






导读
安装完Hadoop集群才是第一步,配置和管理集群也将是我们面临的挑战。大数据平台涉及的组件多,加之,当数据量由少量变为海量时,一些在通常情况下不会出现的问题也会暴露出来,这就要求我们多多专研集群配置及管理经验,并及时地将这些经验加以总结归纳并记录下来。下面列举了几个笔者在实践中总结的经验,希望对大家有帮助
1 zookeeper无法启动
更改存储数据的文件夹后,发现没法启动,例如:默认的配置文件夹是/var/lib/zookeeper
当配置变为:
/home/var/lib/zookeeper
由于version-2文件夹不存在,解决的办法是:
第一种:手动创建version-2并分配用户和组。
第二种:修改配置

可以设置完以后将其取消,在重启。
2 NameNode is not formatted
HDFS更改数据存储目录后有可能报错NameNode is not formatted,解决的办法是:
找到NameNode配置页
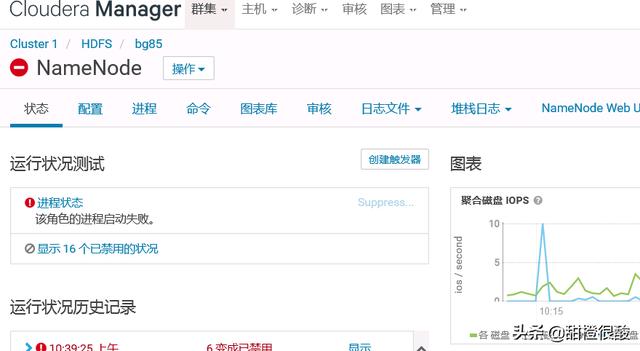
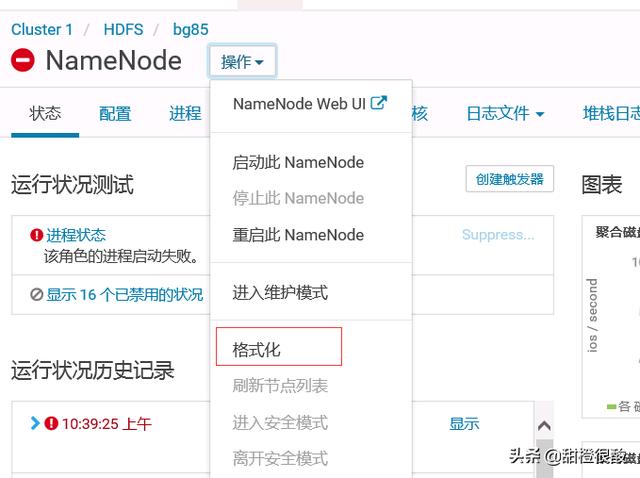
点击操作,选择格式化:
3更改目录Spark History Server无法启动:
报错:/home/user/spark/applicationHistory目录不存在。
解决办法:创建。
先看看根目录下的内容:hadoop fs -ls /

创建一堆目录:
sudo -u hdfs hadoop fs -mkdir /home/user
sudo -u hdfs hadoop fs -mkdir /home/user/spark
sudo -u hdfs hadoop fs -mkdir /home/user/spark/applicationHistory
sudo -u hdfs hadoop fs -chown -R spark:spark /home/user/spark/applicationHistory
4 hue hdfs /user/admin 不存在
更改配置后会报这种错误,创建这个目录即可。
5 找不到mapreduce框架
提交MapReduce任务报错:
Exception in thread "main" java.io.FileNotFoundException: File does not exist: hdfs://bg85.cnki.com:8020/user/yarn/mapreduce/mr-framework/3.0.0-cdh6.0.0-mr-framework.tar.gz
解决办法:
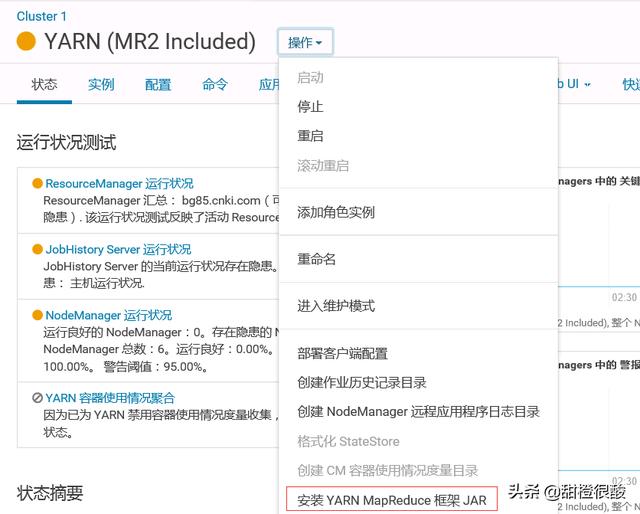
进入Yarn服务器,安装jar
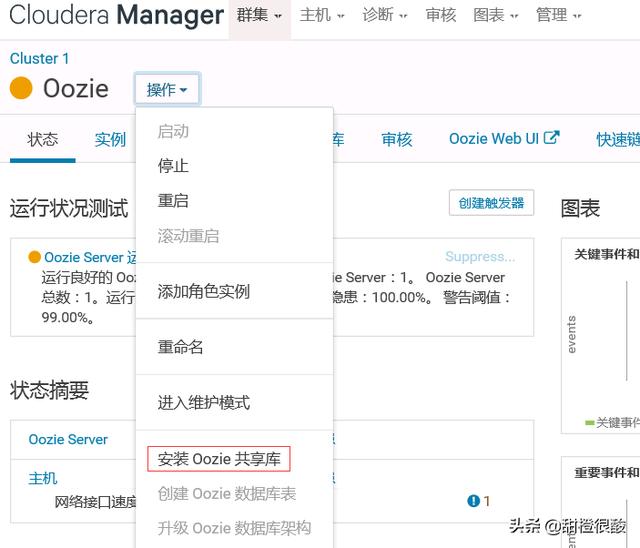
6 hue提交任务报错:Could not locate Oozie sharelib
点击安装共享库即可。
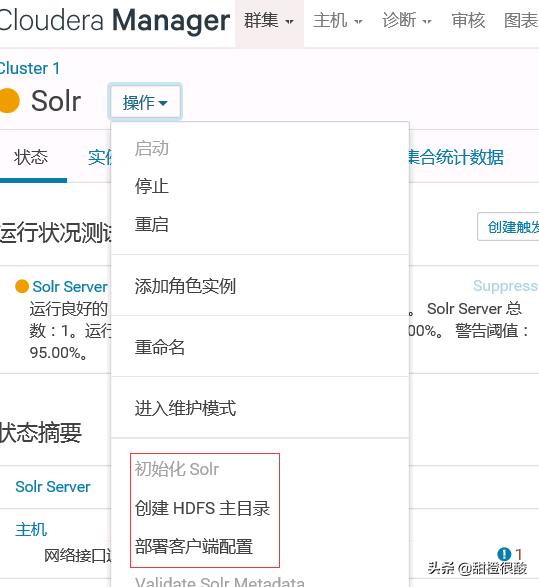
7 solr启动报错:
Failed to configure urlScheme property for Solr cluster in Zookeeper
解决办法:
根据情况,点击红框中的按钮,即可解决问题。














 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









