







前文回顾
这是全文第三章label correcting algorithm的第二节。本章围绕Label Correcting Algorithms展开。上一节已经介绍了最短路径算法Generic Label Correcting Algorithm以及Modified Label Correcting Algorithm,本节将介绍在前两个算法上改进得到的FIFO Label Correcting Algorithm以及Deque Label Correcting Algorithm。点击下方链接回顾往期内容:
最短路问题与标号算法(label setting algorithm)研究(1) - 开篇介绍
最短路问题与标号算法(label correcting algorithm)研究(2) - 最短路径问题简介
最短路问题与标号算法(label correcting algorithm)研究(3)

3.4 FIFO Label Correcting Algorithm
3.4.1 算法介绍
同样我们再次回顾一下Modified Label Correcting Algorithm的关键步骤:引入SE_LIST记录距离标签更新的节点编号,并在下一次迭代时检查SE_LIST内某一节点发出的所有弧,即表3-5第7行与第13行。我们可以看出算法并没有给出从SE_LIST中选择节点以及向SE_LIST添加节点的具体规则,因此我们在相应代码实现时以随机的方式选取节点,并将新的节点添加到SE_LIST的尾部,即表3-6第48-50行与58-60行,表3-7第49-52行与63-65行。这种随机方式是否会对算法效率产生影响呢?前边我们已经知道,当最大网络弧长非常大时Modified Label Correcting Algorithm的迭代次数为。现在假设我们其将应用到一个病态的数据集上(这类数据集往往含有非常大的值),且每次迭代时从SE_LIST中选取节点或向SE_LIST中添加节点的顺序不合适时,算法总的迭代次数会随着网络节点数成指数式增长。显然,为了保证算法效率的可靠性我们必须设计出较为合理的规则对SE_LIST中节点进行操作。这里介绍一种基于FIFO(FirstInFirstOut,先进先出)的节点处理规则,我们称其为FIFO Label Correcting Algorithm。
这里我们尝试对中的弧进行排序以解决Generic Label Correcting Algorithm中弧扫描规则不明确问题(或者说SE_LIST中节点操作顺序问题):将弧集合中的所有弧以某种特定的方式排序,然后在每次迭代中逐个检查中的弧,如果某条弧满足条件:,则更新相应的距离标签:,及节点的前向节点。当某步迭代后,中所有弧都满足最优性条件时,结束算法。 接下来我们回顾一下3.3.1小节的内容,在引入SE_LIST时我们提到只有当节点的距离标签更新时才需要在后续迭代时检查从节点发出的所有弧是否满足最优性条件。所以上述尝试还需进一步改进。 我们将弧集合中的弧按照它们的尾节点升排序,以便所有具有相同尾节点的弧都连续出现在集合中。这样在扫描弧时,我们可以一次考虑一个节点发出的所有弧,比如节点,扫描中的弧,并判断其是否满足最优性条件。假设在某次迭代遍历过程中,算法没有更新节点的距离标签,那么在下一步迭代中,始终存在,因此没有必要再次检查中的弧。 根据以上分析,我们同样引入可扫描列表SE_LIST,记录在一次迭代过程中距离标签发生更新的所有节点,并在下一次迭代中只考虑该列表中节点发出的所有弧。具体细节为:从SE_LIST一端(这里以左端为例)取出一个节点,检查中的所有弧是否满足最优性条件;从SE_LIST另一端(右端)添加新的节点以便后续迭代检查判断。我们称为FIFO规则,即先进先出。采用这类规则的算法称为FIFO Label Correcting Algorithm,其算法步骤如下:
3.4.2 算法实现
首先给出Python版本的FIFO Label Correcting Algorithm实现(求解附录2中源节点1到其他节点的最短路径)。"""导入相关基础包,定义全局变量"""import pandas as pdimport numpy as npimport copy
g_node_list=[] #网络节点集合
g_node_zone={} #网络节点类别集合
g_link_list=[] #网络弧集合
g_adjacent_arc_list={}#节点邻接弧集合(从节点i发出的弧集合)
g_shortest_path=[]#最短路径集合
g_node_status=[]#网络节点状态
g_number_of_nodes=0#网络节点个数
g_origin=None #网络源节点
node_predecessor=[]#前向节点集合
node_label_cost=[]#距离标签集合
SE_LIST=[]#可扫描节点集合
Max_label_cost=99999#初始距离标签"""导入网络数据文件,构建基础网络并初始化相关变量"""#读取网络节点数据
df_node=pd.read_csv('./input_file/node.csv')
df_node=df_node.iloc[:,:].valuesfor i in range(len(df_node)):
g_node_list.append(df_node[i,0])
g_node_zone[df_node[i, 0]] = df_node[i, -1]
g_number_of_nodes+=1
g_adjacent_arc_list[df_node[i,0]]=[]if df_node[i, 3] == 1:
g_origin = df_node[i, 0]
g_node_status=[0 for i in range(g_number_of_nodes)] #初始化网络节点状态
Distance=np.ones((g_number_of_nodes,g_number_of_nodes))\
*Max_label_cost #距离矩阵
node_predecessor=[-1]*g_number_of_nodes
node_label_cost=[Max_label_cost]*g_number_of_nodes
node_predecessor[g_origin-1]=0
node_label_cost[g_origin-1] = 0#读取网络弧数据
df_link=pd.read_csv('./input_file/road_link.csv')
df_link=df_link.iloc[:,:].valuesfor i in range(len(df_link)):
g_link_list.append((df_link[i,1],df_link[i,2]))
Distance[df_link[i,1]-1,df_link[i,2]-1]=df_link[i,3]
g_adjacent_arc_list[df_link[i,1]].append(df_link[i,2])
SE_LIST=[g_origin]
g_node_status[g_origin-1]=1"""最短路径求解:扫描网络弧,依据检查最优性条件更新距离标签"""while len(SE_LIST):
head=SE_LIST[0]#从可扫描列表中取出第一个元素
SE_LIST.pop(0)#从可扫描列表中删除第一个元素
g_node_status[head-1]=0
adjacent_arc_list=g_adjacent_arc_list[head]#获取当前节点的邻接弧集合for tail in adjacent_arc_list:if node_label_cost[tail-1]>\
node_label_cost[head-1]+Distance[head-1,tail-1]:
node_label_cost[tail-1]=\
node_label_cost[head-1]+Distance[head-1,tail-1]
node_predecessor[tail-1]=headif g_node_status[tail-1]==0:
SE_LIST.append(tail)#将新节点添加到可扫描列表尾部,append方法实现从列表尾部添加元素
g_node_status[tail-1]=1"""依据前向节点生成最短路径"""
agent_id=1
o_zone_id=g_node_zone[g_origin]for destination in g_node_list:if g_origin!=destination:
d_zone_id=g_node_zone[destination]if node_label_cost[destination-1]==Max_label_cost:
path=" "
g_shortest_path.append([agent_id, o_zone_id,d_zone_id,path, node_label_cost[destination - 1]])else:
to_node=copy.copy(destination)
path= "%s" % to_nodewhile node_predecessor[to_node-1]!=g_origin:
path="%s;"% node_predecessor[to_node - 1] + path
g=node_predecessor[to_node-1]
to_node=g
path="%s;"%g_origin+path
g_shortest_path.append([agent_id, o_zone_id,d_zone_id,path, node_label_cost[destination - 1]])
agent_id+=1"""将求解结果导出到csv文件"""#将数据转换为DataFrame格式方便导出csv文件
g_shortest_path=np.array(g_shortest_path)
col=['agent_id','o_zone_id','d_zone_id','node_sequence','distance']
file_data = pd.DataFrame(g_shortest_path, index=range(len(g_shortest_path)),columns=col)
file_data.to_csv('./3_fifo_label_correcting/agent.csv',index=False)%% clear
clc
clear
%% 设置变量
g_node_list = []; %网络节点集合
g_link_list = []; %网络弧集合
g_origin = []; %网络源节点
g_number_of_nodes = 0;%网络节点个数
node_predecessor = [];%前向节点集合
node_label_cost = [];%距离标签集合
Max_label_cost = inf; %初始距离标签
g_adjacent_arc_list={}; %节点邻接弧集合(从节点i发出的弧集合)
g_node_status=[]; %网络节点状态
SE_LIST=[]; %可扫描节点集合
%% 导入网络数据文件,构建基础网络并初始化相关变量
%读取网络节点数据
df_node = csvread('node.csv',1,0);
g_number_of_nodes = size(df_node,1);
g_node_list = df_node(:,1);
g_node_status = zeros(1,g_number_of_nodes);
for i = 1 : g_number_of_nodes
if df_node(i,4)==1
g_origin=df_node(i,1);
o_zone_id = df_node(i,5);
end
end
Distance = ones(g_number_of_nodes,g_number_of_nodes)*Max_label_cost;
%距离矩阵
node_predecessor = -1*ones(1,g_number_of_nodes);
node_label_cost = Max_label_cost*ones(1,g_number_of_nodes);
node_predecessor(1,g_origin) = 0;
node_label_cost(1,g_origin) = 0;
g_adjacent_arc_list = cell(1, g_number_of_nodes);
%读取网络弧数据
df_link = csvread('road_link.csv',1,0);
g_link_list = df_link(:,2:3);
for i = 1 : size(df_link, 1)
Distance(df_link(i,2),df_link(i,3)) = df_link(i,4);
g_adjacent_arc_list{df_link(i,2)} = [g_adjacent_arc_list{df_link(i,2)}, df_link(i,3)];
end
%% 最短路径求解:扫描网络弧,依据检查最优性条件更新距离标签
SE_LIST=[g_origin];
g_node_status(g_origin)=1;
while ~isempty(SE_LIST)
head=SE_LIST(1); %从可扫描列表中取出第一个元素
SE_LIST(1)=[]; %从可扫描列表中删除第一个元素
g_node_status(head)=0;
adjacent_arc_list = g_adjacent_arc_list(head);
%获取当前节点的邻接弧
adjacent_arc_list = cell2mat(adjacent_arc_list);
for i = 1 : length(adjacent_arc_list)
tail = adjacent_arc_list(i);
if node_label_cost(tail)>…
node_label_cost(head)+Distance(head,tail)
node_label_cost(tail)=…
node_label_cost(head)+Distance(head,tail);
node_predecessor(tail)=head;
if g_node_status(tail)==0
SE_LIST = [SE_LIST,tail];
g_node_status(tail) = 1;
end
end
end
end
%% 依据前向节点生成最短路径
distance_column = [];
path_column = {};
o_zone_id_column = o_zone_id * ones(g_number_of_nodes-1, 1);
d_zone_id_column = [];
agent_id_column = [1:(g_number_of_nodes-1)]';
for i = 1: size(g_node_list, 1)
destination = g_node_list(i);
if g_origin ~= destination
d_zone_id_column = [d_zone_id_column; df_node(i,5)];
if node_label_cost(destination)==Max_label_cost
path="";
distance = 99999;
distance_column = [distance_column; 99999];else
to_node=destination;
path=num2str(to_node);
while node_predecessor(to_node)~=g_origin
path=strcat(';',path);
path=strcat(num2str(node_predecessor(to_node)),path);
g=node_predecessor(to_node);
to_node=g;
end
path=strcat(';',path);
path=strcat(num2str(g_origin),path);
distance_column = [distance_column; node_label_cost(i)];
end
path_column=[path_column;path];
end
end
title = {'agent_id','o_zone_id','d_zone_id','node_sequence','distance'};
result_table=table(agent_id_column,o_zone_id_column,…
d_zone_id_column,path_column,distance_column,'VariableNames',title);
writetable(result_table, 'agent.csv',…
'Delimiter',',','QuoteStrings',true)3.5 Deque Label Correcting Algorithm
3.5.1算法介绍
同样,我们先回顾一下已学的三个Label Correcting Algorithms的特点:Generic Label Correcting Algorithm提出了一种新的算法框架,即Label Correcting,它允许我们以更有效、灵活的方式求解最短路问题,但它的灵活性也正是它缺点,由于规则的缺失导致算法效率不能保证;因此Modified Label Correcting Algorithm引入了可扫描列表SE_LIST来明确应该扫描哪些弧,算法虽有改进但却带来了新的问题,以何种规则处理SE_LIST中节点?最后FIFO Label Correcting Algorithm提出了FIFO规则来明确SE_LIST中节点的操作规则,即表3-8第7行和第13行,在相应代码实现中体现在表3-9第46-48行和第56-59行,表3-10第49-51行和第62-64行。这里请思考下除了FIFO是最好的么?还有其他规则可以选择么? 接下来我们介绍另一种规则:将SE_LIST作为Deque处理。如图3-4(a)所示,Deuqe以Left-front标记队列的左端头部,Left-rear标记队列的左端尾部,Right-front标记队列的右端头部,Right-rear标记队列的右端尾部,当需要进行删除或者插入操作时可以选择在两端进行。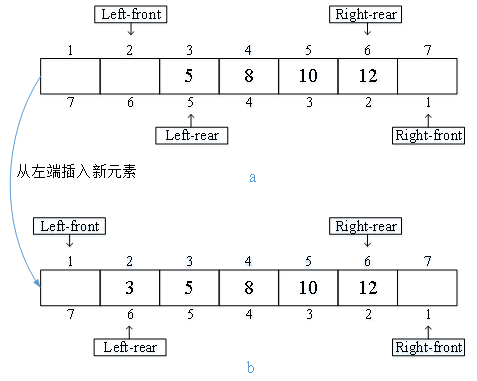

3.5.2 算法实现
首先给出Python版本的Deque Label Correcting Algorithm实现(求解附录2中源节点1到其他节点的最短路径)。"""导入相关基础包,定义全局变量"""import pandas as pdimport numpy as npimport copy
g_node_list=[] #网络节点集合
g_node_zone={} #网络节点类别集合
g_link_list=[] #网络弧集合
g_adjacent_arc_list={}#节点邻接弧集合(从节点i发出的弧集合)
g_shortest_path=[]#最短路径集合
g_node_status=[]#网络节点状态
g_number_of_nodes=0#网络节点个数
g_origin=None #网络源节点
node_predecessor=[]#前向节点集合
node_label_cost=[]#距离标签集合
SE_LIST=[]#可扫描节点集合
Max_label_cost=99999#初始距离标签"""导入网络数据文件,构建基础网络并初始化相关变量"""#读取网络节点数据
df_node=pd.read_csv('./input_file/node.csv')
df_node=df_node.iloc[:,:].valuesfor i in range(len(df_node)):
g_node_list.append(df_node[i,0])
g_node_zone[df_node[i, 0]] = df_node[i, -1]
g_number_of_nodes+=1
g_adjacent_arc_list[df_node[i,0]]=[]if df_node[i, 3] == 1:
g_origin = df_node[i, 0]
g_node_status=[0 for i in range(g_number_of_nodes)] #初始化网络节点状态
Distance=np.ones((g_number_of_nodes,g_number_of_nodes))\
*Max_label_cost #距离矩阵
node_predecessor=[-1]*g_number_of_nodes
node_label_cost=[Max_label_cost]*g_number_of_nodes
node_predecessor[g_origin-1]=0
node_label_cost[g_origin-1] = 0#读取网络弧数据
df_link=pd.read_csv('./input_file/road_link.csv')
df_link=df_link.iloc[:,:].valuesfor i in range(len(df_link)):
g_link_list.append((df_link[i,1],df_link[i,2]))
Distance[df_link[i,1]-1,df_link[i,2]-1]=df_link[i,3]
g_adjacent_arc_list[df_link[i,1]].append(df_link[i,2])
SE_LIST=[g_origin]
g_node_status[g_origin-1]=1"""最短路径求解:扫描网络弧,依据检查最优性条件更新距离标签"""while len(SE_LIST):
head=SE_LIST[0]#从可扫描列表中取出第一个元素
SE_LIST.pop(0)#从可扫描列表中删除第一个元素
g_node_status[head-1]=0
adjacent_arc_list=g_adjacent_arc_list[head]#获取当前节点的邻接弧集合for tail in adjacent_arc_list:if node_label_cost[tail-1]>\
node_label_cost[head-1]+Distance[head-1,tail-1]:
node_label_cost[tail-1]=\
node_label_cost[head-1]+Distance[head-1,tail-1]
node_predecessor[tail-1]=headif g_node_status[tail-1]==0:
SE_LIST.append(tail)#将新节点添加到可扫描列表尾部,append方法实现从列表尾部添加元素
g_node_status[tail-1]=1"""依据前向节点生成最短路径"""
agent_id=1
o_zone_id=g_node_zone[g_origin]for destination in g_node_list:if g_origin!=destination:
d_zone_id=g_node_zone[destination]if node_label_cost[destination-1]==Max_label_cost:
path=" "
g_shortest_path.append([agent_id, o_zone_id,d_zone_id,path, node_label_cost[destination - 1]])else:
to_node=copy.copy(destination)
path= "%s" % to_nodewhile node_predecessor[to_node-1]!=g_origin:
path="%s;"% node_predecessor[to_node - 1] + path
g=node_predecessor[to_node-1]
to_node=g
path="%s;"%g_origin+path
g_shortest_path.append([agent_id, o_zone_id,d_zone_id,path, node_label_cost[destination - 1]])
agent_id+=1"""将求解结果导出到csv文件"""#将数据转换为DataFrame格式方便导出csv文件
g_shortest_path=np.array(g_shortest_path)
col=['agent_id','o_zone_id','d_zone_id','node_sequence','distance']
file_data = pd.DataFrame(g_shortest_path, index=range(len(g_shortest_path)),columns=col)
file_data.to_csv('./3_fifo_label_correcting/agent.csv',index=False)%% clear
clc
clear
%% 设置变量
g_node_list = []; %网络节点集合
g_link_list = []; %网络弧集合
g_origin = []; %网络源节点
g_number_of_nodes = 0;%网络节点个数
node_predecessor = [];%前向节点集合
node_label_cost = [];%距离标签集合
Max_label_cost = inf; %初始距离标签
g_adjacent_arc_list={}; %节点邻接弧集合(从节点i发出的弧集合)
g_node_status=[]; %网络节点状态
SE_LIST=[]; %可扫描节点集合
%% 导入网络数据文件,构建基础网络并初始化相关变量
%读取网络节点数据
df_node = csvread('node.csv',1,0);
g_number_of_nodes = size(df_node,1);
g_node_list = df_node(:,1);
g_node_status = zeros(1,g_number_of_nodes);
for i = 1 : g_number_of_nodes
if df_node(i,4)==1
g_origin=df_node(i,1);
o_zone_id = df_node(i,5);
end
end
Distance = ones(g_number_of_nodes,g_number_of_nodes)*Max_label_cost;
%距离矩阵
node_predecessor = -1*ones(1,g_number_of_nodes);
node_label_cost = Max_label_cost*ones(1,g_number_of_nodes);
node_predecessor(1,g_origin) = 0;
node_label_cost(1,g_origin) = 0;
g_adjacent_arc_list = cell(1, g_number_of_nodes);
%读取网络弧数据
df_link = csvread('road_link.csv',1,0);
g_link_list = df_link(:,2:3);
for i = 1 : size(df_link, 1)
Distance(df_link(i,2),df_link(i,3)) = df_link(i,4);
g_adjacent_arc_list{df_link(i,2)} = [g_adjacent_arc_list{df_link(i,2)}, df_link(i,3)];
end
%% 最短路径求解:扫描网络弧,依据检查最优性条件更新距离标签
SE_LIST=[g_origin];
g_node_status(g_origin)=1;
while ~isempty(SE_LIST)
head=SE_LIST(1); %从可扫描列表中取出第一个元素
SE_LIST(1)=[]; %从可扫描列表中删除第一个元素
g_node_status(head) = 2;
adjacent_arc_list = g_adjacent_arc_list(head);
%获取当前节点的邻接弧
adjacent_arc_list = cell2mat(adjacent_arc_list);
for i = 1 : length(adjacent_arc_list)
tail = adjacent_arc_list(i);
if node_label_cost(tail)>…
node_label_cost(head)+Distance(head,tail)
node_label_cost(tail)=…
node_label_cost(head)+Distance(head,tail);
node_predecessor(tail)=head;
if g_node_status(tail)==0
SE_LIST = [SE_LIST, tail];
g_node_status(tail) = 1;
elseif g_node_status(tail) == 2
SE_LIST = [tail, SE_LIST];
g_node_status(tail) = 1;
end
end
end
end
%% 依据前向节点生成最短路径
destination_column = [];
distance_column = [];
path_column = {};
o_zone_id_column = o_zone_id * ones(g_number_of_nodes-1, 1);
d_zone_id_column = [];
agent_id_column = [1:(g_number_of_nodes-1)]';
for i = 1: size(g_node_list, 1)
destination = g_node_list(i);
if g_origin ~= destination
destination_column = [destination_column; destination];
d_zone_id_column = [d_zone_id_column; df_node(i,5)];
if node_label_cost(destination)==Max_label_cost
path="";
distance = 99999;
distance_column = [distance_column; 99999];else
to_node=destination;
path=num2str(to_node);
while node_predecessor(to_node)~=g_origin
path=strcat(';',path);
path=strcat(num2str(node_predecessor(to_node)),path);
g=node_predecessor(to_node);
to_node=g;
end
path=strcat(';',path);
path=strcat(num2str(g_origin),path);
distance_column = [distance_column; node_label_cost(i)];
end
path_column=[path_column;path];
end
end
title = {'agent_id','o_zone_id','d_zone_id','node_sequence','distance'};
result_table=table(agent_id_column,o_zone_id_column,…
d_zone_id_column,path_column,distance_column,'VariableNames',title);
writetable(result_table, 'agent.csv',…
'Delimiter',',','QuoteStrings',true)欲下载本文代码资料,请移步留言区
周学松教授 是亚利桑那州立大学(ASU)可持续工程与建筑环境学院教授,目前是Transportation Research Part C的副主编,城市轨道交通urbanrail transit 执行主编,Transportation Research Part B的编委。主要研究大规模多模式交通系统优化和仿真算法。 文案&编辑: 崔赞扬、李崇楠(北京交通大学) 审稿人: 邓发珩、周航、向柯玮(华中科技大学管理学院) 指导老师: 周学松(Arizona State University) 如对文中内容有疑问,欢迎交流。(PS:部分资料来自网络) 如有需求,可以联系: 崔赞扬(北京交通大学博士:dr.zanyang@bjtu.edu.cn) 李崇楠(北京交通大学本科:chongnanli1997@hotmail.com) 周学松(Arizona State University Professor: xzhou74@asu.edu) 邓发珩(华中科技大学本科三年级: 2638512393@qq.com、个人公众号:程序猿声) 周航(华中科技大学本科一年级:zh20010728@126.com) 向柯玮(华中科技大学本科一年级:2562599523@qq.com) 排版: 程欣悦(1293900389@qq.com)














 1467
1467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









