Learning Network with Multi-level Feature Ensemble for Multi-modality Image Fusion | +耦合对比 | IJCV23 |
| An Interactively Reinforced Paradigm for Joint Infrared-Visible Image Fusion and Saliency Object Detection | +显著性目标检测 | InF23 |
上述论文的实验部分都是比较的卷积方法或者传统方法,并没有比较到使用到Transforme的模型,所以他们之间的是啥情况,那就不清楚了,没刻意去比较过,有兴趣可以去比较比较。That thing is not sure!!!
思考:怎么把Tranformer合理的引入到CNN结构中进行图像融合以及如何真正地将Transformer用到图像融合融合中(完全使用Transformer去构建图像融合模型) ???
目前,只收集到这些文章。。如有错误,希望大家看到后及时在评论区留言!!!
2023.3.17新增、扩散模型!!!
2023/11/28 结合相关任务相关成主流了???
新增!!!顶会、顶刊相关论文!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









