







Adaboost算法及其代码实现
算法概述
AdaBoost(adaptive boosting),即自适应提升算法。
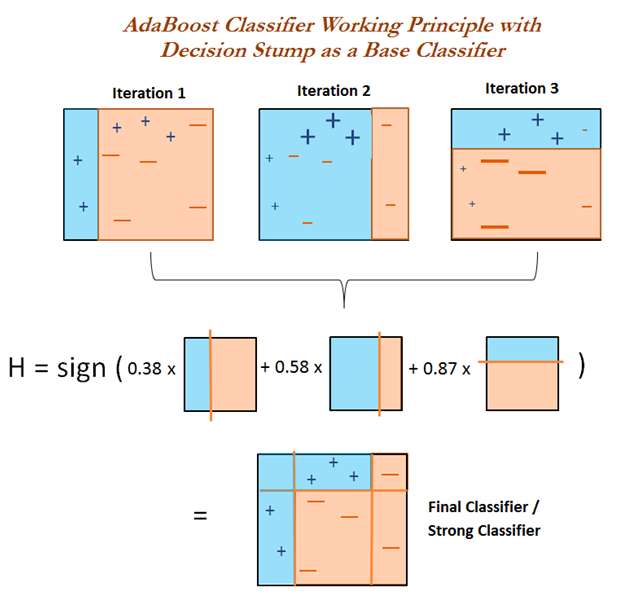
Boosting 是一类算法的总称,这类算法的特点是通过训练若干弱分类器,然后将弱分类器组合成强分类器进行分类。
为什么要这样做呢?因为弱分类器训练起来很容易,将弱分类器集成起来,往往可以得到很好的效果。
俗话说,"三个臭皮匠,顶个诸葛亮",就是这个道理。
这类 boosting 算法的特点是各个弱分类器之间是串行训练的,当前弱分类器的训练依赖于上一轮弱分类器的训练结果。
各个弱分类器的权重是不同的,效果好的弱分类器的权重大,效果差的弱分类器的权重小。
值得注意的是,AdaBoost 不止适用于分类模型,也可以用来训练回归模型。
这需要将弱分类器替换成回归模型,并改动损失函数。
$几个概念
强学习算法:正确率很高的学习算法;
弱学习算法:正确率很低的学习算法,仅仅比随机猜测略好。
弱分类器:通过弱学习算法得到的分类器, 又叫基本分类器;
强分类器:多个弱分类器按照权值组合而成的分类器。
$提升方法专注两个问题:
1.每一轮如何改变训练数据的权值或者概率分布:
Adaboost的做法是提高被分类错误的训练数据的权值,而提高被分类错误的训练数据的权值。
这样,被分类错误的训练数据会得到下一次弱学习算法的重视。
2.弱组合器如何构成一个强分类器
加权多数表决。
每一个弱分类器都有一个权值,该分类器的误差越小,对应的权值越大,因为他越重要。
算法流程
给定二分类训练数据集:
$T = {(x_1, y_1), (x_2, y_2), ... , (x_n, y_n)}$
和弱学习算法
目标:得到分类器\(G(x)\)
1.初始化权重分布:
一开始所有的训练数据都赋有同样的权值,平等对待。
$D_1 = (w_{11}, w_{12}, ... , w_{1n})$, $w_{1i} = \frac{1}{N}$, $i = 1, 2, ... , N$
### 2.权值的更新
设总共有M个弱分类器,m为第m个弱分类器, $m = 1, 2, ... , M$
(1)第m次在具有$D_m$权值分布的训练数据上进行学习,得到弱分类器$G_m(x)$。
这个时候训练数据的权值:$D_m = (w_{m, 1}, w_{m, 2}, ... , w_{m, n})$, $i = 1, 2, ... , N$
(2)计算$Gm(x)$在该训练数据上的**分类误差率**:
注:I函数单位误差函数
**分类误差率**:$e_m = \sum^{N}_{i = 1} w_i I (G_m(x_i) \neq y_i)$
(3)计算$G_(x)$的系数:
$\alpha_m = \frac 1 2 \ln \frac{1 - e_m}{e_m}$
(4)更新训练数据的权值:
$D
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









